このブログは、株式会社フィックスターズのエンジニアが、あらゆるテーマについて自由に書いているブログです。
CUDAによるバンディング低減フィルタの高速化(2)
前回の続きです。メモリアクセス周りをもう少し見てみましょう。
カーネル内でメモリアクセスしてるデータは、乱数表と入出力画像です。このうち、読み書きデータ量の多い入出力画像を見てみます。画像のデータ型はPIXEL_YCです。これはAviUtlのフィルタ処理におけるデータ型で、以下のように定義されています。
typedef struct {
short y;
short cb;
short cr;
} PIXEL_YC;画像データはこれの配列なので、構造体の配列(Array of Structures, AoS)です。AoSはCUDAが苦手なデータ構造です。なぜならコアレスアクセスができないからです。本来、教科書通りのやり方なら、ここでAoSをSoA(Structure of Arrays)に変更することになりますが、それだとコード変更が多くなるので、ここではもっと簡単なやり方で最適化してみます。
まず、AoSだとなぜダメなのか、見てみましょう。コード中でのアクセスは以下のようになっています。(デフォルト値sample_mode==1の場合)
PIXEL_YC ref_p = src[offset + ref];
PIXEL_YC ref_m = src[offset - ref];構造体1個分をまとめて1行で読んでいます。実は、CUDAがこの構造体1個分をまとめて読み込んでくれれば、パフォーマンスロスは発生しません。しかし、実際にはまとめて読み込んでくれません。これはNVCCコンパイラから出力されるPTXコードを見れば分かります。
...
ld.global.nc.u16 %rs3, [%r65];
ld.global.nc.u16 %rs4, [%r65+2];
ld.global.nc.u16 %rs5, [%r65+4];
cvt.s32.s16 %r69, %rs3;
ld.global.nc.u16 %rs6, [%r68];
ld.global.nc.u16 %rs7, [%r68+2];
ld.global.nc.u16 %rs8, [%r68+4];
...命令レベルで見たら、まぁそうなるよね、という感じでしょうか。
しかし、実はCUDAには、2要素、4要素をまとめて読み込む命令があります。CUDAの組み込み型short2やshort4を使うと、まとめて読み込む命令を吐いてくれます。ここではshort4を使って、まとめて読み込めるようにコードを変更してみます。short4は、名前から想像できると思いますが、4要素のshort型を持った型です。PIXEL_YCは3要素なので、ちょっとデータ構造の変更が必要です。short4で読み込めるように、以下のようなPIXEL_YCAというのを導入します。
struct PIXEL_YCA {
short y;
short cb;
short cr;
short a; // 使用しない
};y,cb,crの値はPIXEL_YCからコピーして最後の要素aは使用しません。データ量が4/3に増えるのがデメリットとしてあります。これを処理するカーネルは、PIXEL_YCをshort4に置換すれば完成です。
template <int sample_mode, bool blur_first>
__global__ void kl_reduce_banding(BandingParam prm,
short4* __restrict__ dst,
const short4* __restrict__ src,
const uint8_t* __restrict__ rand)
{
…
}これで、このカーネルの実行時間を測ると、以下のようになります。
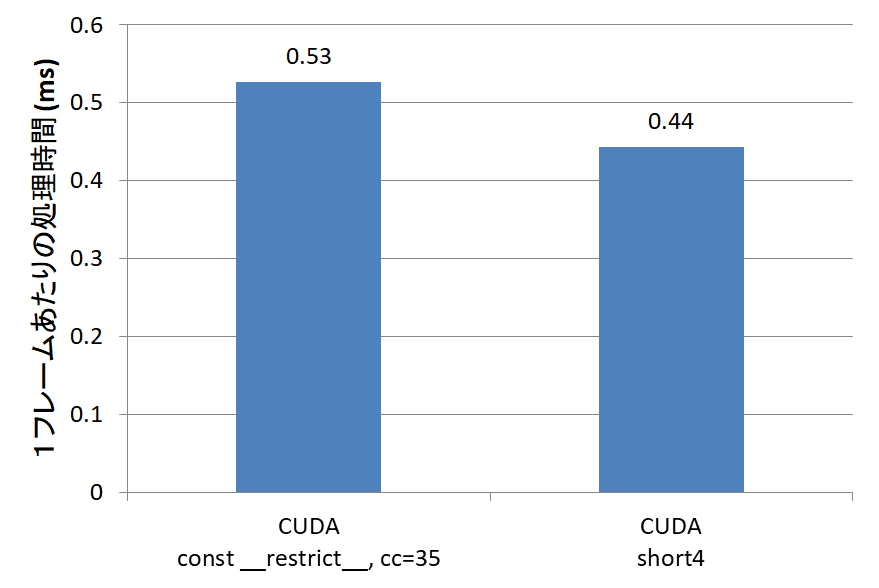
劇的という訳ではありませんが、20%程高速化しました。読み書きデータ量が4/3に増えているにもかかわらず、こちらの方が速いようです。4要素をまとめて読み込んでくれていることは、PTXで確認できます。
ld.global.nc.v4.u16 {%rs3, %rs4, %rs5, %rs6}, [%r65];
cvt.s32.s16 %r69, %rs3;
ld.global.nc.v4.u16 {%rs10, %rs11, %rs12, %rs13}, [%r68];実は、short3という組み込み型もあり、今回のPIXEL_YC構造体は3要素なので、short3だとピッタリフィットするのですが、short3だと速くなりません。
template <int sample_mode, bool blur_first>
__global__ void kl_reduce_banding_short3(BandingParam prm,
short3* __restrict__ dst,
const short3* __restrict__ src,
const uint8_t* __restrict__ rand)
{
…
}また、short4を使わないでPIXEL_YCAのままアクセスしても、今回の場合は速くなりませんでした。
template <int sample_mode, bool blur_first>
__global__ void kl_reduce_banding_YCA(BandingParam prm,
PIXEL_YCA* __restrict__ dst,
const PIXEL_YCA* __restrict__ src,
const uint8_t* __restrict__ rand)
{
…
}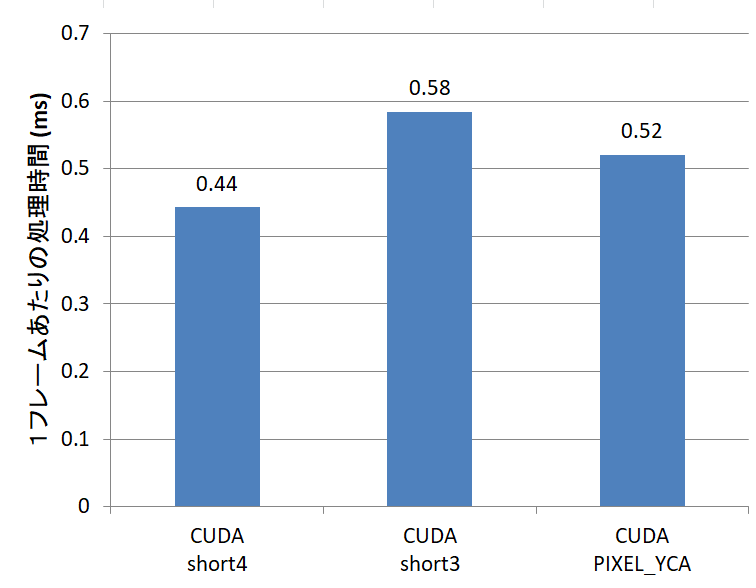
どちらも、PTXを見ると、各short要素を1つずつ読んでいました。short3は3要素を読み込む命令がないためと考えられます。PIXEL_YCA経由アクセスの場合は、アラインメントが保証できないからでしょう。short4で読み込む場合、データが2×4=8バイトにアラインしていないといけませんが、PIXEL_YCAが型としては8バイトアラインになっていないからです。
というわけで、今回、2回に分けて、バンディング低減フィルタのCUDA化と高速化を行いました。CUDAは、元がGPUなだけあって画像処理との相性は良く、今回のように割りと簡単にCUDA化できるものは多いです。

Tags
About Author
Koji Ueno
Leave a Comment
Tags
Favorite Post

 2017年8月22日
2017年8月22日 2017年10月31日
2017年10月31日
Archives
- 2024年2月
- 2024年1月
- 2023年12月
- 2023年6月
- 2023年5月
- 2023年4月
- 2023年2月
- 2023年1月
- 2022年12月
- 2022年10月
- 2021年11月
- 2021年9月
- 2021年6月
- 2021年3月
- 2021年2月
- 2020年12月
- 2020年10月
- 2020年7月
- 2020年6月
- 2020年5月
- 2020年4月
- 2020年3月
- 2020年2月
- 2020年1月
- 2019年12月
- 2019年11月
- 2019年10月
- 2019年9月
- 2019年8月
- 2019年6月
- 2019年4月
- 2019年3月
- 2019年2月
- 2019年1月
- 2018年12月
- 2018年11月
- 2018年10月
- 2018年8月
- 2018年6月
- 2018年5月
- 2018年4月
- 2018年3月
- 2018年2月
- 2017年12月
- 2017年11月
- 2017年10月
- 2017年9月
- 2017年8月
- 2017年7月
- 2017年6月
- 2017年5月
- 2017年3月
- 2016年12月
- 2016年11月
- 2016年8月
- 2016年7月
- 2016年3月
- 2016年2月
- 2016年1月
- 2015年12月
- 2015年11月
- 2015年10月
- 2015年8月
- 2015年6月
- 2015年3月
- 2015年2月
- 2015年1月
- 2014年12月
- 2014年11月
コンピュータビジョンセミナーvol.2 開催のお知らせ - ニュース一覧 - 株式会社フィックスターズ in Realizing Self-Driving Cars with General-Purpose Processors 日本語版
[…] バージョンアップに伴い、オンラインセミナーを開催します。 本セミナーでは、�...
【Docker】NVIDIA SDK Managerでエラー無く環境構築する【Jetson】 | マサキノート in NVIDIA SDK Manager on Dockerで快適なJetsonライフ
[…] 参考:https://proc-cpuinfo.fixstars.com/2019/06/nvidia-sdk-manager-on-docker/ […]...
Windowsカーネルドライバを自作してWinDbgで解析してみる① - かえるのほんだな in Windowsデバイスドライバの基本動作を確認する (1)
[…] 参考:Windowsデバイスドライバの基本動作を確認する (1) - Fixstars Tech Blog /proc/cpuinfo ...
2021年版G検定チートシート | エビワークス in ニューラルネットの共通フォーマット対決! NNEF vs ONNX
[…] ONNX(オニキス):Open Neural Network Exchange formatフレームワーク間のモデル変換ツー�...
YOSHIFUJI Naoki in CUDAデバイスメモリもスマートポインタで管理したい
ありがとうございます。別に型にこだわる必要がないので、ユニバーサル参照を受けるよ...