このブログは、株式会社フィックスターズのエンジニアが、あらゆるテーマについて自由に書いているブログです。
ニューラルネットの共通フォーマット対決! NNEF vs ONNX
遠藤です。
ニューラルネット界隈では、Caffe、TensorFlow、Chainer をはじめ、数々のフレームワークが群雄割拠の様相を呈しております。弊社でも、プロジェクトに応じて適宜フレームワークを使い分け、日々の業務にあたっております。
多数のフレームワークを扱っていると「あっちのフレームワークで学習したモデルを、こっちのフレームワークで使いたい!」といった、フレームワーク間をまたいでモデルを共有したいというニーズが出てきます。そのために、フレームワーク間で共通して使える交換フォーマットが開発されるようになりました。
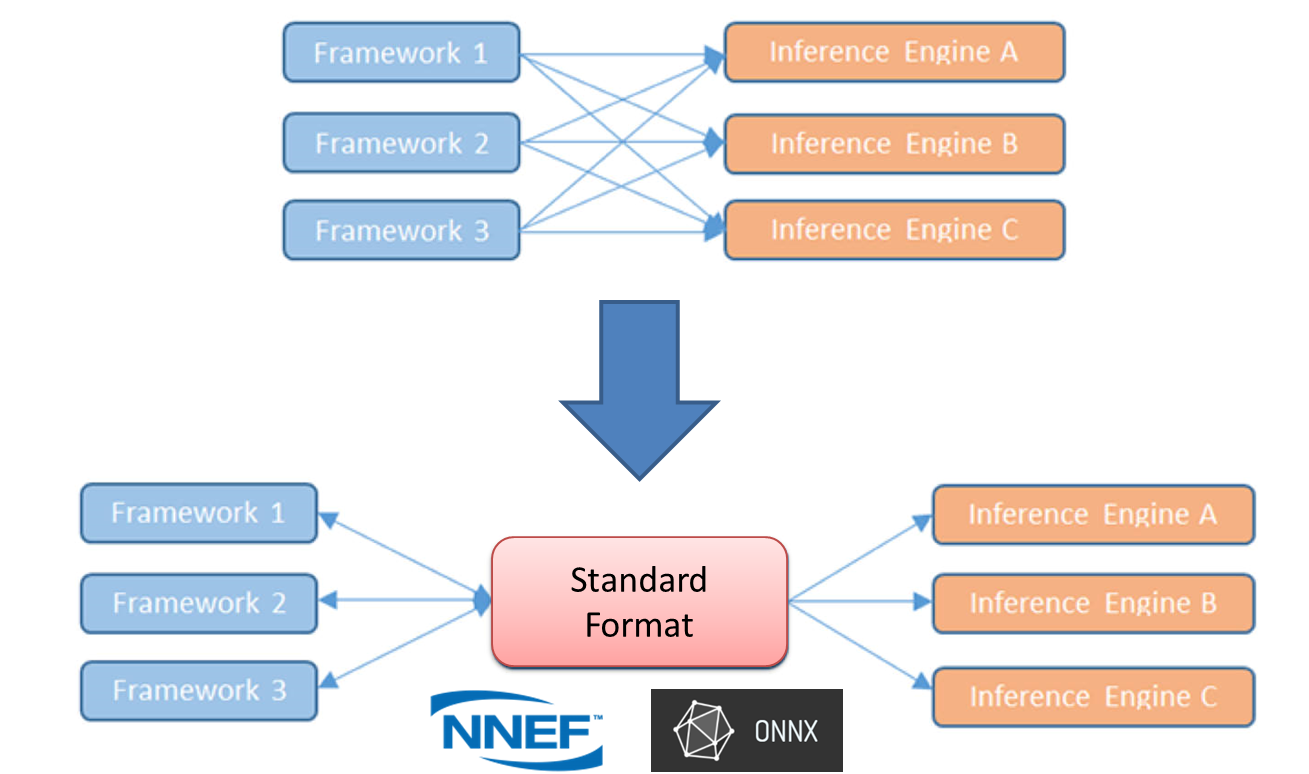
そこで、今回はニューラルネットの共通フォーマットとして NNEF と ONNX の2つをご紹介したいと思います。
NNEF とは?
概要
NNEF – Neural Network Exchange Format (NNEF)
The goal of NNEF is to enable data scientists and engineers to easily transfer trained networks from their chosen training framework into a wide variety of inference engines.
NNEF は、Khronos Group が発表した交換フレームワークです。Khronos Group といえば、弊社ともかかわりが深い OpenCL などの開発元であります。
NNEFでは、ネットワークはテキストとして、重みはバイナリファイルとしてそれぞれ表現されます。例えば、 NNEF のドキュメントによると AlexNet は次のようなテキストで表現されます。
graph AlexNet( input ) -> ( output )
{
input = external(shape = [1, 3, 224, 224])
kernel1 = variable(shape = [64, 3, 11, 11], label = 'alexnet_v2/conv1/kernel')
bias1 = variable(shape = [1, 64], label = 'alexnet_v2/conv1/bias')
conv1 = conv(input, kernel1, bias1, padding = [(0,0), (0,0)],
border = 'constant', stride = [4, 4], dilation = [1, 1])
relu1 = relu(conv1)
pool1 = max_pool(relu1, size = [1, 1, 3, 3], stride = [1, 1, 2, 2]),
border = 'ignore', padding = [(0,0), (0,0), (0,0), (0,0)])
kernel2 = variable(shape = [192, 64, 5, 5], label = 'alexnet_v2/conv2/kernel')
bias2 = variable(shape = [1, 192], label = 'alexnet_v2/conv2/bias')
conv2 = conv(pool1, kernel2, bias2, padding = [(2,2), (2,2)],
border = 'constant', stride = [1, 1], dilation = [1, 1])
relu2 = relu(conv2)
pool2 = max_pool(relu2, size = [1, 1, 3, 3], stride = [1, 1, 2, 2]),
border = 'ignore', padding = [(0,0), (0,0), (0,0), (0,0)])
kernel3 = variable(shape = [384, 192, 3, 3], label = 'alexnet_v2/conv3/kernel')
bias3 = variable(shape = [1, 384], label = 'alexnet_v2/conv3/bias')
conv3 = conv(pool2, kernel3, bias3, padding = [(1,1), (1,1)],
border = 'constant', stride = [1, 1], dilation = [1, 1])
relu3 = relu(conv3)
kernel4 = variable(shape = [384, 384, 3, 3], label = 'alexnet_v2/conv4/kernel')
bias4 = variable(shape = [1, 384], label = 'alexnet_v2/conv4/bias')
conv4 = conv(relu3, kernel4, bias4, padding = [(1,1), (1,1)],
border = 'constant', stride = [1, 1], dilation = [1, 1]))
relu4 = relu(conv4)
kernel5 = variable(shape = [256, 384, 3, 3], label = 'alexnet_v2/conv5/kernel')
bias5 = variable(shape = [1, 256], label = 'alexnet_v2/conv5/bias')
conv5 = conv(relu4, kernel5, bias5, padding = [(1,1), (1,1)],
border = 'constant', stride = [1, 1], dilation = [1, 1])
relu5 = relu(conv5)
pool3 = max_pool(relu5, size = [1, 1, 3, 3], stride = [1, 1, 2, 2]),
border = 'ignore', padding = [(0,0), (0,0), (0,0), (0,0)])
kernel6 = variable(shape = [4096, 256, 5, 5], label = 'alexnet_v2/fc6/kernel')
bias6 = variable(shape = [1, 4096], label = 'alexnet_v2/fc6/bias')
conv6 = conv(pool3, kernel6, bias6, padding = [(0,0), (0,0)],
border = 'constant', stride = [1, 1], dilation = [1, 1])
relu6 = relu(conv6)
kernel7 = variable(shape = [4096, 4096, 1, 1], label = 'alexnet_v2/fc7/kernel')
bias7 = variable(shape = [1, 4096], label = 'alexnet_v2/fc7/bias')
conv7 = conv(relu6, kernel7, bias7, padding = [(0,0), (0,0)],
border = 'constant', stride = [1, 1], dilation = [1, 1])
relu7 = relu(conv7)
kernel8 = variable(shape = [1000, 4096, 1, 1], label = 'alexnet_v2/fc8/kernel')
bias8 = variable(shape = [1, 1000], label = 'alexnet_v2/fc8/bias')
conv8 = conv(relu7, kernel8, bias8, padding = [(0,0), (0,0)],
border = 'constant', stride = [1, 1], dilation = [1, 1])
output = softmax(conv8)
特徴
NNEFの特徴は「ネットワークの表現力」です。これは、ネットワーク構造と、量子化の2つの面でいうことができます。
まず、ネットワーク構造における表現力について説明します。これは、あるまとまった単位のネットワークを “fragment” として定義し、fragment を組み合わせることでより大きなネットワークを表現できるということです。例えば GoogLeNet を例にとると、inception モジュールというネットワークの単位があり、それを複数個つなげることで、階層的で複雑なネットワークが構成されています。Caffe 等でネットワークを表現する場合は、inception モジュールは展開され階層のないフラットなネットワークとして表現されます。NNEF を使うと、inception モジュールの階層性を残したまま、わかりやすいネットワークの表現が可能です。これは、Chainer 等のフレームワークにおけるネットワーク表現のわかりやすさと似ていると考えられます。
次に、量子化における表現力について説明します。ネットワークをエッジ側で動かす際には、INT8 や FP16 のようにビット幅を減らし量子化することがあります。普通は重みもそれに合わせて量子化したものを保存するのですが、NNEF では表現方法が違います。何故かというと、NNEF はプラットフォーム非依存の表現を目指しており、量子化した生データといったプラットフォーム依存の表現をそのまま入れたくないという事情があるからです。そこで、NNEFでは以下に示すように、量子化を実数を入力とする数式として表現しています。ドキュメントには線形量子化と対数量子化の2種類が定義されていますが、それ以外の量子化もやろうと思えば fragment として定義することができるのではないかと思います。
fragment linear_quantize( x: tensor, min: tensor, max: tensor, bits: extent )
-> ( y: tensor )
{
z = clamp(x, min, max)
r = scalar(2 ^ bits - 1) / (max - min)
y = round((z - min) * r) / r + min
}
fragment logarithmic_quantize( x: tensor, max: tensor, bits: extent )
-> ( y: tensor )
{
amax = 2.0 ^ ceil(log2(max))
amin = 2.0 ^ (log2(amax) - scalar(bits))
z = clamp(x, amin, amax)
y = 2.0 ^ round(log2(z / amin))
}サポート状況
本記事の執筆時点では、 Caffe と TensorFlow から NNEF へのコンバータが公式の GitHub に公開されています。残念ながら、それ以外のフレームワークからのコンバータは現時点では公開されていません。
また、NNEF をインポートして推論を行うソフトウェアも、現時点では公開されていませんでした。
ONNX とは?
概要
ONNX: Open Neural Network Exchange Format
The new open ecosystem for interchangeable AI models
ONNX は、Facebook などが中心となって開発し現在はオープンに公開されているネットワーク交換フォーマットです。元々は Caffe2 と PyTorch 間でのモデルの交換を意図して開発されたもののようです。現在は、より多くのフレームワークが ONNX をサポートしています。
NNEF がテキストベースでネットワークを記述するのに対し、ONNX は単一のバイナリファイルでネットワークとパラメータを表現します。
特徴
ONNX の特徴は、仕様がシンプルであるという点です。NNEF では階層的なネットワーク記述を許していた一方で、ONNX では階層を持たないフラットなネットワーク記述となっています。また、量子化についても量子化済みの重みがそのまま記述されるような仕組みとなっています。NNEF と比べると表現力は劣りますが、その分シンプルな仕様にまとまっています。
また、データのバイナリ化には Caffe や Tensorflow 等と同じく Protocol Buffer 形式を採用している点も特徴です。既存のフレームワークと共通のライブラリを使うことで、ONNX の対応コストを下げる効果がありそうです。
これらは、フレームワーク間でのモデルのやり取りをやるために必要十分なものを作ろうという点で、NNEF とは設計思想の違いを感じます。
サポート状況
ONNX は、様々なフレームワークでサポートされています。公式のドキュメントで公開されているものは以下のとおりです。
- ONNX モデルへの変換 (エクスポート)
- Caffe2
- PyTorch
- CNTK
- Chainer
- ONNX モデルを用いた推論 (インポート)
- Caffe2
- CNTK
- MXNet
- TensorFlow
- Apple CoreML
- TensorRT (ただしサンプルコードが未公開)
NNEF と ONNX の違いは?
NNEF と ONNF の違いを表にまとめてみました。
| Format | Pros | Cons |
|---|---|---|
| NNEF |
|
|
| ONNX |
|
|
結局どちらを使えばいい?
本記事執筆時点では、NNEF はサポート状況が弱いため、実質的な選択肢は ONNX のみです。しかし、NNEF は現在開発中のステータスであり、今後サポートされるフレームワーク等が増えていくことが予想されます。
ニューラルネットワークのフレームワークだけでなく、今後はファイルフォーマットでも競争が起こっていきそうです。究極のメニューと至高のメニューのように双方がしのぎを削り、より使いやすく、より広く使うことのできる共通フォーマットへと成長していくことを見守っていきたいと思います。
次は、実際に ONNF を用いてモデルをやり取りしてみるコードを実際に書いて、動作を確かめてみたいと思います。

Tags
About Author
yasunori.endo
1件のコメント
Leave a Comment
Tags
Favorite Post

 2023年1月27日
2023年1月27日 2017年8月22日
2017年8月22日
Archives
- 2025年5月
- 2025年4月
- 2024年11月
- 2024年10月
- 2024年7月
- 2024年5月
- 2024年4月
- 2024年2月
- 2024年1月
- 2023年12月
- 2023年6月
- 2023年5月
- 2023年4月
- 2023年2月
- 2023年1月
- 2022年12月
- 2022年10月
- 2021年11月
- 2021年9月
- 2021年6月
- 2021年3月
- 2021年2月
- 2020年12月
- 2020年10月
- 2020年7月
- 2020年6月
- 2020年5月
- 2020年4月
- 2020年3月
- 2020年2月
- 2020年1月
- 2019年12月
- 2019年11月
- 2019年10月
- 2019年9月
- 2019年8月
- 2019年6月
- 2019年4月
- 2019年3月
- 2019年2月
- 2019年1月
- 2018年12月
- 2018年11月
- 2018年10月
- 2018年8月
- 2018年6月
- 2018年5月
- 2018年4月
- 2018年3月
- 2018年2月
- 2017年12月
- 2017年11月
- 2017年10月
- 2017年9月
- 2017年8月
- 2017年7月
- 2017年6月
- 2017年5月
- 2017年3月
- 2016年12月
- 2016年11月
- 2016年8月
- 2016年7月
- 2016年3月
- 2016年2月
- 2016年1月
- 2015年12月
- 2015年11月
- 2015年10月
- 2015年8月
- 2015年6月
- 2015年3月
- 2015年2月
- 2015年1月
- 2014年12月
- 2014年11月
-
keisuke.kimura in Livox Mid-360をROS1/ROS2で動かしてみた
Sorry for the delay in replying. I have done SLAM (FAST_LIO) with Livox MID360, but for various reasons I have not be...
-
Miya in ウエハースケールエンジン向けSimulated Annealingを複数タイルによる並列化で実装しました
作成されたプロファイラがとても良さそうです :) ぜひ詳細を書いていただきたいです!...
-
Deivaprakash in Livox Mid-360をROS1/ROS2で動かしてみた
Hey guys myself deiva from India currently i am working in this Livox MID360 and eager to knwo whether you have done the...
-
岩崎システム設計 岩崎 満 in Alveo U50で10G Ethernetを試してみる
仕事の都合で、検索を行い、御社サイトにたどりつきました。 内容は大変参考になりま�...
-
Prabuddhi Wariyapperuma in Livox Mid-360をROS1/ROS2で動かしてみた
This issue was sorted....
[…] ONNX(オニキス):Open Neural Network Exchange formatフレームワーク間のモデル変換ツール /facebook […]