このブログは、株式会社フィックスターズのエンジニアが、あらゆるテーマについて自由に書いているブログです。
CUDAによるバンディング低減フィルタの高速化(1)
弊社のメインのお仕事はプログラムの高速化です。今日から数回の記事に分けて、画像処理フィルタのCUDAによる高速化をしてみたいと思います。
今回のお題は、AviUtlのフィルタプラグインの1つ、バンディング低減フィルタです。AviUtlはKENくん氏により開発されたフリーの動画編集ソフトウェアです。プラグインによる機能追加が可能な非常に柔軟なソフトウェアとなっております。バンディング低減フィルタもプラグインの1つで、今回ベースとしたソースコードbandingMT_simdは、がらくたハウスのがらくた置き場様にて公開されているプラグインを、rigaya氏がSIMDを使って高速化したバージョンです。マルチスレッドにおけるCPUキャッシュの利用を考えたタスク分配なども行っており、CPU向けにはほぼ限界までチューニングされています。そこで、ちょっと別の方向からの高速化ということで、今回はCUDAを使ってGPUで処理してみましょう。GPUは元々グラフィック処理に特化したハードウェアなので、画像処理フィルタとの相性は抜群です。期待できます。
以下、高速化する過程を順に説明していきますが、最終版のコードを置いておきます。(readme.mdの説明はfork元のrigaya氏のものです。)
https://github.com/koji123/bandingMT_simd
まず、コードを見てます。SIMD版の関数がたくさんありますが、元のコードは banding_func.cpp の decrease_banding_mode0_c() と decrease_banding_mode12_c() です。SIMD版はこれと等価な処理をしているはずなので、とりあえずこの2つの関数だけ見ればいいでしょう。さて、どちらもxとyの2重ループになっています。
for (int y = y_start; y < y_end; y++) {
...
for (int x = 0; x < width; x++, ycp_src++, ycp_dst++) {
...
}
}画像処理ではよくあるパターンです。これは簡単にCUDA化できそう。ただし、よく見ると、乱数の生成部分でイテレーション間の依存関係があるようです。
xor128(&gen_rand);イテレーション間の依存関係はCUDA化における大敵。どうにか除去しなければなりません。幸い今回の場合は、乱数の取得ができればいいので、全ピクセル分の乱数を、事前にCPU側で生成しておいて、生成した乱数表を、CUDAカーネルからを読むという実装で解決できるでしょう。
他に問題として、AviUtl本体から渡される構造体 FILTER* fp, FILTER_PROC_INFO *fpip にアクセスしていますが、この部分は、必要なパラメータだけ構造体にまとめて、CUDAカーネルに渡してやります。
以上のことをやって、CUDA化したコードが以下の通り。
template <int sample_mode, bool blur_first>
__global__ void kl_reduce_banding_naive(
BandingParam prm, PIXEL_YC* dst, const PIXEL_YC* src, const uint8_t* rand)
{
const int ditherY = prm.ditherY;
const int ditherC = prm.ditherC;
const int pitch = prm.pitch;
const int width = prm.width;
const int height = prm.height;
const int range = prm.range;
const int threshold_y = prm.threshold_y;
const int threshold_cb = prm.threshold_cb;
const int threshold_cr = prm.threshold_cr;
const int field_mask = prm.interlaced ? 0xfe : 0xff;
const int x = blockIdx.x * blockDim.x + threadIdx.x;
const int y = blockIdx.y * blockDim.y + threadIdx.y;
const int rand_step = width * height;
const int offset = y * pitch + x;
if (x < width && y < height) {
const int range_limited = get_min(range,
get_min(y, height - y - 1, x, width - x - 1));
const char refA = random_range(rand[offset + rand_step * 0], range_limited);
const char refB = random_range(rand[offset + rand_step * 1], range_limited);
PIXEL_YC src_val = src[offset];
PIXEL_YC avg, diff;
if (sample_mode == 0) {
const int ref = (char)(refA & field_mask) * pitch + refB;
avg = src[offset + ref];
diff = get_abs_diff(src_val, avg);
}
else if (sample_mode == 1) {
const int ref = (char)(refA & field_mask) * pitch + refB;
PIXEL_YC ref_p = src[offset + ref];
PIXEL_YC ref_m = src[offset - ref];
avg = get_avg(ref_p, ref_m);
diff = blur_first
? get_abs_diff(src_val, avg)
: get_max(get_abs_diff(src_val, ref_p),
get_abs_diff(src_val, ref_m));
}
else {
const int ref_0 = (char)(refA & field_mask) * pitch + refB;
const int ref_1 = refA - (char)(refB & field_mask) * pitch;
PIXEL_YC ref_0p = src[offset + ref_0];
PIXEL_YC ref_0m = src[offset - ref_0];
PIXEL_YC ref_1p = src[offset + ref_1];
PIXEL_YC ref_1m = src[offset - ref_1];
avg = get_avg(ref_0p, ref_0m, ref_1p, ref_1m);
diff = blur_first
? get_abs_diff(src_val, avg)
: get_max(get_abs_diff(src_val, ref_0p),
get_abs_diff(src_val, ref_0m),
get_abs_diff(src_val, ref_1p),
get_abs_diff(src_val, ref_1m));
}
PIXEL_YC dst_val;
dst_val.y = (diff.y < threshold_y) ? avg.y : src_val.y;
dst_val.cb = (diff.cb < threshold_cb) ? avg.cb : src_val.cb;
dst_val.cr = (diff.cr < threshold_cr) ? avg.cr : src_val.cr;
dst_val.y += random_range(rand[offset + rand_step * 2], ditherY);
dst_val.cb += random_range(rand[offset + rand_step * 3], ditherC);
dst_val.cr += random_range(rand[offset + rand_step * 4], ditherC);
dst[offset] = dst_val;
}
}これの他に、乱数表の生成や、データのGPUへの転送、パラメータを作る部分などもありますが、長くなるので、CUDAカーネルだけ載せてます。元のCPU版は、decrease_banding_mode0_c() と decrease_banding_mode12_c() の2つの関数に分かれていましたが、CUDA版では kl_reduce_banding_naive() 1つにまとめています。一部のパラメータ(sample_mode,blur_first)がテンプレートパラメータとなっていますが、これはコンパイル時に条件分岐を消すためによくやる方法です。引数の rand で、事前に生成しておいた乱数表を入力してます。ほかはちょっと変数名を書き換えたくらいで、処理の流れはほぼ同じですね。
さて、これで性能を測ってみましょう。評価環境は以下の通り。
評価環境のPCスペック
| CPU | Core i7-6700 @ 3.40GHz |
| メモリ | DDR4 32GB |
| GPU | GeForce GTX 1060 6GB |
| OS | Windows 10 |
現在(2017年6月)の価格.com最安値がCPUが35,780円、GPUが27,980円でした。よくあるPC構成ですね。
計測は、FullHD(1920×1080)の画像を10フレーム分処理して、1フレームあたりの平均を算出しました。バンディング低減フィルタのパラメータはすべてデフォルト値です。CUDA版は、画像データ転送や、乱数の生成時間は含まず、パラメータの転送や、カーネルの実行時間のみです。
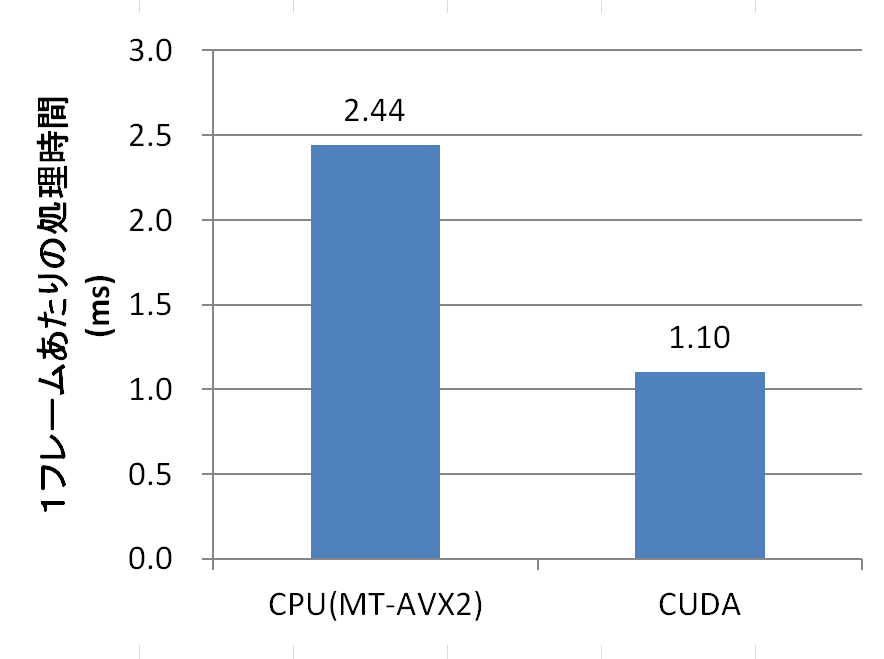
CUDA版はCPU版の2倍以上の速度になりました。CPU版がSIMDやマルチスレッドを使って実装されているので、開発にかかった時間を考えると、これだけ簡単に高速化できてしまうのですから、CUDA恐るべしです。
ただし、上のCUDA版の時間は、画像データの転送時間を含んでいません。AviUtl本体とやりとりするデータは全てCPU上にあるので、GPUで処理するには、GPUへ転送→カーネル実行→CPUへ転送という手順を踏まなければなりません。画像データの転送時間を含めると、CUDA版の実行時間は、8.27msになります。CPU版より遅くなっています。(ちなみに乱数の生成はシードが変わらない限り再生成する必要はないので、エンコード時の実行時間には影響しません。)残念ながら、現在のAviUtlのプラグインフィルタの仕様では、画像データの転送が必要であることから、CUDA化による高速化は難しいです。この問題については、後に、フィルタ処理のフルGPU化によって解決する予定です。フィルタの入出力データがGPU上にあれば、上記の速度で処理できるので、この速度に意味が無いわけではありません。
次に、このCUDAカーネルをもっと速くしてみましょう。改善すべき点は、メモリアクセスです。カーネル内でのメモリアクセスを見ると、まず(1)スレッドの担当する点(x,y)のピクセルを読んで
PIXEL_YC src_val = src[offset];次にsample_modeによって通るコードパスが分かれますが、sample_mode==1の場合は、(2)乱数で生成したアドレスのピクセル2点を読んでいます。
PIXEL_YC ref_p = src[offset + ref];
PIXEL_YC ref_m = src[offset - ref];そして、最後に(3)計算結果を書き込んでいます。
dst[offset] = dst_val;CUDAでメモリアクセスを効率化しようとすると、まずコアレスアクセスにするというのがあります。コアレスアクセスとは平たく言えば、CUDAブロックにおける隣のスレッドのアクセスするメモリと自分のアクセスするメモリがメモリ上で連続になるようにするということです(詳しく知りたい方はCUDAのドキュメントを読んでください)。隣のスレッドと言うのは、自分が(x,y)だとしたら(x-1,y)や(x+1,y)のこと。画像がモノクロ等、単一要素しかないデータなら、何も考えずに自分のスレッドの要素を読み出せば、コアレスアクセスとなります。しかし、このカーネルはどうでしょう。(1)と(3)は確かにとなりのスレッドと連続アドレスとなる場所を読み書きしていますが、PIXEL_YCはshort3要素のデータなので、実はこれ、コアレスアクセスとなるかは怪しいです。さらに(2)は乱数から生成したアドレスなのでコアレスアクセスとなるはずがありません。
ただし、(2)は乱数から生成した場所と言っても、スレッドの担当する点(x,y)からの距離は、パラメータrangeで指定された範囲内にあるはずなので、近い場所であることは確かです。こういう場合は、キャッシュが使えればアクセスは高速化されるはずです。CUDAのGPUにおけるキャッシュを見てみましょう。GPUの世代にもよりますが、よほど古いものでなければL1とL2があります。当然L1の方が速いです。ただし、L1にはキャッシュコヒーレンシを保つ機構がないため、通常のメモリアクセスは、L2までしかキャッシュされません。L2でもメモリより速いのは確かですが、せいぜいメモリより2~3倍速い程度で、L2の過信は禁物です。
キャッシュコヒーレンシのないL1はどうやって使うかというと、読み取り専用のデータに対しては使うことができます。具体的には、ポインタにconstと__restrict__という修飾子を付けてデータにアクセスします。この機能はRead-Only Data Cacheと言ってKepler世代のGK110コアから導入されたものです。カーネルの引数を以下のように書き換えます。
template <int sample_mode, bool blur_first>
__global__ void kl_reduce_banding_YC(BandingParam prm,
PIXEL_YC* __restrict__ dst,
const PIXEL_YC* __restrict__ src,
const uint8_t* __restrict__ rand)
{
…
}注意点として、compute capability(以下cc) 3.5で導入されたものなので、使用するGPUがcc 3.5以上でないと、Read-Only Data Cache (L1)は使えません。また、CUDAは、カーネルをコンパイルするときに、どのcompute capabilityのGPU向けにコンパイルするかをオプションで指定するのですが、これが3.5以上でないと、Read-Only Data Cacheから読み取る命令を生成してくれません。つまり、どんなに新しいGPUを使っていても、コンパイル時にターゲットとして指定したcompute capabilityが3.5より低いと、Read-Only Data Cacheは使ってくれないのです。
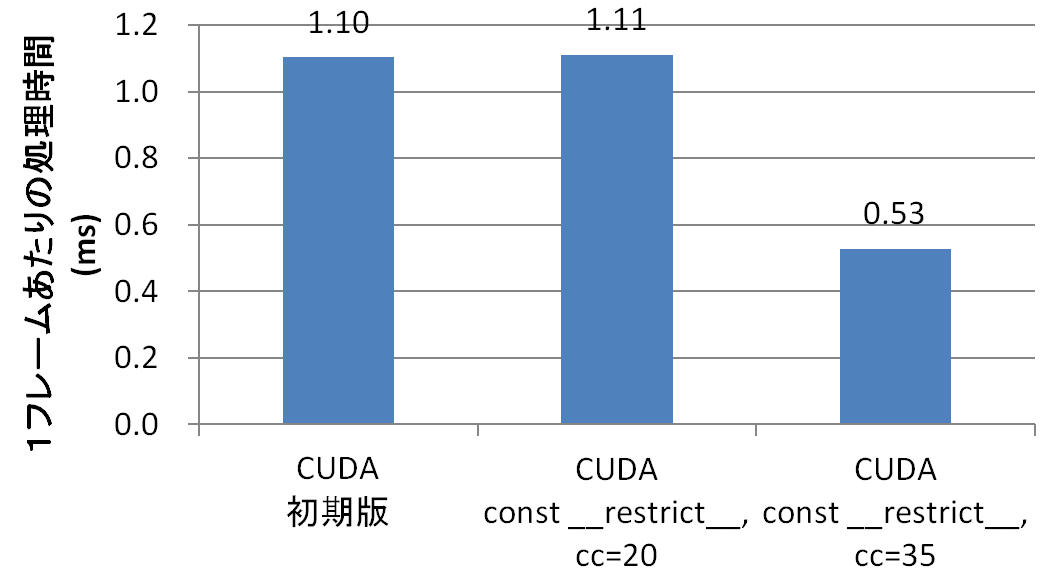
左が高速化前のCUDA版、真ん中がconst __restrict__は付けだが、compute capability 2.0でコンパイルしてしまったバージョン、右が、cc 3.5でコンパイルしたバージョンです。分かりやすく差が付いてますね。Read-Only Data Cacheを使うことで2倍速くなりました。cc 3.5より前のGPUのRead-Only Data Cacheに相当するキャッシュを使うには、データをテクスチャにしてアクセスする必要がありますが、結構大変なので、今回はそこまでやりません。
ここで、CUDAカーネルのコンパイルオプションについて少し解説しておきます。Visual Studioの場合は、.cuファイルやプロジェクトのプロパティからCUDAのコンパイルオプションを設定できます。Compute capabilityは CUDA C/C++ → Device → Code Generation で指定するのですが、デフォルト値は “compute_20,sm_20” となっています。computeとsmで、なんで2つあるの?って疑問に思うと思います。この2つはちょっと意味合いが異なります。
まず、CUDAのGPUというのは、compute capabilityによって、実行できる命令が違うので、実際にGPUでCUDAカーネルを実行する場合、compute capabilityごとにコンパイルしなければなりません。しかし、それでは、ビルドしたときより、新しいGPUが出現したときに、困ります。新しいGPUが出現したとき、開発者は毎回ビルドし直して、リリースし直すのでしょうか。そうではありません。CUDAプログラムは、特定のcompute capability向けにコンパイルされたネイティブアセンブリ(SASSと呼ばれる)の他に、PTXと呼ばれる、特定のハードウェアに依存しない、抽象化されたコードにもコンパイルされます。ビルド時にネイティブアセンブリを生成しなかったcompute capabilityのGPUで実行する場合は、実行時にPTXコードからコンパイルして実行するのです。この機能により、新しいGPUでも古いCUDAプログラムが動きます。
で、computeとsmの違いは、computeがPTXの生成、smがネイティブアセンブリ(SASS)の生成における、compute capabilityの指定なのです。ただし、PTXにより、ある程度の互換性が保たれると言っても、PTXがサポートしているのは、後方互換性のみです。例えば、compute_61でコンパイルしたCUDAプログラムはcc 5.0や3.5では動きません。そこで、通常、複数のcompute capabilityを指定します。例えば、以下のように。
compute_20,sm_20;compute_35,sm_35;compute_61,sm_61compute capabilityによって、使える機能が異なるので、使用される可能性のあるすべてのcompute capabilityを網羅すれば、性能は最も良くなるでしょう。しかし、ビルド時間とバイナリサイズが増えてしまう点は注意が必要です。
次回はさらに高速化してみます。

Tags
About Author
Koji Ueno
Leave a Comment
Tags
Favorite Post

 2023年1月27日
2023年1月27日 2017年8月22日
2017年8月22日
Archives
- 2025年5月
- 2025年4月
- 2024年11月
- 2024年10月
- 2024年7月
- 2024年5月
- 2024年4月
- 2024年2月
- 2024年1月
- 2023年12月
- 2023年6月
- 2023年5月
- 2023年4月
- 2023年2月
- 2023年1月
- 2022年12月
- 2022年10月
- 2021年11月
- 2021年9月
- 2021年6月
- 2021年3月
- 2021年2月
- 2020年12月
- 2020年10月
- 2020年7月
- 2020年6月
- 2020年5月
- 2020年4月
- 2020年3月
- 2020年2月
- 2020年1月
- 2019年12月
- 2019年11月
- 2019年10月
- 2019年9月
- 2019年8月
- 2019年6月
- 2019年4月
- 2019年3月
- 2019年2月
- 2019年1月
- 2018年12月
- 2018年11月
- 2018年10月
- 2018年8月
- 2018年6月
- 2018年5月
- 2018年4月
- 2018年3月
- 2018年2月
- 2017年12月
- 2017年11月
- 2017年10月
- 2017年9月
- 2017年8月
- 2017年7月
- 2017年6月
- 2017年5月
- 2017年3月
- 2016年12月
- 2016年11月
- 2016年8月
- 2016年7月
- 2016年3月
- 2016年2月
- 2016年1月
- 2015年12月
- 2015年11月
- 2015年10月
- 2015年8月
- 2015年6月
- 2015年3月
- 2015年2月
- 2015年1月
- 2014年12月
- 2014年11月
keisuke.kimura in Livox Mid-360をROS1/ROS2で動かしてみた
Sorry for the delay in replying. I have done SLAM (FAST_LIO) with Livox MID360, but for various reasons I have not be...
Miya in ウエハースケールエンジン向けSimulated Annealingを複数タイルによる並列化で実装しました
作成されたプロファイラがとても良さそうです :) ぜひ詳細を書いていただきたいです!...
Deivaprakash in Livox Mid-360をROS1/ROS2で動かしてみた
Hey guys myself deiva from India currently i am working in this Livox MID360 and eager to knwo whether you have done the...
岩崎システム設計 岩崎 満 in Alveo U50で10G Ethernetを試してみる
仕事の都合で、検索を行い、御社サイトにたどりつきました。 内容は大変参考になりま�...
Prabuddhi Wariyapperuma in Livox Mid-360をROS1/ROS2で動かしてみた
This issue was sorted....