このブログは、株式会社フィックスターズのエンジニアが、あらゆるテーマについて自由に書いているブログです。
ディリクレ過程混合モデルによるクラスタリングの振舞い方
前回の続きから
前回は、クラスタに所属するデータが正規分布であると仮定した場合の、具体的な計算手順を示したのでした。クラスタパラメータ $\boldsymbol{\theta}$ とは正規分布のパラメータ $(\boldsymbol{\mu}, \Lambda)$ のことであり、基底分布 $G_0$ は正規ウィシャート分布であるとしました。このモデルでクラスタリングを行うと、与えられたデータが正規分布に従うクラスタに分割された上、分割されたクラスタの平均、分散が得られます。
前回の記事で、以下↓のような記載をしましたが、
$p(\boldsymbol{\theta}_i | \boldsymbol{x}_{i1}, \boldsymbol{x}_{i2},…, \boldsymbol{x}_{in_i}) = N(\boldsymbol{\mu}_i; \boldsymbol{\mu}_c, \Lambda_c^{-1})W(\Lambda_i; \nu_c, S_q)$ となるわけですが、それでは一番出やすい $\boldsymbol{\mu}_i, \Lambda_i$ は何になるでしょうか?$N(\boldsymbol{\mu}; \boldsymbol{\mu}_0, \Lambda^{-1})$ に従う $\boldsymbol{\mu}$ の平均が $\boldsymbol{\mu}_0$ であること、$W(\Lambda; \nu, S)$ に従う $\Lambda$ の平均が ${\nu}S$ であることを考えると、$(\boldsymbol{\mu}_i, \Lambda_i)$ の最尤推定値は $(\boldsymbol{\mu}_c, {\nu_c}S_q)$ としてしまってよいと思います。ひょっとしたら厳密ではないかもしれませんが、今回の実験ではこうしました。
今回は改めました。クラスタを構成するサンプルデータの出入りがあった場合、ちゃんと正規分布、ウィシャート分布に従ってクラスタの平均、分散を計算します。python には、scipy.stats.multivariate_normal.rvs(), scipy.stats.wishart.rvs() といった正規分布、ウィシャート分布からデータを生成する関数があるので、python 実装であればこれをそのまま使えてしまいます。
ハイパーパラメータによる振る舞い変化
さて、「ディリクレ過程混合モデル + 正規ウィシャート分布を事前分布とするクラスタリング方法」では、あらかじめ値を決めておくべきハイパーパラメータがいくつかあります。
- $\alpha$
クラスタを分割しやすくさせるパラメータです。この値が大きいほど、クラスタが分割される方向に行きます。 - $\mu_0$
クラスタの平均に影響します。しかし、$\beta$ の値が小さいとほとんど影響しません。 - $\nu, S$
$\nu, S$ が大きいほど生成される各クラスタの分散が小さくなり、$\nu, S$ が小さいほど分散が大きくなります。分散が小さいということは、クラスタの範囲が狭いということです。つまり、$\nu, S$ が大きいとクラスタが分割されやすいということになります。逆に、分散が大きいということは、クラスタの範囲が広いということになるので、クラスタが分割されにくいということになります。ただし、所属するデータが多くなってくると効き方が弱くなってきます。 - $\beta$
各クラスタの平均にも、分散にも、分割されやすさにも影響します。ちょっと傾向がつかめません。(なので、今回の観察の対象外とします。$\beta = 0.1$ という小さな固定値を与えておきます。)
なんで、このような傾向になるのでしょうか?
これらのハイパーパラメータが出てくるところをもう一度見てみましょう。ギブスサンプリングの際、サンプルを一つ抜いて新しいクラスタに所属させるとき、以下の確率に従って所属させますが、この式にハイパーパラメータが入ってます。
$$p(s_k=i|\boldsymbol{\theta’}, \boldsymbol{s}_{-k}, \boldsymbol{x}) = C\frac{n_i’}{n – 1 + \alpha}N(\boldsymbol{x}_k; \boldsymbol{\mu}_i’, \Lambda_i’)\,(i = 1, 2, …, c) \\
p(s_k=new|\boldsymbol{\theta’}, \boldsymbol{s}_{-k}, \boldsymbol{x}) = C\frac{\alpha}{n – 1 + \alpha}(\frac{\beta}{(1 + \beta)\pi})^{d/2}\frac{|S_b|^{(\nu+1)/2}\Gamma(\frac{\nu+1}{2})}{|S|^{\nu/2}\Gamma(\frac{\nu + 1 – d}{2})} \\
S_b^{-1} = S^{-1} + \frac{\beta}{1 + \beta}(\boldsymbol{x}_k – \boldsymbol{\mu}_0)(\boldsymbol{x}_k – \boldsymbol{\mu}_0)^t$$
第 2 式は、既存のクラスタではない、そのデータ一つだけで構成される新しいクラスタを形成するときの確率です。これを見ると、$\alpha, \beta$ の値が小さいと、新しいクラスタが生まれにくいことが分かります。また、$|S_b|$ が小さいほど、もしくは $|S|$ が大きいほど、新しいクラスタが生まれにくことも分かります。新しいクラスタが生まれにくいとは、即ち、最終状態としてクラスタが分割されにくいことを意味します。$S_b$ と $S$ に関しては第3式の縛りがあるので、独立に動かせません。それでも、$\beta$ が小さい状況では $S_b \fallingdotseq S$ となり、第 2 式は $|S|^\frac{1}{2}$ に比例することになるので $|S|$ が大きくなればクラスタは分割されやすくなり、小さくなれば分割されにくくなると言えると思います。
次いで、各クラスタの平均、分散に関わる式も見てみます。
$$p(\boldsymbol{\theta}_i | \boldsymbol{x}_{i1}, \boldsymbol{x}_{i2},…, \boldsymbol{x}_{in_i}) = N(\boldsymbol{\mu}_i; \boldsymbol{\mu}_c, \Lambda_c^{-1})W(\Lambda_i; \nu_c, S_q) \tag{*}$$
ただし、
$$S_q^{-1} = S^{-1} + \sum_{\boldsymbol{x}_k \in cluster-i} (\boldsymbol{x}_k – \bar{\boldsymbol{x}})(\boldsymbol{x}_k – \bar{\boldsymbol{x}})^t + \frac{n_{i}\beta}{n_i + \beta}(\bar{\boldsymbol{x}} – \boldsymbol{\mu}_0)(\bar{\boldsymbol{x}} – \boldsymbol{\mu}_0)^t \\
\bar{\boldsymbol{x}} = \frac{1}{n_i}\sum_{\boldsymbol{x}_k \in cluster-i}\boldsymbol{x}_k \\
\boldsymbol{\mu}_c = \frac{n_{i}\bar{\boldsymbol{x}} + \beta\boldsymbol{\mu}_0}{n_i + \beta} \\
\Lambda_c = (n_i + \beta)\Lambda_i \\
\nu_c = \nu + n_i$$
(*) 式より、クラスタの平均は、大体 $\boldsymbol{\mu}_c (= \frac{n_{i}\bar{\boldsymbol{x}} + \beta\boldsymbol{\mu}_0}{n_i + \beta})$ になり、分散は大体 $(\nu_cS_q)^{-1}$ になります。
$\boldsymbol{\mu_0}$ は平均 $\boldsymbol{\mu}_c$ に影響します。しかし、$\beta$ の値が小さければほとんど影響がないことが分かります。
$\nu, S$ の値は分散 $(\nu_cS_q)^{-1}$ に対して効いてきます。所属データが少なく、かつ $\beta$ が小さいのであれば $\nu \fallingdotseq \nu_c, S \fallingdotseq S_q$ なので ${\nu}S$ の値が大きければ分散は小さくなります。分散が小さいとは、クラスタの範囲が狭くなって、分割されやすいということです。というわけで、${\nu}S$ が大きければ、クラスタは分割されやすくなります。逆に、${\nu}S$ が小さければ、クラスタは分割されにくくなります。しかし所属データが増えてくると、それらの寄与の方が大きくなってきます。
それでは以下のようなサンプルデータを用意して、ハイパーパラメータを変えながら挙動を見てみましょう。
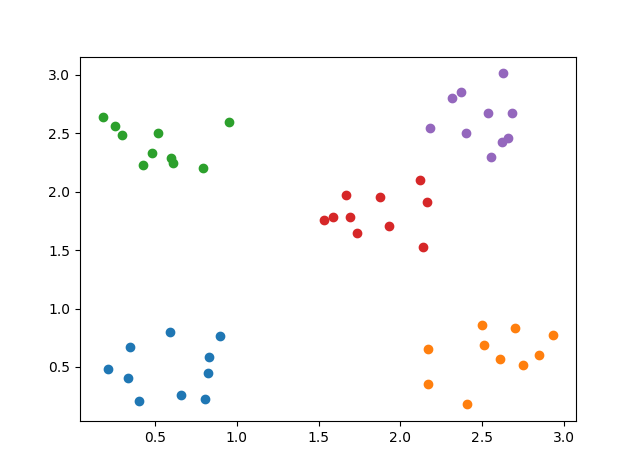
このサンプルは、以下の 5個の正規分布からそれぞれ 10個ずつ生成したものです。
$(\mu, \Sigma) = \biggl((0.5, 0.5), \Bigl(\begin{matrix}0.03 & 0 \\ 0 & 0.03\end{matrix}\Bigr)\biggr)$
$(\mu, \Sigma) = \biggl((2.5, 0.5), \Bigl(\begin{matrix}0.05 & 0 \\ 0 & 0.05\end{matrix}\Bigr)\biggr)$
$(\mu, \Sigma) = \biggl((0.5, 2.5), \Bigl(\begin{matrix}0.05 & 0 \\ 0 & 0.003\end{matrix}\Bigr)\biggr)$
$(\mu, \Sigma) = \biggl((1.8, 1.8), \Bigl(\begin{matrix}0.01 & 0 \\ 0 & 0.01\end{matrix}\Bigr)\biggr)$
$(\mu, \Sigma) = \biggl((2.5, 2.5), \Bigl(\begin{matrix}0.04 & 0 \\ 0 & 0.04\end{matrix}\Bigr)\biggr)$
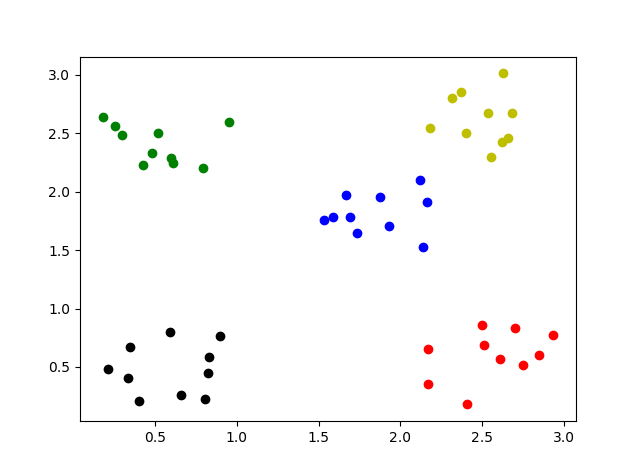
まず、ハイパーパラメータとして $\alpha = 1.0, \mu_0 = $サンプルデータの平均、$S = \Bigl(\begin{matrix}1 & 0 \\ 0 & 1\end{matrix}\Bigr), \nu = 15, \beta = 0.1$ としてクラスタリングしてみます。結果は、以下のように、期待通り 5個のクラスタに分割されました。
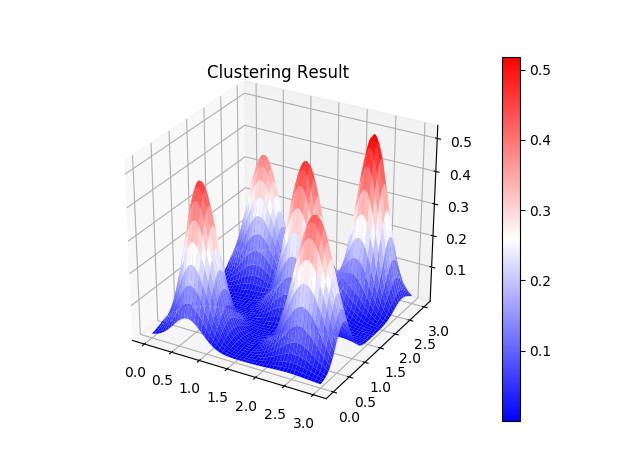
各クラスタがどんな正規分布になったのか見てみると、以下のようにサンプルデータに見合った正規分布になっていることが分かります。ちなみにこの図は、最終状態の各クラスタが従う正規分布を単純に足し合わせ、積分が 1 になるように正規化したものです。
それではパラメータを変えてみましょう。まずは $\alpha$ の値を変えてみます。
これを大きくすると、クラスタが分割されやすくなります。$\alpha = 10$ にしてみましょう。
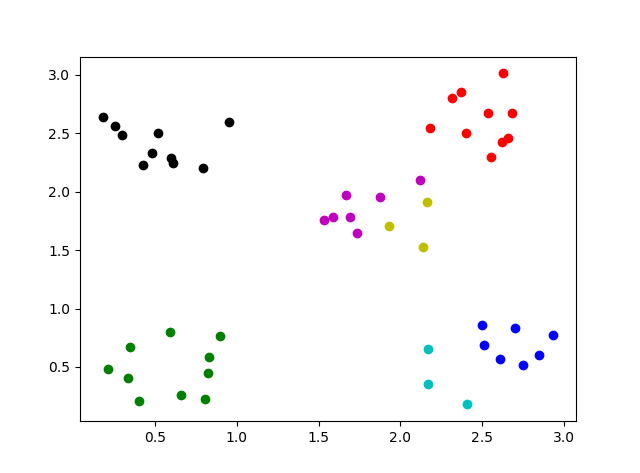
クラスタが 2個増えました。
$\alpha = 15$ にすると、もっと分割されました↓。でもなんか不自然な分割ですよねえ・・。(単にバグってるのか??)ちなみに真ん中近辺の赤と左下の赤は別クラスタです。表示色をさぼったら、赤が 2回出てしまいました。
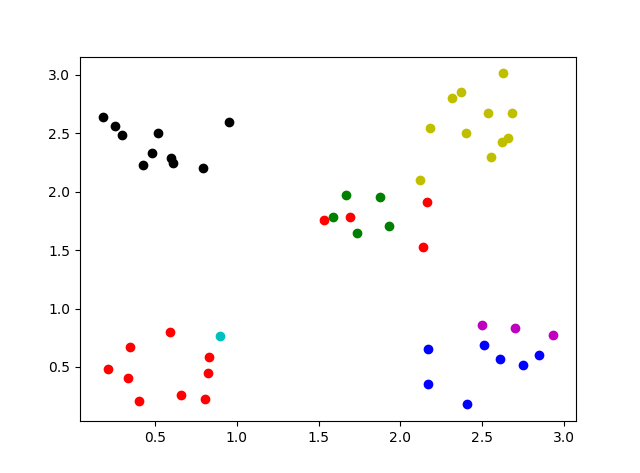
ちなみに、$\alpha = 10, 15$ で試してみると、試行のたびに得られる最終形が違います。適当に安定したら試行を打ち切るようにしているのですが、ひょっとしたら粘りが足りない可能性もあります。
なお、$\alpha = 0.1$ を試すと、$\alpha = 1$ の場合と同じく、5つのクラスタに分割されます。
$\alpha$ の値を大きくするとクラスタが分割するということは、逆に小さくするとクラスタが合体するのでは?と思えますが、クラスタの分割され易さを決めるパラメータは他に $\nu, S$ があるので、そちらとの兼ね合いのため、効かなくなっているような気がします。
次に $S$ と $\nu$ を変えてみましょう。$\alpha$ は $1$ に戻します。先ほど見たように、${\nu}S$ が大きくなるとクラスタは分割されやすくなり、${\nu}S$ が小さくなると分割されにくくなります。
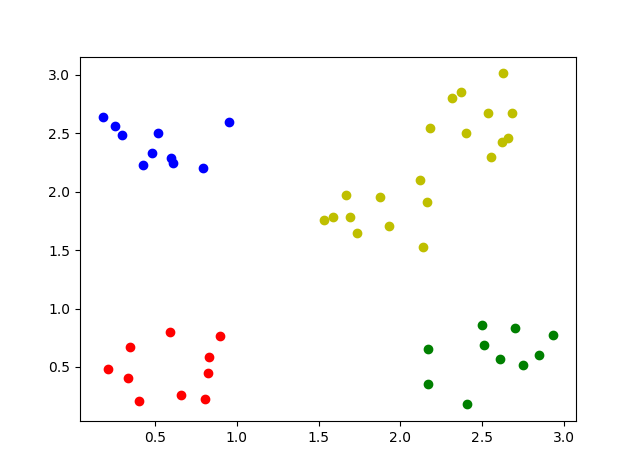
では $S$ だけ変更してみましょう。$S = \Bigl(\begin{matrix}1 & 0 \\ 0 & 1\end{matrix}\Bigr) ⇒ \Bigl(\begin{matrix}0.5 & 0 \\ 0 & 0.5\end{matrix}\Bigr)$ としてみましょう。クラスタが分割されにくくなったため、割と近かった 2つのクラスタが結合しました。

$S = \Bigl(\begin{matrix}0.5 & 0 \\ 0 & 0.5\end{matrix}\Bigr) ⇒ \Bigl(\begin{matrix}1 & 0 \\ 0 & 1\end{matrix}\Bigr)$ に戻して $\nu = 15$ を $7$ に変更してみます。${\nu}S$ の値としてはほぼ同じなので、同じ結果になりました。
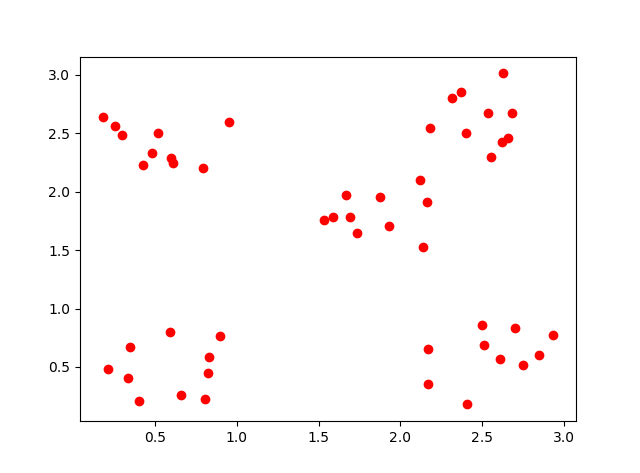
今度は $S = \Bigl(\begin{matrix}0.2 & 0 \\ 0 & 0.2\end{matrix}\Bigr), \nu = 3$ とします。${\nu}S$ の値が小さくなったので、さらに分割されにくくなります。この場合は、クラスタ分割されず、全部が一つのクラスタに所属するという結果になりました。
今度は逆に $S, \nu$ を大きくする方向に変化させてみます。$S = \Bigl(\begin{matrix}2 & 0 \\ 0 & 2\end{matrix}\Bigr), \nu = 30$ にしてみました。しかし、クラスタ分割の結果は 5分割で変わりませんでした。実は、この ${\nu}S$ の値は、5分割よりももっと分割されるかどうかのギリギリのところです。実際、各クラスタの分散の値は変わっています。
$S = \Bigl(\begin{matrix}1 & 0 \\ 0 & 1\end{matrix}\Bigr), \nu = 15$ の場合
$S = \Bigl(\begin{matrix}2 & 0 \\ 0 & 2\end{matrix}\Bigr), \nu = 30$ の場合

後者の各クラスタはずいぶんやせ細っています。クラスタの分割のされ方は前者も後者も同じですが、各クラスタのパラメータは異なっています。後者は結構ギリギリなパラメータであり、これ以上 ${\nu}S$ が大きくなると、もう少しクラスタ分割されてしまいます。
クラスタの形成過程
最後に、クラスタの形成過程を見てみたいと思います。ギブスサンプリングを使って何回も試行して、最も与えられたデータにフィットするクラスタリングを探す方式なので、途中経過を見てみると試行錯誤している風が見えます。
最初は各データがそれぞれ一つでクラスタを形成している状態でスタートしています。つまり、50クラスタからスタートです。段々とクラスタが結合してきて、最終的に 5個のクラスタになります。
この動画は、各クラスタが従う正規分布を単純に足し合わせ、積分が 1 になるように正規化したものを時間軸でパラパラと繋げたものです。ギブスサンプリングを行っているので適当なところで試行を打ち切るのですが、打ち切る前の、事後確率が最大となった時点(最も尤もらしいクラスタ状態)が最終コマになるようにして、最後はしばらく止めるように表示しています。
ついでに、最初は 50個のデータが一つのクラスタを形成している状態からスタートさせてみました。クラスタが分割して、あっちゃこっちゃ行きつつ、最終的に事後確率が最大となる時が 5個として得られます。
今回は、最後の例を除いて、50クラスタを初期状態としてスタートしています。色々観察してみると、1クラスタからスタートするか、50クラスタからスタートするかで、同じハイパーパラメータでも異なる結果になったりします。収束時間に関して言えば、今回のサンプルデータでは 1クラスタからスタートする方が早いように思えます。
ちなみに、やってみて難しいと感じたのは、どこで打ち切るかです。あまり早く切り上げると、不自然な結果になったりします。かといって長いと試行数を増やすのが難しくなりますし・・・。今回は、適当に 5000回事後確率の最大が更新されなかったら打ち切り、としてみました。
(2018/02/02 追記)
今回試しで作った python コードを bitbucket に置きました。

Tags
About Author
takashi.osawa
2 Comments
-
-
Naoki Akai さん、
フィックスターズの大澤です。
コメントをいただき、どうもありがとうございます。python コードはブログを書くためだけに書いたもので、公開するつもりもなかったのですが、コメントをいただいて bitbucket に上げることにしました。
とりあえず動くもの、という程度ですが、↓をご参照ください。
https://bitbucket.org/takashi_osawa/dpgmm
-
Leave a Comment
Tags
Favorite Post

 2023年1月27日
2023年1月27日 2017年8月22日
2017年8月22日
Archives
- 2025年5月
- 2025年4月
- 2024年11月
- 2024年10月
- 2024年7月
- 2024年5月
- 2024年4月
- 2024年2月
- 2024年1月
- 2023年12月
- 2023年6月
- 2023年5月
- 2023年4月
- 2023年2月
- 2023年1月
- 2022年12月
- 2022年10月
- 2021年11月
- 2021年9月
- 2021年6月
- 2021年3月
- 2021年2月
- 2020年12月
- 2020年10月
- 2020年7月
- 2020年6月
- 2020年5月
- 2020年4月
- 2020年3月
- 2020年2月
- 2020年1月
- 2019年12月
- 2019年11月
- 2019年10月
- 2019年9月
- 2019年8月
- 2019年6月
- 2019年4月
- 2019年3月
- 2019年2月
- 2019年1月
- 2018年12月
- 2018年11月
- 2018年10月
- 2018年8月
- 2018年6月
- 2018年5月
- 2018年4月
- 2018年3月
- 2018年2月
- 2017年12月
- 2017年11月
- 2017年10月
- 2017年9月
- 2017年8月
- 2017年7月
- 2017年6月
- 2017年5月
- 2017年3月
- 2016年12月
- 2016年11月
- 2016年8月
- 2016年7月
- 2016年3月
- 2016年2月
- 2016年1月
- 2015年12月
- 2015年11月
- 2015年10月
- 2015年8月
- 2015年6月
- 2015年3月
- 2015年2月
- 2015年1月
- 2014年12月
- 2014年11月
-
keisuke.kimura in Livox Mid-360をROS1/ROS2で動かしてみた
Sorry for the delay in replying. I have done SLAM (FAST_LIO) with Livox MID360, but for various reasons I have not be...
-
Miya in ウエハースケールエンジン向けSimulated Annealingを複数タイルによる並列化で実装しました
作成されたプロファイラがとても良さそうです :) ぜひ詳細を書いていただきたいです!...
-
Deivaprakash in Livox Mid-360をROS1/ROS2で動かしてみた
Hey guys myself deiva from India currently i am working in this Livox MID360 and eager to knwo whether you have done the...
-
岩崎システム設計 岩崎 満 in Alveo U50で10G Ethernetを試してみる
仕事の都合で、検索を行い、御社サイトにたどりつきました。 内容は大変参考になりま�...
-
Prabuddhi Wariyapperuma in Livox Mid-360をROS1/ROS2で動かしてみた
This issue was sorted....
ディリクレ過程混合モデルに関する記事を拝見させていただきました.
非常に参考になりました.
今回使用されたpythonのコードを見て,具体的な実装方法を勉強したいのですが,使用されたソースはオープンソースとして公開されたりしていますか?