このブログは、株式会社フィックスターズのエンジニアが、あらゆるテーマについて自由に書いているブログです。
イベント参加レポート:NVIDIA Jetson Xavier Developer Day 2018
遠藤です。
9/11 に品川で行われた「NVIDIA Jetson Xavier Developer Day 2018」に参加する機会があったので、行ってまいりました。今回は、その参加レポートをお送りしたいと思います。
NVIDIAセッション: Jetson Xavier 概要と Jetson SDK
NVIDIAセッションでは、まず Jetson Xavier の開発経緯と、なぜ Jetson TX3 ではなく Xavier という全く新しい世代にモデルチェンジを図ったかについて、その意図が説明されました。
これまでの Jetson シリーズでは、現代の自律システムを動かすための性能が絶対的に不足しているという課題があると、まず説明がありました。例えば、光学センサー・LIDAR・超音波センサー等を搭載するデリバリーロボットを想定すると、求められる計算能力は 20 TOPS (Operations Per Second) が必要になるとの試算となったそうです。また、ビデオ解析のアプリケーションを想定すると、必要とされる性能はさらに増え 30 TOPS 超の性能が求められるといいます。
この計算能力を実現するためには、これまでの GPU を用いるならば、 GTX 1070 相当の GPU が必要となり、Jetson では明らかに不足しているとのことでした。GTX 1070 の消費電力は 150W で、ゲーミング PC 相当のフットプリントが求められるかなり大掛かりなシステムとなり、このままでは組込み用途で GPU を適用することは難しいとの指摘がされました。
Jetson Xavier は、わずか 30W の消費電力で 32 TOPS の性能をたたき出す根本的に新しい SoC となり、下図に示す通り Jetson TX2 と比べて非常に大きな性能向上を果たしたとの説明がありました。
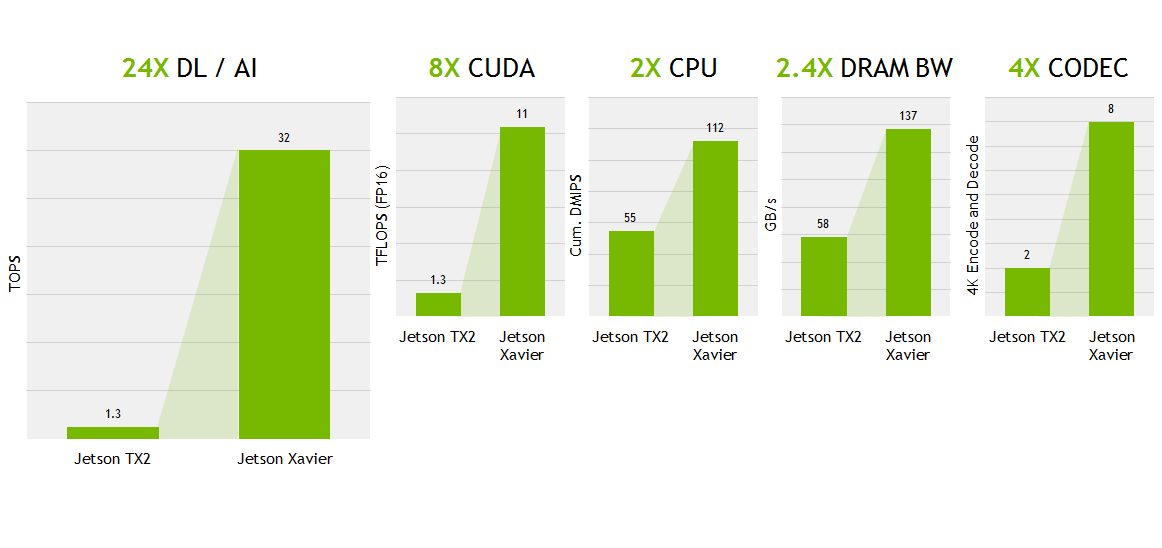
https://blogs.nvidia.co.jp/2018/08/30/nvidia-jetson-xavier-developer-kit-now-available-for-pre-order/ より引用
次に、Jetson Xavier ではハードウェアとしての性能向上が図られただけでなく、NVIDIAが提供している豊富な SDK 群にあるとの紹介がありました。具体的には JetPack(CUDAとその周辺ライブラリのセット)、DeepStream(ビデオ解析用SDK)と Isaac (自律ロボット向けSDK) です。
現時点ではまだ Xavier のSDK は開発中の状態で、Xavier 向けのチューニングが進んでいないとのことだったので、今後の開発に期待してほしいということでした。
スポンサーセッションまとめ
スポンサー各社様のセッションは、大きく分けて Xavier を使ってみた系の発表と、Xavier 関連サービスのご紹介でした。後者のサービス紹介は割愛させていただき、今回は前者の使ってみた系の発表内容をざっくりとまとめたいと思います。
動かした系の発表では、実際のデモアプリについてその実行性能が語られていました。こまごまとした性能の数字はあるのですが、それだけを見ても正直 Xavier が他の Jetson シリーズ、GPUやCPUの性能との有意性があるのか判断がつけられないと感じました。そのためここでは省略します。
動かした系の発表では、ディープラーニングを用いたアプリケーションの推論のデモが多くを占めていました。そこで、各社様とも TensorRT を使った高速化を実施されていました。Xavier では Volta 世代の GPU を搭載しているということで、Tensor Core が使えるという点を各社様クローズアップされていました。実際、FP16 にすることで FP32 よりも倍以上性能が出る例も報告されており、Tensor Core のポテンシャルを感じさせるものでした。
ただし、それは見方を変えると Xavier でも高い性能をたたき出すためには FP16 化対応といった高速化テクニックがまだ必要ということでもあります。幸い TensorRT を使うことで FP16 化は一瞬でできるようになっていますが、精度上 FP16 化が許されないケースでは注意が必要です。
所感
最新 Volta 世代のGPUが、組込みの世界に進出してきました。GPUが強化されただけでなく、メモリ帯域の強化や NVDLA(ディープラーニングアクセラレータ) の搭載など、これまでとは違う Jetson として、NVIDIA の強い意気込みを感じる発表会となりました。NVIDIA公称では Jetson TX2 と比べ性能 (TOPS) が32倍と桁違いの向上を果たしており、組込みでも高火力な計算資源を使えるようになり、エッジヘビーコンピューティングがますます流行るのだろうと感じました。
一方、Xavier の性能の真価について現時点ではまだ判断を下すのは難しいという印象を受けました。例えば、実際のユースケースで本当に 32 倍の性能向上が図られているかという点については、検証が足りてない印象を受けました。スポンサーセッションでは使ってみた系の発表がいろいろありましたが、TX2 と Xavier との比較という観点ではあまり語られておらず、単に Xavier で動かしてどうだったという話が多かったです。また、Xavier での性能測定結果については、まだライブラリ側の最適化が追い付いておらず、HWの性能を出し切った評価が現時点ではまだ難しいことが分かりました。まだ開発中なのでそれは仕方ないのですが、あとどのくらいの向上余地があるのかの目安などが示されなかったため、Xavier の真の実力がどれほどか評価するのが難しいと感じました。もうしばらくライブラリ側の成熟を待つ必要がありそうです。
他に感じたこととしては、NVIDIAが築き上げたプラットフォームのすごさを改めて実感しました。ディープラーニングの推論を例にとってみると、これまでは手動での気の遠くなるようなチューニングを経ないと GPU の性能を引き出すことができませんでしたが、今ではモデルを TensorRT に食わせるだけで、GPU の性能が引き出せてしまいます。そのようなプラットフォームがあることで、誰でもGPUの性能を享受できる世界がやってきつつあることを実感しました。

Tags
About Author
yasunori.endo
Leave a Comment
Tags
Favorite Post

 2017年8月22日
2017年8月22日 2017年10月31日
2017年10月31日
Archives
- 2024年4月
- 2024年2月
- 2024年1月
- 2023年12月
- 2023年6月
- 2023年5月
- 2023年4月
- 2023年2月
- 2023年1月
- 2022年12月
- 2022年10月
- 2021年11月
- 2021年9月
- 2021年6月
- 2021年3月
- 2021年2月
- 2020年12月
- 2020年10月
- 2020年7月
- 2020年6月
- 2020年5月
- 2020年4月
- 2020年3月
- 2020年2月
- 2020年1月
- 2019年12月
- 2019年11月
- 2019年10月
- 2019年9月
- 2019年8月
- 2019年6月
- 2019年4月
- 2019年3月
- 2019年2月
- 2019年1月
- 2018年12月
- 2018年11月
- 2018年10月
- 2018年8月
- 2018年6月
- 2018年5月
- 2018年4月
- 2018年3月
- 2018年2月
- 2017年12月
- 2017年11月
- 2017年10月
- 2017年9月
- 2017年8月
- 2017年7月
- 2017年6月
- 2017年5月
- 2017年3月
- 2016年12月
- 2016年11月
- 2016年8月
- 2016年7月
- 2016年3月
- 2016年2月
- 2016年1月
- 2015年12月
- 2015年11月
- 2015年10月
- 2015年8月
- 2015年6月
- 2015年3月
- 2015年2月
- 2015年1月
- 2014年12月
- 2014年11月
コンピュータビジョンセミナーvol.2 開催のお知らせ - ニュース一覧 - 株式会社フィックスターズ in Realizing Self-Driving Cars with General-Purpose Processors 日本語版
[…] バージョンアップに伴い、オンラインセミナーを開催します。 本セミナーでは、�...
【Docker】NVIDIA SDK Managerでエラー無く環境構築する【Jetson】 | マサキノート in NVIDIA SDK Manager on Dockerで快適なJetsonライフ
[…] 参考:https://proc-cpuinfo.fixstars.com/2019/06/nvidia-sdk-manager-on-docker/ […]...
Windowsカーネルドライバを自作してWinDbgで解析してみる① - かえるのほんだな in Windowsデバイスドライバの基本動作を確認する (1)
[…] 参考:Windowsデバイスドライバの基本動作を確認する (1) - Fixstars Tech Blog /proc/cpuinfo ...
2021年版G検定チートシート | エビワークス in ニューラルネットの共通フォーマット対決! NNEF vs ONNX
[…] ONNX(オニキス):Open Neural Network Exchange formatフレームワーク間のモデル変換ツー�...
YOSHIFUJI Naoki in CUDAデバイスメモリもスマートポインタで管理したい
ありがとうございます。別に型にこだわる必要がないので、ユニバーサル参照を受けるよ...