このブログは、株式会社フィックスターズのエンジニアが、あらゆるテーマについて自由に書いているブログです。
TensorRTでPSPNetのエンコーダを量子化する
アルバイトの富岡(祐)です。 今回はFixstars Autonomous Technologiesで取り組んでいるCNNの高速化に関連して、TensorRTを用いた高速化及び量子化についてご紹介したいと思います。
TL;DR
TensorRTを用いて、PSPNetのエンコーダ部分となるResNetの重みを量子化し演算精度を下げることで、推論精度の低下を軽微に抑えつつ、従来のフレームワーク上よりもメモリ容量の小さいモデルで、高速にセマンティックセグメンテーションを行うことが可能となる。
目指すもの
Fixstarsでは、精度は高いが計算負荷も高いと言われているCNNについて、処理を高速化する技術の検討を行っています。
今回はその検討の一環として、PSPNetと呼ばれるCNNベースのセマンティックセグメンテーションの手法について、TensorRTというツールを用いた高速化を試みました。
TensorRTはNVIDIA製のDNN高速化ライブラリですが、対応するGPUが高価なものに限られていることもあり、特に日本語で公開されている記事等はあまり多くありません。本記事は、TensorRTをPSPNetに対してどのように導入したか、それによりどのような結果が得られたかについて共有することを目的として作成しました。
PSPNetについて
今回取り上げるPSPNetは、CVPR2017で発表された論文「Pyramid Scene Parsing Network」にて提案された、セマンティックセグメンテーションの手法です。
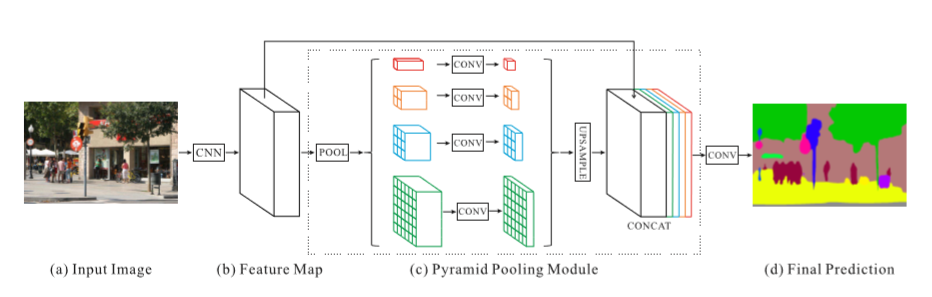
ネットワークの構造は上図のようになっており、ResNetなどの既存のモデルを用いた特徴検出(b)をエンコーダとし、デコーダとして複数の解像度でプーリングを行うPyramid Pooling Module(c)を用いています。
今回は、TensorRTを取り入れる対象となるPSPNetの実装としてCSAILVision/semantic-segmentation-pytorchを使用しました。
この記事ではPSPNetの詳細は取り上げませんので、詳しくは上述の論文や実装をご覧いただければと思います。
TensorRTと量子化について
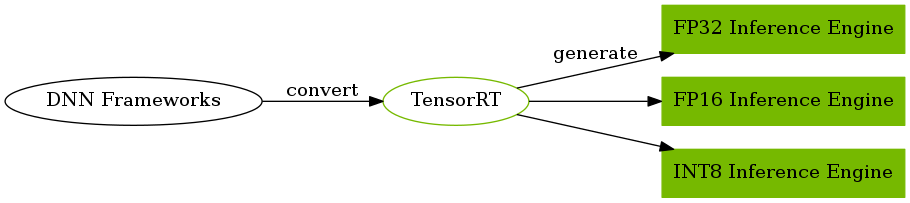
TensorRTは、NVIDIAが開発を行っている、NVIDIA製GPU上でのDNNの推論処理の最適化を目的としたライブラリです。使用できるデバイスや、対応しているネットワークモデル上のレイヤは限られるものの、従来のDNNフレームワーク上よりも遅延の少ない高スループットな推論を行うことを可能とします。
TensorRTは入力した学習済みのネットワークモデルに対して、以下のような処理を行うことで推論処理を高速化します。
- Dynamic Tensor Memory
- Layer & Tensor Fusion
- Kernel Auto-Tuning
- Multi-Stream Execution
- Precision Calibration
このうち、最後に記載した計算精度のキャリブレーション(今回の記事で取り上げている量子化の処理)は処理時間が大きく削減され、推論に必要なメモリ量の削減もできることも知られています。しかし、ネットワークモデルの出力が変化してしまうため、他の高速化処理とは異なり、手動で設定を変更する必要があります。
なお、この時、計算精度は元となる32bit-float (単精度浮動小数点、FP32)から、16bit-float(半精度浮動小数点、FP16)や8bit-integer(8bit整数、INT8)に変更することが出来ます
演算に用いる数値表現の精度が下がるため、DNNの推論結果の精度にも大きな影響が出ることも考えられますが、特にクラス分類問題では、ほとんど精度を落とすことなく推論処理を高速化することができるとされています。一方で、物体検出やセマンティックセグメンテーションに対しては、精度の低下が起こりやすいとも言われています。
PyTorchのモデルをTensorRTに取り込む
TensorRTで推論を行う場合は、他のフレームワーク上で学習したネットワークモデルを取り込み、それをもとに最適化を行います。特に今回は、PyTorch上で学習したPSPNetのネットワークモデルを、共通フォーマットの一つであるONNXの形式に変換し、その後ONNX形式のネットワークモデルをTensorRTに取り込むことでPSPNetの学習済みのネットワークモデルを用意しました。
今回の検証及びサンプルコードでは、Pythonのtensorrt、pycuda、onnxモジュールを用いています。これらのインストールについては以下を参考にしていただければと思います。
- tensorrt:https://docs.nvidia.com/deeplearning/sdk/tensorrt-install-guide/index.html
- pycuda:https://wiki.tiker.net/PyCuda/Installation
- onnx:https://github.com/onnx/onnx#installation
PyTorchのモデルをONNX形式に変換

PyTorchで作成し、学習を行ったネットワークモデルは、以下のようにして、PyTorch内の機能を用いてONNX形式で出力することが出来ます。
import torch # torch 1.0.1.post2
pytorch_model.train(False)
temp_input = torch.autograd.Variable(torch.randn(input_shape), requires_grad=True)
torch.onnx._export(pytorch_model, temp_input, output_onnx_model_path, export_params=True, output_names=["output"])ONNX形式に変換したモデルは以下のようにするとテキスト形式で中身が確認できるほか、こちらのチュートリアルに従ってグラフ化することもできます。
import onnx # onnx 1.5.0
onnx_model = onnx.load(onnx_model_path)
print(onnx_model)ONNX形式のモデルからTensorRTの推論エンジンを作成

ONNX形式のモデルは以下のようにしてTensorRTに読み込み、推論エンジンを作成することができます。
import tensorrt as trt # tensorrt 5.1.2.2
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
with trt.Builder(TRT_LOGGER) as builder, builder.create_network() as network, trt.OnnxParser(network, TRT_LOGGER) as parser:
builder.max_workspace_size = 1 << 20
with open(onnx_model_path, 'rb') as model:
parser.parse(model.read())
engine = builder.build_cuda_engine(network)このとき、ONNX形式のネットワークモデルで、TensorRTが対応していないレイヤが使われていた場合、RuntimeErrorとして、レイヤのONNX上での名称が出力されます。TensorRTが対応しているレイヤに関しては、公式ドキュメントなどで確認できます。
TensorRTの推論エンジンを用いた推論
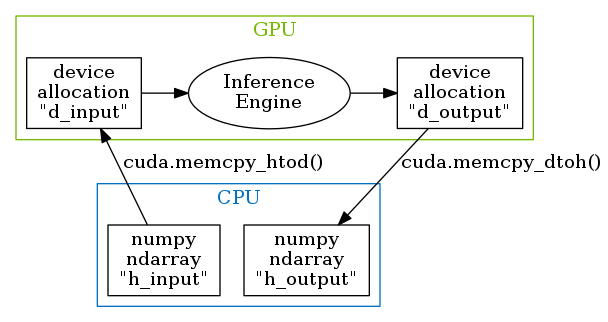
作成したエンジンは、実行可能なコンテキストを取り出し、CUDAやPyCUDAで確保したGPU上のメモリ領域を渡すことで推論を行ってくれます。
import pycuda.driver as cuda # pycuda 2018.1.1
import pycuda.autoinit
context = engine.create_execution_context()
h_input = cuda.pagelocked_empty(trt.volume(engine.get_binding_shape(0)), dtype=trt.nptype(engine.get_binding_dtype(0)))
h_output = cuda.pagelocked_empty(trt.volume(engine.get_binding_shape(1)), dtype=trt.nptype(engine.get_binding_dtype(1)))
d_input = cuda.mem_alloc(h_input.nbytes)
d_output = cuda.mem_alloc(trt.volume(engine.get_binding_shape(1)) * 4)
stream = cuda.Stream()
np.copyto(h_input, input_numpy_array)
cuda.memcpy_htod_async(d_input, h_input, stream)
context.execute_async(bindings=[int(d_input), int(d_output)], stream_handle=stream.handle)
stream.synchronize()
cuda.memcpy_dtoh_async(h_output, d_output, stream)TensorRTのエンコーダ出力をPyTorchで受け取る
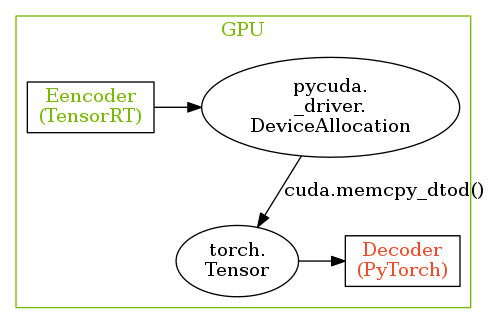
今回はPSPNetのエンコーダの部分のみをTensorRTの推論エンジンに置き換えたため、PythonAPI上でのエンコーダの出力はPyCUDAのpycuda._driver.DeviceAllocationです。
このGPU上のメモリ領域をPyTorchで実装されたデコーダに渡すためには、適切な変換を行う必要があります。
このとき、pycuda._driver.DeviceAllocationをCPUに転送し、Numpyのnumpy.ndarrayを経由してPyTorchのtorch.Tensorに変換することもできますが、これではメモリの転送に大きな時間を使うこととなってしまいます。
そのため、今回はGPU上でpycuda._driver.DeviceAllocationが表すメモリ領域を、以下のようにGPUに転送したtorch.Tensorにコピーすることで、エンコーダの出力をデコーダの入力に変換します。
tensor = torch.zeros(shape, dtype=torch.float32).cuda()
cuda.memcpy_dtod(tensor.data_ptr(), d_output, trt.volume(shape) * 4)ここで、d_outputがエンコーダの出力となります。
このとき、cuda.memcpy_dtod()の第一引数と第二引数に指定するメモリ領域のバイト数が、第三引数で指定するコピーするメモリ領域のバイト数よりも小さいとエラーが出るため、注意が必要です。
TensorRTでモデルを量子化する
TensorRTで量子化できる計算の精度はFP16とINT8の二つとなっており、それぞれプログラム上での設定方法が異なっています。
- FP16
FP16への量子化は非常に簡単で、以下のフラグをTensorRTのbuilderに対して設定するだけで、すべてのレイヤの演算精度がFP16となります。
builder.fp16_mode = True
builder.strict_type_constraints = True- INT8
INT8への量子化は二つの方法があり、FP16ほど簡単に行うことは出来ません。
両方の方法に共通の操作として、FP16への量子化と同じように、builderには以下のフラグを設定する必要があります。
builder.int8_mode = True
builder.strict_type_constraints = TrueINT8への量子化を行う際に、FP32の表現し得る数値の範囲をそのままINT8の範囲にマッピングすると、ネットワークモデルの表現力が著しく低下し、正しく推論を行うことが出来なくなってしまいます。そこで、FP32で表されたネットワークモデル上の数値をどのようにINT8の範囲に収めるかを検討しなくてはなりません。
INT8への量子化の方法の一つ目は、以下のように一つ一つのレイヤのダイナミックレンジを指定する方法です。
for input_index in range(network.num_inputs):
input_tensor = network.get_input(input_index)
input_tensor.set_dynamic_range(dynamic_range_min, dynamic_range_max)
for layer_index in range(network.num_layers):
layer = network[layer_index]
for output_index in range(layer.num_outputs):
tensor = layer.get_output(output_index)
tensor.set_dynamic_range(dynamic_range_min, dynamic_range_max)もう一つの方法は、ネットワークモデルの典型的な入力バッチを用いてダイナミックレンジをキャリブレーションする方法です。
キャリブレーションを行うためには、キャリブレータを実装し、以下のようにしてbuilderに登録する必要があります。
calib = Calibrator()
builder.max_batch_size = calib.get_batch_size()
builder.int8_calibrator = calibここで、Calibrator()は実装したキャリブレータのコンストラクタとなります。
キャリブレータは、TensorRTでいくつか用意されたキャリブレータ用のクラスの内ひとつを継承し、実装を行う必要があります。今回はIInt8EntropyCalibrator2を継承したキャリブレータの実装を行いました。
TensorRTのPythonAPIでキャリブレーションを行うために必要な実装についての情報は少ないですが、TensorRTの公式のサンプルとしてインストールされている/usr/src/tensorrt/samples/python/int8_caffe_mnistを参考にするとよいと思います。(このサンプルについては公式ドキュメントにも解説があります。)
キャリブレーションに用いる入力として用いるデータはそれほど多く用意する必要はなく、例えばImageNetのクラス分類問題では約500枚程度の画像で十分であると言われています。(参考)
ダイナミックレンジを決定した後は、通常のエンジン作成と同じ手順で推論エンジンを得ることができます。
TensorRTを用いたPSPNetの性能
- PyTorchのPSPNetの推論結果

- INT8で演算を行うTensorRTの推論エンジンをエンコーダに用いた推論結果

PyTorchで実装されたPSPNetのネットワークモデルと、エンコーダ部分をTensorRTの推論エンジンに置き換えたものとで推論を行い、速度や推論精度、モデルサイズを比較しました。
また、今回の計測で使用したデバイスは、NVIDIAのVoltaアーキテクチャを使用した、TITAN Vとなっています。
以降のグラフでは、PyTorchで実装されたPSPNetのネットワークモデルから得たデータをPyTorch、TensorRTの推論エンジンを用いているものは、FP32、INT8などそれぞれのエンジンでの推論時に用いる計算精度で表記しています。
- Pixel-Wise Accuracy

Pixel-Wise Accuracyは、INT8に量子化した推論エンジンを用いた場合に0.04%ほど落ちるものの、その差は軽微なものであり、FP16への量子化ではほとんど差がないという結果となりました。
- Mean IoU

Mean IoUに関しても、Accuracyと同じように、値としては結果に差がほとんどありません。
量子化を行った場合でも、物体の領域の推定は正確性を失わずに行うことが可能なようです。
- Inference Time
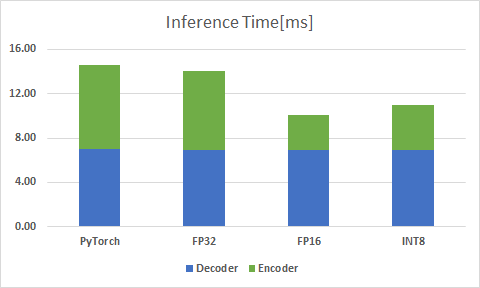
推論時間は、エンコーダの部分のみを考えると、PyTorchの推論時間と比較してFP16では59.2%、INT8では46%と大きく削減されています。
しかし、計算精度を下げているにもかかわらず、INT8はFP16よりも推論時間が大きくなっていることが分かります。
- Model Size
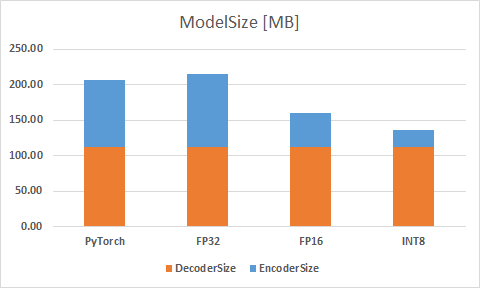
ここでのモデルサイズの大きさは、それぞれ学習したデータを格納したファイルの容量の大きさとしています。
モデルサイズは、エンコーダの部分だけを考えると、PyTorchの推論時間と比較してFP16では49.4%、INT8では73.9%とこちらも大きく削減されています。
推論時間ではFP16よりも大きかったINT8も、モデルサイズでは単純にFloat16の半分程度となっています。
まとめ
今回は、PSPNetのエンコード部分をTensorRTで量子化することで、以下の効果が得られました。
- 推論速度の向上:最大で31%の推論時間を削減
- モデルサイズの縮小:最大で33%のモデルサイズの削減
- 推論精度の維持:精度低下はMeanIoUでは0.5%以下、Accuracyでは0.05%以下
よって、既存のネットワークモデルに変更を加えることなく、精度の低下を軽微に抑え、従来のフレームワーク上よりもメモリ容量の小さいモデルで、高速に推論を行うことができました。
現在、TensorRTに関しての情報は少なく、学習コストがあるものの、TensorRTによる量子化は、わずかなコード量で既存のネットワークモデルを高速・軽量にできる可能性があるものだといえるでしょう。

Tags
About Author
TomiokaYusuke
Leave a Comment
Tags
Favorite Post

 2017年8月22日
2017年8月22日 2017年10月31日
2017年10月31日
Archives
- 2024年2月
- 2024年1月
- 2023年12月
- 2023年6月
- 2023年5月
- 2023年4月
- 2023年2月
- 2023年1月
- 2022年12月
- 2022年10月
- 2021年11月
- 2021年9月
- 2021年6月
- 2021年3月
- 2021年2月
- 2020年12月
- 2020年10月
- 2020年7月
- 2020年6月
- 2020年5月
- 2020年4月
- 2020年3月
- 2020年2月
- 2020年1月
- 2019年12月
- 2019年11月
- 2019年10月
- 2019年9月
- 2019年8月
- 2019年6月
- 2019年4月
- 2019年3月
- 2019年2月
- 2019年1月
- 2018年12月
- 2018年11月
- 2018年10月
- 2018年8月
- 2018年6月
- 2018年5月
- 2018年4月
- 2018年3月
- 2018年2月
- 2017年12月
- 2017年11月
- 2017年10月
- 2017年9月
- 2017年8月
- 2017年7月
- 2017年6月
- 2017年5月
- 2017年3月
- 2016年12月
- 2016年11月
- 2016年8月
- 2016年7月
- 2016年3月
- 2016年2月
- 2016年1月
- 2015年12月
- 2015年11月
- 2015年10月
- 2015年8月
- 2015年6月
- 2015年3月
- 2015年2月
- 2015年1月
- 2014年12月
- 2014年11月
コンピュータビジョンセミナーvol.2 開催のお知らせ - ニュース一覧 - 株式会社フィックスターズ in Realizing Self-Driving Cars with General-Purpose Processors 日本語版
[…] バージョンアップに伴い、オンラインセミナーを開催します。 本セミナーでは、�...
【Docker】NVIDIA SDK Managerでエラー無く環境構築する【Jetson】 | マサキノート in NVIDIA SDK Manager on Dockerで快適なJetsonライフ
[…] 参考:https://proc-cpuinfo.fixstars.com/2019/06/nvidia-sdk-manager-on-docker/ […]...
Windowsカーネルドライバを自作してWinDbgで解析してみる① - かえるのほんだな in Windowsデバイスドライバの基本動作を確認する (1)
[…] 参考:Windowsデバイスドライバの基本動作を確認する (1) - Fixstars Tech Blog /proc/cpuinfo ...
2021年版G検定チートシート | エビワークス in ニューラルネットの共通フォーマット対決! NNEF vs ONNX
[…] ONNX(オニキス):Open Neural Network Exchange formatフレームワーク間のモデル変換ツー�...
YOSHIFUJI Naoki in CUDAデバイスメモリもスマートポインタで管理したい
ありがとうございます。別に型にこだわる必要がないので、ユニバーサル参照を受けるよ...