このブログは、株式会社フィックスターズのエンジニアが、あらゆるテーマについて自由に書いているブログです。
SSDにMobileNetを組み込んで軽量化する (2)
アルバイトの富岡です。
この記事は「MobileNetでSSDを高速化①」の続きとなります。ここでは、MobileNetの理論的背景と、MobileNetを使ったSSDで実際に計算量が削減されているのかを分析した結果をご紹介します。
単純な推論速度と精度の測定結果は前回の記事をご覧ください。
TL;DR
MobileNetは、畳み込みの演算をチャンネル方向と空間方向に分割して行うことで、計算量を減らすことが可能であり、実際にSSDの中のレイヤー単位で処理速度の変化がみられる。
MobileNetによる計算量削減の仕組み
前回の記事でも述べたように、MobileNetは畳み込み演算をモデルをより深くするように分割し、近似を行うことで計算量を減らし、軽量化をすることができます。
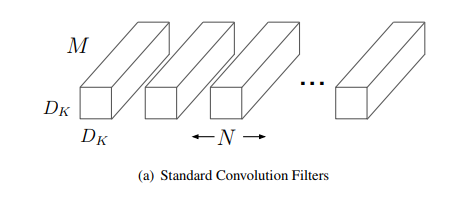
従来の畳み込み演算は上の図のようなカーネルを用いて行われています。空間方向Dₖ×Dₖ、チャンネル方向Mのカーネルを入力の端から端まで乗算していくことで、畳み込みを行います。計算量はO(W×H×Dₖ²×M×N)です。
MobileNetでは、この畳み込みのカーネルを以下のように二つに分割します。
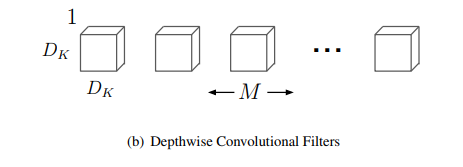
上の図は、空間方向のみを持ち、チャンネル方向が1のカーネルです。これをそれぞれのチャンネルの入力に畳み込むことで空間方向の畳み込みを行います。この過程の計算量はO(W×H×Dₖ²×M)です。
その後、以下の図に示すカーネルにより、再び畳み込みを行います。
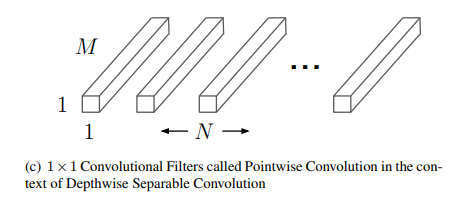
上の図は、空間方向が1×1で、チャンネル方向のみを持つカーネルです。これをN個用意し入力に畳み込むことで、チャンネル数をMからNに変化させ、チャンネル方向の畳み込みを行います。この過程の計算量はO(W×H×M×N)になります。
これらの行程を比較すると、従来の畳み込みとMobileNetの畳み込みの計算量は、それぞれO(W×H×Dₖ²×M×N)とO(W×H×M×(Dₖ²+N))となります。これらの比を取ると1 : 1/N+1/Dₖ²となり、カーネルサイズDₖと畳み込み後のチャンネル数Nが大きいほど計算量が少なくなることが分かります。
このような仕組みによってMobileNetでは、CNNの計算量を大きく削減することができるのです。
レイヤーごとの処理速度
測定結果
今回は、MobileNetによる畳み込み演算の高速化の効果を確かめるために、MobileNet-SSDとSSD300の畳み込み層の処理時間を、プロファイル結果を元に比較します。今回は各Layerの中から、出力が推論に直接用いられるPredictionLayer(各解像度の特徴マップの最終層、下図①~⑥)をピックアップし、それぞれのモデルで比較しました。各Layerの処理時間を積算で表示した結果は以下のようになります。

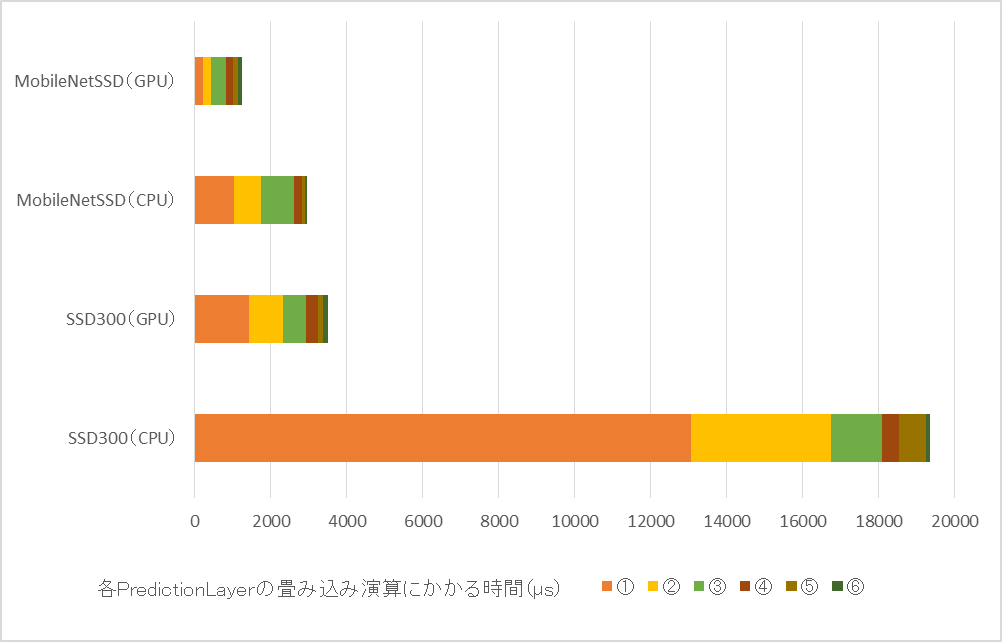
ここで、(GPU)がついたものはGeForce GTX 1080Tiを、(CPU)がついたものはIntel(R) Core(TM) i9-7900X CPU @ 3.30GHz(10コア)を用いて計算した処理時間を表しています。
考察
まずCPU同士の処理時間を比較すると、SSD300に比べMobileNet-SSDはとても短い時間で計算を行うことができることがわかります。これは、上で述べたような計算量削減の仕組みが実際に機能していることを意味しています。また、GPUでの処理においても、CPUほどではありませんが処理時間が削減されていることがわかります。
次にLayer毎の処理時間を見てみると、解像度の高い特徴マップを畳み込む①や②の処理時間の削減量が大きく、これにより全体の処理時間が大幅に削減されていることが分かります。一方で、これは①や②のLayerの元々の処理時間が大きいためであり、処理時間の削減比率は、畳み込みのカーネルサイズと畳み込み後のチャンネルサイズによって決まっていることに留意する必要があります。
※今回提示した図はプロファイル結果から一部のLayerの処理時間を抜き出して積算値のグラフにしたものであり、実際のCPU/GPUでの処理時間ではありません。
まとめ
畳み込みの演算をチャンネル方向と空間方向に分割して行うMobileNetを導入することで、計算量を大幅に減らすことが可能になることを理論的に確かめました。また、実際に各Layerでの処理時間を求めることで、理論通り処理時間が削減されていること、解像度の高い特徴マップを畳み込む層において特に顕著な処理時間の削減が見られることを明らかにしました。
[1]Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam. (17 Apr 2017). “MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications”. Computer Vision and Pattern Recognition. view on https://arxiv.org/abs/1704.04861

Tags
About Author
TomiokaYusuke
Leave a Comment
Tags
Favorite Post

 2023年1月27日
2023年1月27日 2017年8月22日
2017年8月22日
Archives
- 2025年5月
- 2025年4月
- 2024年11月
- 2024年10月
- 2024年7月
- 2024年5月
- 2024年4月
- 2024年2月
- 2024年1月
- 2023年12月
- 2023年6月
- 2023年5月
- 2023年4月
- 2023年2月
- 2023年1月
- 2022年12月
- 2022年10月
- 2021年11月
- 2021年9月
- 2021年6月
- 2021年3月
- 2021年2月
- 2020年12月
- 2020年10月
- 2020年7月
- 2020年6月
- 2020年5月
- 2020年4月
- 2020年3月
- 2020年2月
- 2020年1月
- 2019年12月
- 2019年11月
- 2019年10月
- 2019年9月
- 2019年8月
- 2019年6月
- 2019年4月
- 2019年3月
- 2019年2月
- 2019年1月
- 2018年12月
- 2018年11月
- 2018年10月
- 2018年8月
- 2018年6月
- 2018年5月
- 2018年4月
- 2018年3月
- 2018年2月
- 2017年12月
- 2017年11月
- 2017年10月
- 2017年9月
- 2017年8月
- 2017年7月
- 2017年6月
- 2017年5月
- 2017年3月
- 2016年12月
- 2016年11月
- 2016年8月
- 2016年7月
- 2016年3月
- 2016年2月
- 2016年1月
- 2015年12月
- 2015年11月
- 2015年10月
- 2015年8月
- 2015年6月
- 2015年3月
- 2015年2月
- 2015年1月
- 2014年12月
- 2014年11月
keisuke.kimura in Livox Mid-360をROS1/ROS2で動かしてみた
Sorry for the delay in replying. I have done SLAM (FAST_LIO) with Livox MID360, but for various reasons I have not be...
Miya in ウエハースケールエンジン向けSimulated Annealingを複数タイルによる並列化で実装しました
作成されたプロファイラがとても良さそうです :) ぜひ詳細を書いていただきたいです!...
Deivaprakash in Livox Mid-360をROS1/ROS2で動かしてみた
Hey guys myself deiva from India currently i am working in this Livox MID360 and eager to knwo whether you have done the...
岩崎システム設計 岩崎 満 in Alveo U50で10G Ethernetを試してみる
仕事の都合で、検索を行い、御社サイトにたどりつきました。 内容は大変参考になりま�...
Prabuddhi Wariyapperuma in Livox Mid-360をROS1/ROS2で動かしてみた
This issue was sorted....