このブログは、株式会社フィックスターズのエンジニアが、あらゆるテーマについて自由に書いているブログです。
SSDにMobileNetを組み込んで軽量化する (1)
MobileNetでSSDを高速化
アルバイトの富岡です。
Fixstars Autonomous Technologiesのインターンシップで、Convolutional Neural Network(CNN)の計算量を削減するMobileNetをCNNベースの物体検出器に組み込むというテーマに取り組みましたので、その成果を紹介します。
なお、CNNに関する記述は既に多くの書籍やブログにまとめられていますので、本稿では説明を行いません。
また、今回利用した物体検出器であるSingle-Shot multi-box Detector(SSD)に関しても詳細な解説は行いませんので、より詳しく知りたい方は論文などを参照していただければと思います。
- SSD論文:https://arxiv.org/abs/1512.02325
- SSD論文(日本語訳):https://qiita.com/de0ta/items/1ae60878c0e177fc7a3a
TL;DR
SSDにMobileNetを組み込むことで、精度の低下を軽微に抑えつつ計算量を減らすことができ、貧弱なコンピューティング環境での推論速度を飛躍的に向上させることが可能となる。
目指すもの
SSDはCNNベースの物体検出アルゴリズムの中で最も有名なものの一つです。その最大の特徴は、複数解像度の特徴マップを用いて物体候補領域の推定とクラス分類を行うことです。
SSDは高精度な物体検出を実時間で処理できますが、それはハイエンドなGPUが利用可能な場合に限られます。SSDのメリットである高い精度を維持しつつ、自動運転向けの計算機でも実時間処理を行うためには、精度を出来るだけ維持したまま計算量を削減する手法が必要となります。
これを実現する手法の一つと考えられるのが、今回取り組んだMobileNetによる計算量削減です。
MobileNetについて
CNNの計算量を減らすことのできるMobileNetとは、いったいどのようなものなのでしょうか。
MobileNetの論文[1]では、その仕組みを以下のように紹介しています。
The MobileNet model is based on depthwise separable convolutions which is a form of factorized convolutions which factorize a standard convolution into a depthwise convolution and a 1×1 convolution called a pointwise convolution
つまり、MobileNetはCNNの畳み込み演算を、以下の画像のようにチャンネル方向が1(depthwise)の畳み込み演算と、空間方向が1(pointwise)の畳み込み演算に分解します。
 出典:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications[1]
出典:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications[1]
これにより計算量が削減される仕組みについては一旦置いておいて、まずはこれをSSDに組み込むことを考えてみます。
SSDのネットワークには多くの畳み込み層が含まれており、それらを全てMobileNetの畳み込み層に置き換えることでMobileNetの持つ軽量化の効果をSSDに取り入れることができます。このように作成したネットワークモデルを以降「MobileNet-SSD」と呼びます。
SSDとMobileNet-SSDの性能比較
では、MobileNet-SSDと通常のSSDを学習させ、実際に物体検出を行った時にどうなるのかを比較していきます。
SSDは入力画像サイズによりいくつか種類がありますが、今回はSSD300を使用することとし、Kerasの公開実装[2]をベースに実装を行いました。
また、以下の性能評価については「WIDER FACE: A Face Detection Benchmark」という顔検出用のデータセットを、学習用とテスト用に分割して用いました。
 出典:WIDER FACE: A Face Detection Benchmark – Multimedia Laboratory
出典:WIDER FACE: A Face Detection Benchmark – Multimedia Laboratory
推論速度
いくつかの計算機環境で推論処理の処理速度を計測した結果は以下のようになりました。
| 1080Ti [ms] | CPU [ms] | Jetson [ms] | |
|---|---|---|---|
| MobileNet-SSD | 12.37 | 35.16 | 26.41 |
| SSD300 | 16.83 | 171.18 | 80.87 |
1080TiはGeForce GTX 1080 Tiを、CPUはGPUを用いずIntel(R) Core(TM) i9-7900X CPU @ 3.30GHz(10コア)のみで計測したものを表しています。また、JetsonはNVIDIA Jetson Xavierを表しており、Nvpmodel Clock ConfigurationのModeを0にした状態で計測しました。
精度
テスト用の画像についてPrecision-Recall曲線(PR曲線)を作成した結果は以下のようになりました。
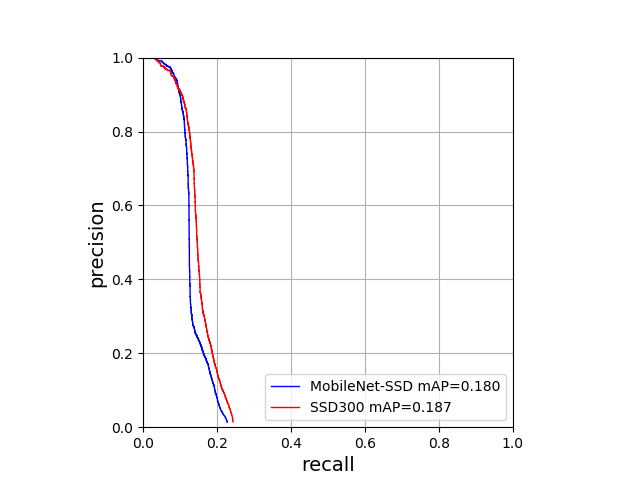
Precisionは検出結果がどの程度正解であるか、Recallは正解データをどの程度の割合で検出できているか、を表しています。そして、Mean Average Precision(mAP)はPR曲線の下側の面積をもとに計算される値で、モデルの精度を測る基準となります。
考察
推論速度
特に大きな差が生まれたのは、CPUでの推論速度です。SSDに対して、MobileNet-SSDの推論速度は5倍近く高速になっています。これはMobileNetの理論通り、演算量が削減されていることを意味しています。
一方で、1080Tiを用いた推論では、計算速度にCPUほどに大きな差は現れませんでした。これは1080TiはCUDAコア数の多いGPUを持ち、元のSSDにある大きいカーネルの畳み込みも並列処理により効率的に計算できることから、MobileNetの利点があまり生きないことが原因であると考えられます。
ただし、1080Tiと比べてGPUの並列計算能力が低いJetson Xavierでも計算時間が短縮されており、並列度の低い処理系ではMobileNetを組み込むことで高速化できることがわかります。
なお、今回は検討できませんでしたが、Jetson XavierはTensorRTを用いることができるため、SSDとMobileNet-SSDのいずれもここに示された時間より高速に処理することができると考えられます。
精度
今回のデータセットでは、マスクをした顔など検出困難な目標が多いこと、またSSD300を利用したため小さい顔の検出が難しかったことから、精度自体は両者ともにあまり良いとは言えない値になってしまいました。

ですが、この結果について両者を比較してみると、MobileNet-SSDはSSD300にわずかに精度が劣るものの、その差は小さく、ほぼ同じ正確さで物体を検出することが可能であることが分かります。
MobileNetは畳み込み層を分割することで計算量を減らす代わりに、表現力が元の畳み込みよりも低くなるため、通常のSSDよりも推論の精度が悪くなることが予想されたのですが、今回のデータセットに関してはほぼ同程度の検出能力を持つことがわかりました。
まとめ
これらの比較結果から、MobileNet-SSDはSSD300と比較して、
- CPUなど数値計算に特化していない処理装置を用いた推論速度が圧倒的
- 精度はわずかに劣るが、ほぼ同等の検出能力を持つ
という特徴があるといえます。
よって、SSDにMobileNetを組み込むことで、大きなデメリットなく計算量を減らし、GPUに頼らずとも高速に物体検出を行うことができるということがわかりました。
おわりに
今回の記事ではMobileNetで計算量が削減される理由を説明しきれなかったので、次の記事で理論的な背景を解説するとともに、理論に従い計算量が削減されていることを分析した結果についてご紹介したいと思います。
[1]Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam. (17 Apr 2017). “MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications”. Computer Vision and Pattern Recognition. view on https://arxiv.org/abs/1704.04861
[2] ssd_keras: https://github.com/pierluigiferrari/ssd_keras

Tags
About Author
TomiokaYusuke
Leave a Comment
Tags
Favorite Post

 2017年8月22日
2017年8月22日 2017年10月31日
2017年10月31日
Archives
- 2024年2月
- 2024年1月
- 2023年12月
- 2023年6月
- 2023年5月
- 2023年4月
- 2023年2月
- 2023年1月
- 2022年12月
- 2022年10月
- 2021年11月
- 2021年9月
- 2021年6月
- 2021年3月
- 2021年2月
- 2020年12月
- 2020年10月
- 2020年7月
- 2020年6月
- 2020年5月
- 2020年4月
- 2020年3月
- 2020年2月
- 2020年1月
- 2019年12月
- 2019年11月
- 2019年10月
- 2019年9月
- 2019年8月
- 2019年6月
- 2019年4月
- 2019年3月
- 2019年2月
- 2019年1月
- 2018年12月
- 2018年11月
- 2018年10月
- 2018年8月
- 2018年6月
- 2018年5月
- 2018年4月
- 2018年3月
- 2018年2月
- 2017年12月
- 2017年11月
- 2017年10月
- 2017年9月
- 2017年8月
- 2017年7月
- 2017年6月
- 2017年5月
- 2017年3月
- 2016年12月
- 2016年11月
- 2016年8月
- 2016年7月
- 2016年3月
- 2016年2月
- 2016年1月
- 2015年12月
- 2015年11月
- 2015年10月
- 2015年8月
- 2015年6月
- 2015年3月
- 2015年2月
- 2015年1月
- 2014年12月
- 2014年11月
コンピュータビジョンセミナーvol.2 開催のお知らせ - ニュース一覧 - 株式会社フィックスターズ in Realizing Self-Driving Cars with General-Purpose Processors 日本語版
[…] バージョンアップに伴い、オンラインセミナーを開催します。 本セミナーでは、�...
【Docker】NVIDIA SDK Managerでエラー無く環境構築する【Jetson】 | マサキノート in NVIDIA SDK Manager on Dockerで快適なJetsonライフ
[…] 参考:https://proc-cpuinfo.fixstars.com/2019/06/nvidia-sdk-manager-on-docker/ […]...
Windowsカーネルドライバを自作してWinDbgで解析してみる① - かえるのほんだな in Windowsデバイスドライバの基本動作を確認する (1)
[…] 参考:Windowsデバイスドライバの基本動作を確認する (1) - Fixstars Tech Blog /proc/cpuinfo ...
2021年版G検定チートシート | エビワークス in ニューラルネットの共通フォーマット対決! NNEF vs ONNX
[…] ONNX(オニキス):Open Neural Network Exchange formatフレームワーク間のモデル変換ツー�...
YOSHIFUJI Naoki in CUDAデバイスメモリもスマートポインタで管理したい
ありがとうございます。別に型にこだわる必要がないので、ユニバーサル参照を受けるよ...