このブログは、株式会社フィックスターズのエンジニアが、あらゆるテーマについて自由に書いているブログです。
Realizing Self-Driving Cars with General-Purpose Processors
Note: We will also be posting a Japanese version shortly.
※日本語版は後で公開します。
Abstract: Systems for self-driving cars have become available, but rely on hardware implementation of computer vision algorithms. Nevertheless, within the next few years it will become realistic to run in real time these most computationally intensive components entirely in software. To show this, we implemented and optimized a currently in production stereo-based segmentation algorithm for an existing embedded low power GPU. Presently, we achieve about 8 FPS at VGA resolution.

Advanced Driver Assistance Systems (ADAS) have received considerable attention over the past few years, eventually promising a fully autonomous driving experience. One major milestone was achieved at Daimler with their 6D-Vision system in 2013 when they incorporated it commercially into their Mercedes Benz E-Class and S-Class models. The version in those cars does not have full autonomy, but adaptive cruise control, collision avoidance, lane keeping assist, and other interesting features such as intelligent suspension control, a feature they named “MAGIC BODY CONTROL“, are included. More recently, this year, in May 2015, Freightliner (a subsidiary of Daimler) unveiled the Inspiration Truck, a model that can legally drive itself on the highways in the State of Nevada, based on the same 6D-Vision technology. Components of this system related to image processing are the most computationally expensive. According to information publicly available from their site, the overall dataflow of these components follows very roughly the diagram of Figure 1.
|
|
| Figure 1: Rough overall dataflow of image processing in the 6D-Vision system |
This system relies heavily on dense stereo camera processing, which computes the distance, for each pixel, in front of the camera. Although many accurate algorithms were already available, not until a method called Semi-Global Matching (SGM) was invented in 2005 could we consider creating sufficiently accurate real-time applications at about 30 FPS and more or less VGA (640×480) resolutions, something that researchers at Daimler achieved in 2008 on FPGA, hardware now available on the market.


Figure 2: Sample stereo images (left and right cameras, accordingly) from the Daimler Urban Segmentation Dataset
The stereo processing algorithm that previously provided the best balance between computational complexity, robustness, and accuracy was the simple scheme known as block matching. Even though other methods based on algorithms such dynamic programming, belief propagation, and graph cuts have been studied over the years, none have proven to be as robust or accurate as SGM with the same level of computational efficiency. Although SGM is about an order of magnitude more expensive than traditional block matching, the gains in robustness and accuracy are well worth the additional computational cost. Indeed, the 6D-Vision system depends on the robustness achieved with SGM.


Figure 3: Results from stereo processing of images from Figure 2 with OpenCV’s block matching (left) and
our implementation of SGM (right): brightness proportional to
disparity and black where unknown
 |
| Figure 4: Example of block matching stereo, with a window around pixel (x,y) in the left image, and the best matching window around (x*,y) in the right image |
The traditional block matching algorithm tries to match each pixel of the left image with a pixel in the right image by comparing the content inside a local window (for example, a 9×9 square) around the pixel: the matching cost. By properly rectifying the images, the epipolar constraint guarantees that the pixels are going to have the same y-coordinates, so we need only to scan along the x-axis inside, by convention, the right image as shown in Figure 4. The window around the pixel at (x*,y) that we seek minimizes the matching cost and provides the disparity measurement d in x-coordinates. Because disparity is inversely proportional to depth, where closer objects have larger disparities, we refer to the output commonly as the depth image.
 |
| Figure 5: The 8 directions over which stereo SGM computes the smoothing cost for the pixel at (x,y) |
However, as we can see in the example image of Figure 3, we obtain a lot of discontinuities and holes. One way to alleviate that is via regularization, otherwise known as smoothing. Traditional schemes, such as graph cuts and belief propagation, try to regularize globally, but are unable to obtain good results in real time. The idea of regularizing “semi-globally” was revolutionary. In a nutshell, instead of trying to create smooth surfaces globally over the whole image, it minimizes only along 8 or so directions at each pixel, as illustrated in Figure 5. In a manner similar to block matching, we still minimize a matching cost, but to compensate for instances when it is not strong enough, such as inside smooth textureless surfaces, like roads, or for repetitive textures, as occurs with guardrails, we minimize it along with a smoothing cost. With an accurately calibrated stereo camera, the output thus obtained even compares favorably to 3D point clouds measured via LIDAR.
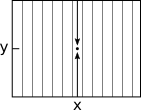 |
| Figure 6: The only 2 vertical directions over which segmentation SGM computes the smoothing cost for the pixel at (x,y) |
Once we have dense depth information, the next step consists in segmenting the scene in two main classes: objects and road. Objects appear mostly vertical in depth, while the road is mostly horizontal, but it appears with a slant that depends on the pitch of the camera, as can be seen from the depth images of Figure 3. The basic idea for segmenting the scene, is first to apply a horizontal median filter on the image along each column, 5 or 10 pixels wide, effectively reducing the width of the image, the noise, and the amount of data to process, while keeping its height intact. Then we apply another cost minimization function to each vertical column independently, as shown in Figure 6. The total cost function again features the matching cost (the difference between measured depth and the modeled depth of objects or road) as well as a complex smoothing cost that models prior information about road scenes in general. The algorithm then finds the configuration of objects and road, for each pixel, that minimizes the sum of the cost functions. In the original system, dynamic programming was used to reduce the cost, but we found that SGM could also be applied effectively in this case as well. Although dynamic programming is optimal for one-dimensional optimization problems, meaning that SGM is not required, we believe that using SGM for both stereo and segmentation should reduce implementation efforts, whether done in either software or hardware.
 |
| Figure 7: Typical output obtained with segmentation SGM and the sample images above: closer objects are red, farther ones are green, and the road is transparent |
Even though most of the implementations of this system available on the market are in FPGA, it will become possible over the coming years to commercialize solutions implemented fully in software, removing the effort required to customize hardware. To prove our point, we have implemented and accelerated the algorithms above for the low power (less than 10 W) GPU found on the NVIDIA Tegra X1, and placed the results in Table 1. Given these numbers and NVIDIA’s roadmap over the next 5 years, it should become possible to run at the very least these two algorithms on GPU in real time at VGA (640×480) resolution by some time around 2020. For embedded applications, we feel that being able to implement entirely in software and execute in real time algorithms with such a high computational cost should give many new players, including Fixstars itself, access to the ADAS industry.
| Width x Height x Max Disparity | Average processing time (ms) | |
| 640x480x64 | 1024x440x128 | |
| Stereo SGM | 80 | 282 |
| Segmentation SGM | 39 | 42 |
| Table 1: Current performance results per frame obtained for stereo and segmentation (of columns of 5 and 10 pixels, respectively) with SGM on Tegra X1 |
||
For now, we provide below a demo video obtained by processing the “test_2” left and right camera images from the freely downloadable Daimler Urban Segmentation Dataset. For easier interpretation, the segmented objects are merged together using contour processing and warning signs are also displayed for the ones that are large enough and close enough to the camera. Please note that, for this demo, we prioritized speed over accuracy of segmentation. The original algorithm for segmentation SGM provides less noisy detection, but is harder to parallelize, thus leaving much room for improvement. Moreover, because our system does not yet track objects, it cannot know whether a moving object is on a collision course or not.
Before objects can be tracked though, we first need to obtain a dense estimate of the optical flow. Traditionally, one would use two algorithms together to obtain both robustness and accuracy: a global sparse scheme based on feature points and descriptors (CENSUS, SIFT, etc) along with a local refinement stage (TV-L1, graph cuts, etc). Instead, we have started to tackle this problem using only one algorithm known as flow SGM, which was also derived from stereo SGM in a similar fashion to our own segmentation SGM. We hope this way to reduce the complexity of the overall system, by allowing us to reuse code from stereo and segmentation SGM, while obtaining results equivalent to traditional methods. We have started to experiment with it and preliminary results are promising. We plan to post our findings in a later installment of this blog.
– The “SGM Team”: Samuel Audet, Yoriyuki Kitta, Yuta Noto, Ryo Sakamoto, Akihiro Takagi

Tags
About Author
saudet
Leave a Comment
Tags
Favorite Post

 2023年1月27日
2023年1月27日 2017年8月22日
2017年8月22日
Archives
- 2025年5月
- 2025年4月
- 2024年11月
- 2024年10月
- 2024年7月
- 2024年5月
- 2024年4月
- 2024年2月
- 2024年1月
- 2023年12月
- 2023年6月
- 2023年5月
- 2023年4月
- 2023年2月
- 2023年1月
- 2022年12月
- 2022年10月
- 2021年11月
- 2021年9月
- 2021年6月
- 2021年3月
- 2021年2月
- 2020年12月
- 2020年10月
- 2020年7月
- 2020年6月
- 2020年5月
- 2020年4月
- 2020年3月
- 2020年2月
- 2020年1月
- 2019年12月
- 2019年11月
- 2019年10月
- 2019年9月
- 2019年8月
- 2019年6月
- 2019年4月
- 2019年3月
- 2019年2月
- 2019年1月
- 2018年12月
- 2018年11月
- 2018年10月
- 2018年8月
- 2018年6月
- 2018年5月
- 2018年4月
- 2018年3月
- 2018年2月
- 2017年12月
- 2017年11月
- 2017年10月
- 2017年9月
- 2017年8月
- 2017年7月
- 2017年6月
- 2017年5月
- 2017年3月
- 2016年12月
- 2016年11月
- 2016年8月
- 2016年7月
- 2016年3月
- 2016年2月
- 2016年1月
- 2015年12月
- 2015年11月
- 2015年10月
- 2015年8月
- 2015年6月
- 2015年3月
- 2015年2月
- 2015年1月
- 2014年12月
- 2014年11月
keisuke.kimura in Livox Mid-360をROS1/ROS2で動かしてみた
Sorry for the delay in replying. I have done SLAM (FAST_LIO) with Livox MID360, but for various reasons I have not be...
Miya in ウエハースケールエンジン向けSimulated Annealingを複数タイルによる並列化で実装しました
作成されたプロファイラがとても良さそうです :) ぜひ詳細を書いていただきたいです!...
Deivaprakash in Livox Mid-360をROS1/ROS2で動かしてみた
Hey guys myself deiva from India currently i am working in this Livox MID360 and eager to knwo whether you have done the...
岩崎システム設計 岩崎 満 in Alveo U50で10G Ethernetを試してみる
仕事の都合で、検索を行い、御社サイトにたどりつきました。 内容は大変参考になりま�...
Prabuddhi Wariyapperuma in Livox Mid-360をROS1/ROS2で動かしてみた
This issue was sorted....