このブログは、株式会社フィックスターズのエンジニアが、あらゆるテーマについて自由に書いているブログです。
Vivado の合成/インプリメンテーションストラテジを変えてみる(WNS・走行時間編)
はじめに
Xilinx の FPGA 開発ツール である Vivado® は、合成/インプリメンテーションそれぞれにストラテジを持ちます。 ug904 によると、ストラテジとは以下のことを指します。
ストラテジは、デザインの合成またはインプリメンテーションで最適な結果が得られるようにするために定義されたソリューションです。 Vivado インプリメンテーション機能のあらかじめ設定されたオプションにより定義されます。 ストラテジは、ツールおよびバージョン特定です。 各メジャーリリースには、そのバージョン専用のストラテジがあります。
つまり、ストラテジについては、以下のことが言えそうです。
- Xilinx が用意してくれている合成/インプリメンテーションのオプションである。
- ストラテジを変化させると合成/インプリメンテーション結果が異なる。
本稿では、手元にあるそれなりの規模のデザインを使って実際にストラテジを振ってみて、合成/インプリメンテーション結果がどう変わるかを見てみます。 以下に、合成ストラテジ 8 種類、インプリメンテーションストラテジ 28 種類(本稿執筆中に気がつきましたが、Performance_EarlyBlockPlacement についての実験が抜けていたようです)の全組み合わせを試したときのタイミング、合成/インプリメンテーション走行時間についてまとめます。 リソース使用率やその他の結果については別稿に譲ります。
言うまでもなく、(定量的に示すことはできませんが)合成/インプリメンテーション結果は大部分がデザインに依存していると思われます。 ここで示される結果やその傾向が、全てのデザインのそれらに現れるとは言えません。 本稿の結果は、あくまで参考程度に見てください。 あらゆる合成/インプリメンテーション収束の助けにはなるとは言えませんが、ストラテジを変えてみたら問題は解決するかも、というときに本稿が役に立つかもしれません。
本稿は Vivado 2017.4 を使用することを想定して書かれています。他のバージョンをご利用の場合は適宜読み替えが必要になる可能性があることをご了承下さい。
ストラテジの種類
まずは、ストラテジにはどんなものがあるのか、について見てみます。 前述の通り、ストラテジは合成/インプリメンテーションそれぞれに存在し、それらは Vivado のバージョン固有のものです。 使用している Vivado にどんなストラテジが定義されているかは [Tools] → [Settings] の [Tool Settings] → [Strategies] → [RunStrategies] で確認できます。 Flow ドロップダウンリストで Synthesis もしくは Implementation を選ぶと、それぞれに定義されたストラテジを確認できます。 Options では、synth などのコマンドに対してどのようなオプションが渡されるかを見ることができます。 ストラテジを変えると-fanout_limitや -directive などオプションの引数が変わるのがわかります。
合成/インプリメンテーションのストラテジとその説明を以下にそれぞれ示します。
- 以下の表は合成のストラテジとその説明 (Vivado 2017.4 の Description から抜粋) を示します。 ug901 にストラテジを構成する各オプションの値について詳細に記載してあります。
| ストラテジ名 | 説明 |
|---|---|
| Vivado Synthesis Defaults | Vivado Synthesis Defaults |
| Flow_AreaOptimized_high | Performs general area optimizations including changing the threshold for control set optimizations, forcing ternary adder implementation, applying lower thresholds for use of carry chain in comparators and also area optimized mux optimizations. |
| Flow_AreaOptimized_medium | Performs general area optimizations including changing the threshold for control set optimizations, forcing ternary adder implementation, lowering multiplier threshold of inference into DSP blocks, moving shift register into BRAM, applying lower thresholds for use of carry chain in comparators and also area optimized mux optimizations |
| Flow_AreaMultThresholdDSP | Default options plus the AreaMultThresholdDSP directive which will lower the threshold for inference of multipliers into DSP blocks |
| Flow_AlternateRoutability | Performs optimizations which creates alternative logic technology mapping, including disabling LUT combining, forcing F7/F8/F9 to logic, increasing the threshold of shift register inference. |
| Flow_PerfOptimized_high | Higher performance designs, resource sharing is turned off, the global fanout guide is set to a lower number, FSM extraction forced to one-hot, LUT combining is disabled, equivalent registers are preserved, SRL are inferred with a larger threshold |
| Flow_PerfThresholdCarry | Default options plus the FewerCarryChains directive for less inference of carry chains, turning off the LUT combining, resource sharing off, retaining equivalent registers |
| Flow_RuntimeOptimized | Trades off Performance and Area for better Runtime. |
- インプリメンテーションのストラテジとその説明は ug904 の p.163「表 C-2:インプリメンテーションストラテジの説明」を参照してください。
以上の表から、ストラテジは設計者が Vivado にどういう合成/インプリメンテーション結果を求めるかを示唆するものであると言えそうです。 以下に、実際に試してみた結果を示します。
実験
実験環境
- OS: CentOS 7 (3.10.0-862.el7.x86_64)
- Vivado: v2017.4 (64-bit)
デザイン
以下に今回の実験対象となるデザインの情報を示します。
| 項目 | 値 |
|---|---|
| 目標周波数 | 250 MHz |
| ターゲットデバイス | VU3P |
| 設計したデザインの RTL 行数 | 約 30000 行 |
| デザインに含まれる IP 数 | 112 個 |
- ターゲットデバイスである VU3P は、Virtex UltraScale+ の中では最も小さいデバイスです。
- RTL 行数は、単純に
wc -lしたものです。 内部でgenerateなど使っていたり、モジュールを複数インスタンスしたり、ラッパーなどもあるのでこれだけでデザインの規模を語ることはナンセンスですが、参考程度に。 大部分は、1 モジュール 1 インスタンスです。 - IP 数は OOC フローが独立に走るモジュールの数を示しています。
実験方法
本稿末尾の付録にある TCL スクリプトを使用して、合成ストラテジ 8 種類とインプリメンテーションストラテジ 28 種類の全組み合わせで合成/インプリメンテーションを実行します。 プロジェクトを開いた後に TCL スクリプトを source し ImplTrial::launchRun で実行できます。 一番初めの全体合成前に、各モジュールまたは IP は、OOC モジュールとして合成されます。
実験結果
ここから実験結果を見ていきます。 縦軸にインプリメンテーションストラテジ、横軸に合成ストラテジを取った表を示していきます。 値が空のセルは、対応するストラテジでは合成またはインプリメンテーションが完了できなかったことを示します。
Worst Negative Slack
まずは、WNS についての表です。以下のリンク先画像に示します。画像中のグレイアウトしている組み合わせは、エラーによりインプリメンテーションが成功しなかったものです。 WNS だけでなく、以降の指標における表のグレイアウトの意味は同じです。その他のセルの色の意味ですが、0.000 を白として緑は Positive slack、赤は Negative slack を示します。色が濃いほど絶対値が大きくなります。
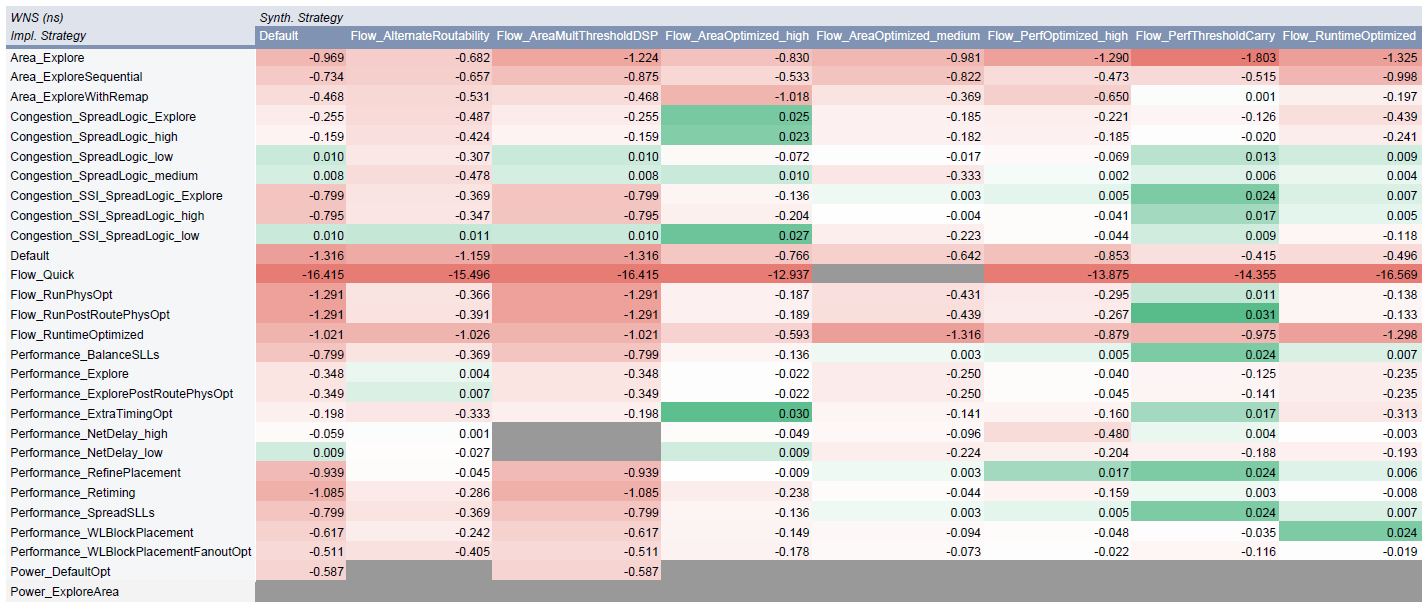
最も WNS が大きいものは 0.031 ns であり、合成のストラテジが Flow_PerfThresholdCarry、インプリメンテーションのストラテジが Flow_RunPostRoutePhysOpt の組み合わせになりました。 ここで、それぞれのストラテジの意味をもう一度見てみます。
合成ストラテジ Flow_PerfThresholdCarry の説明は以下のとおりです。
Default options plus the FewerCarryChains directive for less inference of carry chains, turning off the LUT combining, resource sharing off, retaining equivalent registers.
説明によると、キャリーチェーンや LUT の結合、リソースの共有などの推論を弱くするストラテジなようです。 使用可能な領域が大きく、論理が広大な範囲に広がるデザインであれば、パフォーマンスに良い影響を与えそうなストラテジに見えます。
インプリメンテーションストラテジ Flow_RunPostRoutePhysOpt の説明は以下のとおりです。
Flow_RunPhysOpt と同様ですが、配線後の物理最適化段階を-directive Explore オプションで実行します。
Flow_RunPostRoutePhysOpt のサブセットである Flow_RunPhysOpt の説明は以下のとおりです。
Vivado Implementation Defaults と同様ですが、物理最適化 (phys_opt_design) を実行します。
Flow_RunPhysOpt のサブセットである Vivado Implementation Defaults の説明は以下のとおりです。
適度な実行時間でタイミングクロージャが満たされるようにします。
説明によると、このインプリメンテーションのストラテジは、デフォルトに加えて配置後/配線後それぞれに最適化を複数回行うものです。ug904, p166, 表 C-3, C-4 より
以上をまとめます。 今回のデザインにおいては、上記ストラテジのペアが最も良い結果を生みました。 このデザインは、多量の配線がいっせいに論理を取るような場所があり、合成ストラテジ Flow_PerfThresholdCarry がうまく機能するデザインであったことが良い結果を生む要因だったと考えられます(リソース共有など配線が一箇所に固まることをなるべく排除してくれたと仮定して)。 この合成ストラテジのその他のインプリメンテーション結果を見てみても (表の Flow_PerfThresholdCarry の列)、その他の合成ストラテジよりタイミング MET している結果が多く、比較的良いパフォーマンスを出しています。 合成ストラテジがインプリメンテーション結果に与える影響は小さくないと言えます。
一方、最良の結果を生んだインプリメンテーションのストラテジ Flow_RunPostRoutePhysOpt について見てみると(表の Flow_RunPostRoutePhysOpt の行)、合成ストラテジ Flow_PerfThresholdCarry 以外では全てタイミングが MET していないことがわかります。 WNS の数値を見てみると、あと少しで MET できそう、というよりは全く駄目駄目だな、といった感じです。 回路デザインと合成ストラテジとインプリメンテーションストラテジの三者間に相性みたいなものがあるのかもしれません。
走行時間
続いて、走行時間です。表は以下のリンク先画像にあります。ここでは、走行時間とその走行結果 (WNS) を並べています。緑色のセルはタイミングが MET したストラテジの組み合わせを示します。
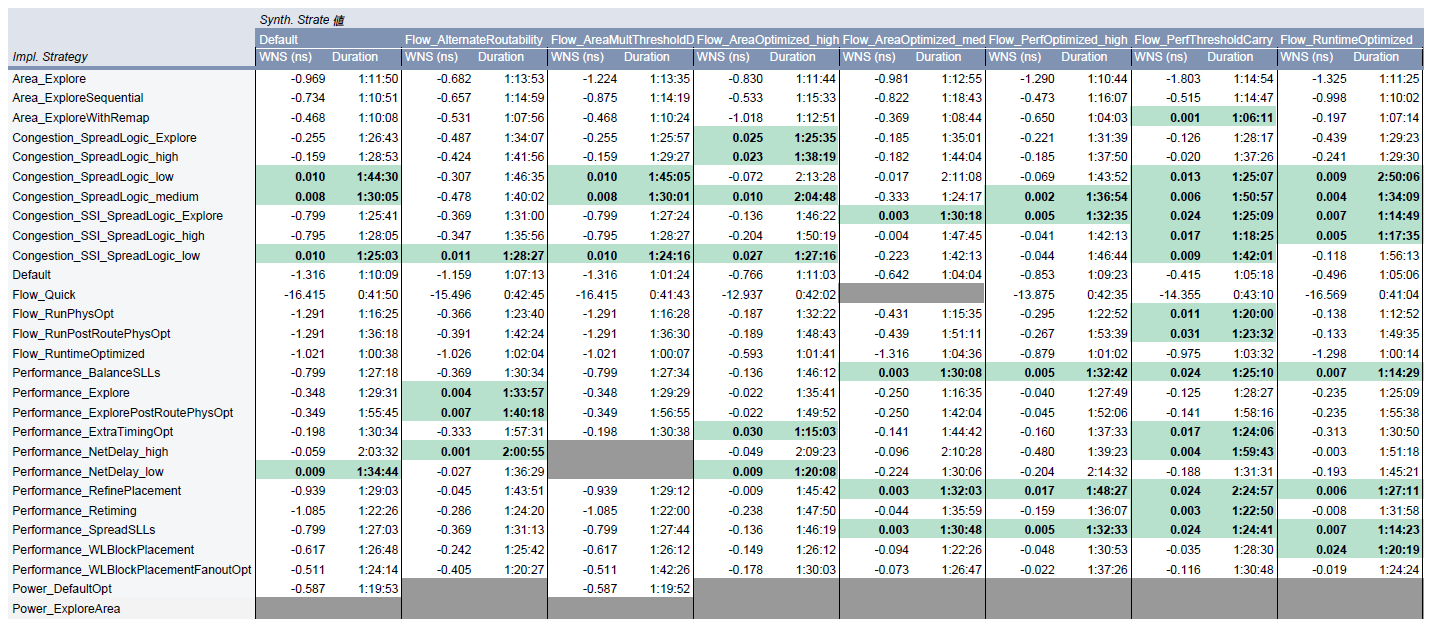
- 最も良い WNS を出したペア (Flow_PerfThresholdCarry, Flow_RunPostRoutePhysOpt) は 1:23:32 となっています。その他タイミングが MET した走行の時間もだいたい 1 時間から 2 時間程度に収まっています。
- タイミングが MET しなかった走行では、なんとか MET させようとするため走行時間が長くなりがちである、という予想をしていましたが、ざっと見たところこの結果からはそういう傾向は見られません。
さいごに
本稿では、Vivado 2017.4 が持つストラテジについて紹介しました。 また、合成/インプリメンテーションそれぞれに複数のストラテジがあり、それらの組み合わせでインプリメンテーション結果がどう変わるかを示しました。 今回のデザインにおいては以下のような結果が得られました。
- WNS は、(Flow_PerfThresholdCarry, Flow_RunPostRoutePhysOpt) という 2 つのストラテジの組み合わせにおいて WNS 0.031 ns を達成しました。
- 走行時間は、上記最良の結果を生んだもので 1:23:32 でした。
デザインの特徴から推測して合成のストラテジを決めることは、良いインプリメンテーション結果を生む近道になりえますが、一方、悪い結果を引き起こすことにもなります。 デザインの序盤〜中盤では、ストラテジを振ってタイミングクロージャを実施するのではなく、論理の変更によりタイミングクロージャを図るべきでしょう。 インプリメンテーションの実験結果からわかるように、2 回以上の最適化がより良い結果を必ず生むとは限りません。 開発 TAT を重視しデフォルト + alpha くらいのストラテジにする、という戦略も効果的だと言えます。 デザイン中盤〜終盤でデザインがほとんど固まってきたら、本実験のようにストラテジを振ってみて、設計者が望むより良い結果を生むストラテジを探してみる、というのは省電力化やインプリメンテーション時間削減による TAT 短縮、更なるタイミング改善などの面で有効であると言えます。
一方、新たな知見として、合成ストラテジがインプリメンテーション結果に小さくない影響を与えるということがわかりました。 今回は調査できていませんが、合成後インプリメンテーション前の WNS を、インプリメンテーション後の WNS と突き合わせてみると、何らかの傾向が見られるかもしれません。
繰り返しになりますが、上記の結果はあくまで今回実験に用いたデザインにおいて見られるものです。 あらゆるデザインについて同じ結果/傾向が見られることはありえないと思いますが、合成/インプリメンテーションの参考になれば幸いです。
将来的なネタとして、合成後の WNS とインプリメンテーション後の WNS の比較や、リソースの使用率、新しい版の Vivado での結果についても調査してみたいと思います。
参考
- Xilinx, Vivado Design Suite ユーザーガイド 合成 UG901 (v2017.4) 2017 年 12 月 20 日, https://www.xilinx.com/support/documentation/sw_manuals_j/xilinx2017_4/ug901-vivado-synthesis.pdf
- Xilinx, Vivado Design Suite ユーザーガイド インプリメンテーション UG904 (v2017.4) 2017 年 12 月 20 日, https://www.xilinx.com/support/documentation/sw_manuals_j/xilinx2017_4/ug904-vivado-implementation.pdf
付録
今回の実験で使った TCL スクリプトを以下に示します。 このスクリプトをファイルに保存して Vivado 2017.4 から source すれば今回の実験と同様のことができます。 改善すべきところはありますが、機会があれば使ってみてください。
namespace eval ImplTrial {
set version 2017
set coreNum 8
proc getCurDateTime {} {
return [clock format [clock seconds]]
}
namespace eval Synth {
set flow "Vivado Synthesis ${ImplTrial::version}"
namespace eval Strategy {
set Default {}
set Flow_AreaOptimized_high {Flow_AreaOptimized_high}
set Flow_AreaOptimized_medium {Flow_AreaOptimized_medium}
set Flow_AreaMultThresholdDSP {Flow_AreaMultThresholdDSP}
set Flow_AlternateRoutability {Flow_AlternateRoutability}
set Flow_PerfThresholdCarry {Flow_PerfThresholdCarry}
set Flow_PerfOptimized_high {Flow_PerfOptimized_high}
set Flow_RuntimeOptimized {Flow_RuntimeOptimized}
}
set strategies [list \
$Strategy::Default \
$Strategy::Flow_AreaOptimized_high \
$Strategy::Flow_AreaOptimized_medium \
$Strategy::Flow_AreaMultThresholdDSP \
$Strategy::Flow_AlternateRoutability \
$Strategy::Flow_PerfThresholdCarry \
$Strategy::Flow_PerfOptimized_high \
$Strategy::Flow_RuntimeOptimized]
proc launchRun {index} {
set name synth_s${index}
puts "--------------------------------------------------------------------------------"
puts "| ${name} began @ [ImplTrial::getCurDateTime]"
puts "--------------------------------------------------------------------------------"
variable flow
variable strategies
create_run ${name} -flow ${flow} -strategy [lindex ${strategies} ${index}]
launch_runs ${name} -jobs ${ImplTrial::coreNum}
wait_on_run ${name}
puts "--------------------------------------------------------------------------------"
puts "| ${name} finished @ [ImplTrial::getCurDateTime]"
puts "--------------------------------------------------------------------------------"
}
}
namespace eval Implementation {
set flow "Vivado Implementation ${ImplTrial::version}"
namespace eval Strategy {
set Default {}
set Performance_Explore {Performance_Explore}
set Performance_ExplorePostRoutePhysOpt {Performance_ExplorePostRoutePhysOpt}
set Performance_WLBlockPlacement {Performance_WLBlockPlacement}
set Performance_WLBlockPlacementFanoutOpt {Performance_WLBlockPlacementFanoutOpt}
set Performance_NetDelay_high {Performance_NetDelay_high}
set Performance_NetDelay_low {Performance_NetDelay_low}
set Performance_Retiming {Performance_Retiming}
set Performance_ExtraTimingOpt {Performance_ExtraTimingOpt}
set Performance_RefinePlacement {Performance_RefinePlacement}
set Performance_SpreadSLLs {Performance_SpreadSLLs}
set Performance_BalanceSLLs {Performance_BalanceSLLs}
set Congestion_SpreadLogic_high {Congestion_SpreadLogic_high}
set Congestion_SpreadLogic_medium {Congestion_SpreadLogic_medium}
set Congestion_SpreadLogic_low {Congestion_SpreadLogic_low}
set Congestion_SpreadLogic_Explore {Congestion_SpreadLogic_Explore}
set Congestion_SSI_SpreadLogic_high {Congestion_SSI_SpreadLogic_high}
set Congestion_SSI_SpreadLogic_low {Congestion_SSI_SpreadLogic_low}
set Congestion_SSI_SpreadLogic_Explore {Congestion_SSI_SpreadLogic_Explore}
set Area_Explore {Area_Explore}
set Area_ExploreSequential {Area_ExploreSequential}
set Area_ExploreWithRemap {Area_ExploreWithRemap}
set Power_DefaultOpt {Power_DefaultOpt}
set Power_ExploreArea {Power_ExploreArea}
set Flow_RunPhysOpt {Flow_RunPhysOpt}
set Flow_RunPostRoutePhysOpt {Flow_RunPostRoutePhysOpt}
set Flow_RuntimeOptimized {Flow_RuntimeOptimized}
set Flow_Quick {Flow_Quick}
}
set strategies [list \
$Strategy::Default \
$Strategy::Performance_Explore \
$Strategy::Performance_ExplorePostRoutePhysOpt \
$Strategy::Performance_WLBlockPlacement \
$Strategy::Performance_WLBlockPlacementFanoutOpt \
$Strategy::Performance_NetDelay_high \
$Strategy::Performance_NetDelay_low \
$Strategy::Performance_Retiming \
$Strategy::Performance_ExtraTimingOpt \
$Strategy::Performance_RefinePlacement \
$Strategy::Performance_SpreadSLLs \
$Strategy::Performance_BalanceSLLs \
$Strategy::Congestion_SpreadLogic_high \
$Strategy::Congestion_SpreadLogic_medium \
$Strategy::Congestion_SpreadLogic_low \
$Strategy::Congestion_SpreadLogic_Explore \
$Strategy::Congestion_SSI_SpreadLogic_high \
$Strategy::Congestion_SSI_SpreadLogic_low \
$Strategy::Congestion_SSI_SpreadLogic_Explore \
$Strategy::Area_Explore \
$Strategy::Area_ExploreSequential \
$Strategy::Area_ExploreWithRemap \
$Strategy::Power_DefaultOpt \
$Strategy::Power_ExploreArea \
$Strategy::Flow_RunPhysOpt \
$Strategy::Flow_RunPostRoutePhysOpt \
$Strategy::Flow_RuntimeOptimized \
$Strategy::Flow_Quick]
proc launchRun {index_s index_i} {
set impl_name impl_${index_s}_${index_i}
set synth_name synth_s${index_s}
puts "--------------------------------------------------------------------------------"
puts "| ${impl_name} began @ [ImplTrial::getCurDateTime]"
puts "--------------------------------------------------------------------------------"
variable flow
variable strategies
create_run ${impl_name} -parent_run ${synth_name} -flow ${flow} -strategy [lindex ${strategies} ${index_i}]
launch_runs ${impl_name} -to_step write_bitstream -jobs ${ImplTrial::coreNum}
wait_on_run ${impl_name}
puts "--------------------------------------------------------------------------------"
puts "| ${impl_name} finished @ [ImplTrial::getCurDateTime]"
puts "--------------------------------------------------------------------------------"
}
}
proc launchRun {} {
puts "================================================================================"
puts "| ImplTrial::laucnRun began @ [ImplTrial::getCurDateTime]"
puts "================================================================================"
for {set i 0} {$i < [llength ${Synth::strategies}]} {incr i} {
Synth::launchRun $i
for {set j 0} {$j < [llength ${Implementation::strategies}]} {incr j} {
Implementation::launchRun $i $j
}
}
puts "================================================================================"
puts "| ImplTrial::laucnRun finished @ [ImplTrial::getCurDateTime]"
puts "================================================================================"
}
}
Tags
About Author
kodai.moritaka
1件のコメント
Leave a Comment
Tags
Favorite Post

 2023年1月27日
2023年1月27日 2017年8月22日
2017年8月22日
Archives
- 2025年5月
- 2025年4月
- 2024年11月
- 2024年10月
- 2024年7月
- 2024年5月
- 2024年4月
- 2024年2月
- 2024年1月
- 2023年12月
- 2023年6月
- 2023年5月
- 2023年4月
- 2023年2月
- 2023年1月
- 2022年12月
- 2022年10月
- 2021年11月
- 2021年9月
- 2021年6月
- 2021年3月
- 2021年2月
- 2020年12月
- 2020年10月
- 2020年7月
- 2020年6月
- 2020年5月
- 2020年4月
- 2020年3月
- 2020年2月
- 2020年1月
- 2019年12月
- 2019年11月
- 2019年10月
- 2019年9月
- 2019年8月
- 2019年6月
- 2019年4月
- 2019年3月
- 2019年2月
- 2019年1月
- 2018年12月
- 2018年11月
- 2018年10月
- 2018年8月
- 2018年6月
- 2018年5月
- 2018年4月
- 2018年3月
- 2018年2月
- 2017年12月
- 2017年11月
- 2017年10月
- 2017年9月
- 2017年8月
- 2017年7月
- 2017年6月
- 2017年5月
- 2017年3月
- 2016年12月
- 2016年11月
- 2016年8月
- 2016年7月
- 2016年3月
- 2016年2月
- 2016年1月
- 2015年12月
- 2015年11月
- 2015年10月
- 2015年8月
- 2015年6月
- 2015年3月
- 2015年2月
- 2015年1月
- 2014年12月
- 2014年11月
-
keisuke.kimura in Livox Mid-360をROS1/ROS2で動かしてみた
Sorry for the delay in replying. I have done SLAM (FAST_LIO) with Livox MID360, but for various reasons I have not be...
-
Miya in ウエハースケールエンジン向けSimulated Annealingを複数タイルによる並列化で実装しました
作成されたプロファイラがとても良さそうです :) ぜひ詳細を書いていただきたいです!...
-
Deivaprakash in Livox Mid-360をROS1/ROS2で動かしてみた
Hey guys myself deiva from India currently i am working in this Livox MID360 and eager to knwo whether you have done the...
-
岩崎システム設計 岩崎 満 in Alveo U50で10G Ethernetを試してみる
仕事の都合で、検索を行い、御社サイトにたどりつきました。 内容は大変参考になりま�...
-
Prabuddhi Wariyapperuma in Livox Mid-360をROS1/ROS2で動かしてみた
This issue was sorted....
VivaoにはISEにあったSmartXplorerが無くなったので、これを手でやる必要があるのが面倒なんですよね
インプリメント時間は2018.3~2019.1でかなり早くなったので、傾向は変わってるかもしれません