このブログは、株式会社フィックスターズのエンジニアが、あらゆるテーマについて自由に書いているブログです。
GpuMatの内部を探検してみる
はじめに
OpenCVにはGpuMatというCUDA実装を行うためのデータ構造が用意されており、CUDAを使って実装された各種アルゴリズムもcudaモジュールという形で提供されています(※詳細は公式ドキュメントを参照ください)。
この記事ではGpuMat内部で行われている処理とGpuMatを使う上でのTipsをいくつか紹介します。特に
- OpenCVにあるCUDA実装を読めるようになりたい
- GpuMatと自作CUDAコードを組み合わせたい
という方には参考になるかもしれません。
前置き
まずは、cudaimgprocモジュールの
cv::cuda::cvtColor(d_src, d_dst, cv::COLOR_BGR2GRAY);を呼ぶだけの単純なプログラムを実行して、Nsightで見てみましょう。
すると、以下のようなCUDAカーネルが動いていることがわかります。
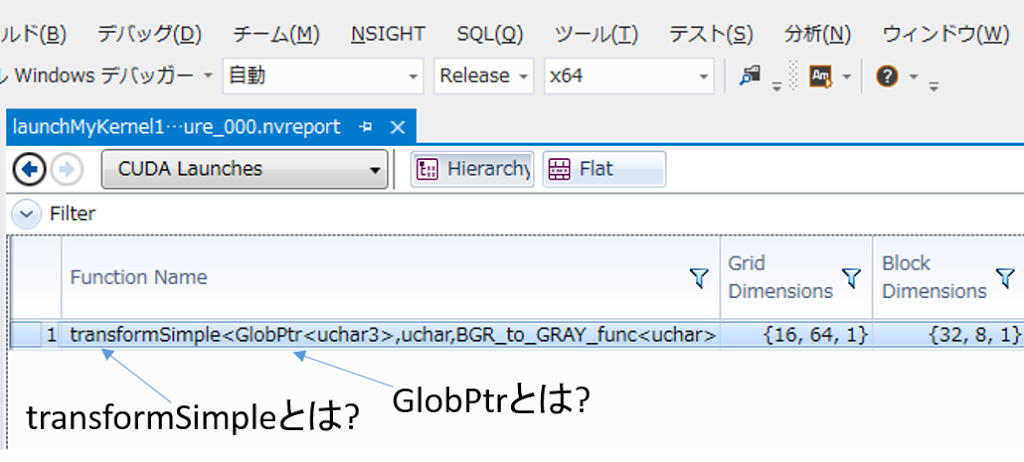
これを見るとtransformSimple、GlobPtrという見覚えのない文字列が出てきて戸惑うかもしれませんね(私は初見でかなり戸惑いました・・・)。ただ、この記事を読み終わる頃にはこれらのパラメータの意味がわかるようになっているはずです。
インスタンス生成
GpuMatクラスのインスタンス生成でよく使う方法を紹介します。
以下はrows、cols、typeの順に指定する例です(この初期化方法では、width、heightの順ではなく、rows、colsの順である点に注意が必要です)。
cv::cuda::GpuMat d_img(240, 320, CV_8UC1);次にサイズ(width、height)、typeの順に指定する例です。
cv::cuda::GpuMat d_img(cv::Size(320, 240), CV_8UC1);次にホスト側のimgと同じ画像バッファの値を持ったGpuMatのインスタンスを生成する例です。
cv::Mat img(cv::Size(320, 240), CV_8UC1);
cv::cuda::GpuMat d_img(img);
データ転送
ホスト、デバイス間のデータ転送はGpuMatクラスのupload、downloadメソッドを用います。uploadメソッドがホスト→デバイスの転送、uploadメソッドがデバイス→ホストの転送を行うメソッドとなっています。
cv::Mat img(cv::Size(320, 240), CV_8UC1);
cv::cuda::GpuMat d_img(src1.size(), src1.type());
d_img.upload(img); //ホストからデバイスに転送
d_img.download(img); //デバイスからホストに転送
download、uploadメソッドは、内部的にはcudaMemcpy2Dを呼んでいるだけです。ただし、download、uploadメソッドの引数としてstreamを指定した場合はcudaMemcpy2DAsyncが呼ばれます。
cudaモジュールの内部実装
全ての実装がこうなっているというわけではありませんが、cudaモジュールで提供されるAPIの内部処理をおおまかにまとめると以下のような感じになっています。
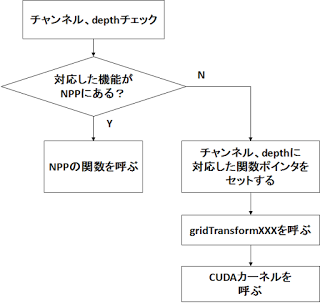
プリミティブな処理に関しては何気にNPP(NVIDIA Performance Primitives library)に投げていたりします。また、この図に突然出てきたgridTransformについては後ほど述べることとします。そのため、この時点ではそういうものがあるんだなという理解でOKです。
cudevモジュール
CUDAカーネルを書く上でよく用いるデータ構造、処理などはcudevモジュールにまとまっています。
ここではその中でも重要なものについてピックアップして紹介します。
GlobPtrSz構造体
CUDAカーネルの引数として画像バッファ、width、height、strideなどを渡すことが多いと思います。
これらを一つ一つカーネル引数で渡すとカーネル引数が煩雑になりがちです。
cudevモジュールではこれらのパラメータをまとめたGlobPtrSz構造体が提供しています。
文章だけだとピンとこないと思いますのでサンプルコードを交えながら紹介します。
GlobPtrSz構造体を生成するサンプルコード
cv::cudev::globPtrメソッドに画像バッファのポインタ、step、rows、colsを渡すと、cv::cudev::GlobPtrSz構造体のデータを作ることができます。GlobPtrSz構造体を生成し、CUDAカーネルに渡すサンプルコードを以下に示します。
void launchMyKernel(cv::cuda::GpuMat& src, cv::cuda::GpuMat& dst)
{
cv::cudev::GlobPtrSz pSrc =
cv::cudev::globPtr(src.ptr(0), src.step, src.rows, src.cols * src.channels());
cv::cudev::GlobPtrSz pDst =
cv::cudev::globPtr(dst.ptr(0), dst.step, dst.rows, dst.cols * dst.channels());
const dim3 block(64, 2);
const dim3 grid(cv::cudev::divUp(src.cols, block.x), cv::cudev::divUp(src.rows, block.y));
myKernel<<<grid, block>>>(pSrc, pDst);
CV_CUDEV_SAFE_CALL(cudaGetLastError());
CV_CUDEV_SAFE_CALL(cudaDeviceSynchronize());
}
上記サンプルコードのようにCUDAカーネル(myKernel)の引数としてcv::cudev::GlobPtrSz構造体の変数を渡すことでCUDAカーネルの引数がシンプルにできていることがわかります。
GlobPtrSz構造体を参照するサンプルコード
cv::cudev::GlobPtrSz構造体のメンバ変数data、step、rows、colsを参照することで必要なデータにアクセスすることができます。GlobPtrSz構造体を参照するサンプルコードを以下に示します。
__global__ void myKernel(const cv::cudev::GlobPtrSz<uchar> src, cv::cudev::GlobPtrSz<uchar> dst)
{
int x = blockDim.x * blockIdx.x + threadIdx.x;
int y = blockDim.y * blockIdx.y + threadIdx.y;
dst.data[y*src.step + x] = UCHAR_MAX - src.data[y*src.step + x];
}
GpuMatにある画像バッファのアドレス取得
GpuMatクラスのインスタンスは画像バッファ(デバイス側)のアドレスを保持しています。GpuMatクラスにある画像バッファのアドレス取得方法について代表的な方法は以下の3パターンあります(これ以外で別の方法をご存知の方がいらっしゃったらぜひ教えてください)。
- メンバ変数dataから取得
- ptrメソッドから取得
- GlobPtrSz構造体のメンバ変数dataから取得
以下にこれらの取得方法を行ったサンプルコードを示します。
cv::cuda::GpuMat src(cv::Size(320, 240), CV_8UC1);
// (1) メンバ変数dataから取得
uchar *pData1 = src.data;
// (2) ptrメソッドから取得
uchar *pData2 = src.ptr<uchar>();
// (3) GlobPtrSz構造体のメンバ変数dataから取得
cv::cudev::GlobPtrSz<uchar> pSrc =
cv::cudev::globPtr(src.ptr<uchar>(), src.step, src.rows, src.cols * src.channels());
uchar *pData3 = pSrc.data;
gridTransform
ここでは、これまでの説明で先延ばしにしてきたgridTransformについて紹介します。
cudevモジュールにて定義されるgridTransformは大別すると以下の3つに分類されます。
- gridTransformUnary
src、dst、opを引数に持ち、「入力1つ、出力は1つ。入力に対してopを適用」といったケースのカーネルを呼ぶのに用いられる
- gridTransformBinary
src1、src2、dst、opを引数に持ち、「入力2つ、出力は1つ。入力に対してopを適用」といったケースのカーネルを呼ぶのに用いられる
- gridTransformTuple
この記事の冒頭でNsightの結果に出てきたtransformSimpleは、src、dst、op、maskといったパラメータを持ち、様々な処理を統一的に呼べるよう汎用性を持たせたCUDAカーネルとなっています(そのため、Nsightの結果にtransformSimpleが表示されていたわけですね)。
cv::cuda::cvtColor(BGR2GRAY)を例に挙げると、厳密には以下のようなシーケンスで処理が行われます。
cv::cuda::cvtColor
BGR_to_GRAY
cv::cuda::device::BGR_to_GRAY_8u
cv::cudev::gridTransformUnary
cv::cudev::grid_transform_detail::transform_unary
cv::cudev::grid_transform_detail::TransformDispatcher
cv::cudev::grid_transform_detail::TransformSimple
→ここでCUDAカーネルが呼ばれる
grid_transform_detail以下の振る舞いは長くなりそうなのでここでは詳細について割愛します。
また、cv::cudev::grid_transform_detail::TransformSimpleの引数opに目的の処理(上記例だとBGR2GRAYの色変換処理)の関数ポインタが渡されているため、transformSimpleでは目的の処理に対応したCUDAカーネルが呼ばれるようになっています。
このBGR2GRAYの色変換の例ではmodules/cudev/include/opencv2/cudev/functional/detail/color_cvt.hppにて定義される以下の処理が呼ばれるようになっています。
template <typename T, int scn, int bidx> struct RGB2Gray
: unary_function<typename MakeVec<T, scn>::type, T>
{
__device__ T operator ()(const typename MakeVec<T, scn>::type& src) const
{
const int b = bidx == 0 ? src.x : src.z;
const int g = src.y;
const int r = bidx == 0 ? src.z : src.x;
return (T) CV_CUDEV_DESCALE(b * B2Y + g * G2Y + r * R2Y, yuv_shift);
}
};
アトミック関数
CUDAが提供するatomic関数はCompute Capabilityによってfloat型をサポートしていなかったりするのでatomicCASを使ってatomic関数を自作したことがある方もいらっしゃるかもしれません。OpenCVのcudevモジュールではCompute Capabilityの違いを吸収した以下のアトミック関数を提供しています。
- cv::cudev::atomicAdd
- cv::cudev::atomicMin
- cv::cudev::atomicMax
そのため、上記APIを使うことでユーザがatomicCASを使ってアトミック関数自作する必要がなくなります。とはいえ、Compute Capabilityが2.0以降であれば普通にfloat型サポートしているので、今となってはこれらの関数の意義は大分薄くなってる気もします・・・。
Tips
ここでは個人的にまとめていたGpuMatを使う上でのTipsを紹介します。
GpuMatを入力にした自作CUDAカーネルを作りたい
GpuMatを入力として自作CUDAカーネルを動かす単純なサンプルコードを下記リポジトリに置いていますのでご参考ください。
https://github.com/atinfinity/launchMyKernel
自作CUDAカーネルはネガポジ反転するだけの非常にシンプルなものですが、この方法を応用すると「ある処理はOpenCV(cudaモジュール)に任せて、ある処理は自前で書いてチューニングする」みたいなことができるようになります。
OpenCVのCUDAカーネル内をデバッグしたい
CMakeでWITH_CUDA=ONとしてOpenCVをビルドした場合、通常、NVCCでOpenCVのCUDAカーネルをビルドする際にデバッグ情報が付与されないのでOpenCVのCUDAカーネル内をデバッグできません。
デバッグできるようにする最も簡単な方法はcmake/OpenCVDetectCUDA.cmakeを編集し、NVCCのコンパイラオプションを追加するという方法です。具体的には、
# NVCC flags to be set
set(NVCC_FLAGS_EXTRA "")
となっている箇所を
# NVCC flags to be set
set(NVCC_FLAGS_EXTRA "-G -g")
に変更した後、CMakeを実行し、OpenCVをビルドすることでOpenCVのCUDAカーネル内をデバッグできるようになります。
複数GPUを使う
cv::cuda::setDevice関数を使うことでデバイス指定することができます。
また、公式サンプルにも複数GPUを使うものがあるので参考になるかもしれません。
- samples/gpu/multi.cpp
- samples/gpu/stereo_multi.cpp
- samples/gpu/driver_api_multi.cpp
- samples/gpu/driver_api_stereo_multi.cpp
これらのサンプルは、TBBやpthread等を用いて処理をデバイス毎に振り分けるシンプルなものになっています。
デバイスのfeatureサポートをチェックする
動作デバイスのfeatureサポートをチェックするためのcv::cuda::deviceSupports関数が提供されています。チェックできるfeatureは公式ドキュメントにまとまっています。以下にWarpShuffleが使えるかどうかをチェックするサンプルコードを紹介します。
bool isSupportWarpShuffle =
cv::cuda::deviceSupports(cv::cuda::FeatureSet::WARP_SHUFFLE_FUNCTIONS);
GpuMatの画像データのウィンドウ表示でちょっと楽をする
GpuMatのデータをhighguiのウィンドウに表示する際、通常、downloadメソッドでホストに転送して、cv::imshowで表示すると思いますがちょっとだけ簡単にできる方法があります。
具体的には以下のような設定を行うことでユーザが明示的にホストへ転送しなくてもよくなります。
- OpenCVをビルドする際にWITH_OPENGLを有効にする
- cv::namedWindow関数にセットするflagにcv::WINDOW_OPENGLを付与する
#include <opencv2/core.hpp>
#include <opencv2/core/cuda.hpp>
#include <opencv2/cudaimgproc.hpp>
#include <opencv2/imgcodecs.hpp>
#include <opencv2/highgui.hpp>
#include <iostream>
int main(int argc, char *argv[])
{
cv::Mat src = cv::imread("lena.jpg", cv::IMREAD_UNCHANGED);
cv::Mat dst;
// 画像の読み込みに失敗したらエラー終了する
if(src.empty())
{
return -1;
}
cv::cuda::GpuMat d_src(src), d_dst;
cv::cuda::cvtColor(d_src, d_dst, cv::COLOR_BGR2GRAY);
// highgui(normal)を使った表示
d_dst.download(dst); // ホストメモリに転送する
cv::namedWindow("normal", cv::WINDOW_AUTOSIZE);
cv::imshow("normal", dst);
// highgui(OpenGL)を使った表示
// この方法だと明示的にホストに転送する必要がない
cv::namedWindow("highgui(OpenGL)", cv::WINDOW_AUTOSIZE | cv::WINDOW_OPENGL);
cv::imshow("highgui(OpenGL)", d_dst);
cv::waitKey(0);
cv::destroyAllWindows();
return 0;
}
詳細については、筆者の別記事にて解説していますのでご参考ください。
cudaモジュールのビルド時間を短縮する
OpenCVのcudaモジュールをビルドしたことがある方は経験があるかもしれませんが、普通にCMakeでWITH_CUDAをONにしてビルドすると非常にビルド時間が掛かってしまいます(マシンスペックによりますが、以前6時間以上掛かったことも・・・)。これはOpenCVビルド時に複数のCompute Capability向けにビルドをしているというのが理由の一つです。
そのため、CMakeオプションにて対象デバイスのCapability番号を明示的に指定する(例えばCUDA_ARCH_BIN=”3.5″と指定する)ことで、特定のCompute Capability向けのコンパイルにとどめることができ、ビルド時間を大きく短縮することができます。お手持ちのNVIDIA GPUに対応するCompute CapabilityはNVIDIAサイト調べることができます。
また、必要なcudaモジュールだけビルドすることでもビルド時間を短縮することができます
(例えば、CMakeオプションBUILD_opencv_cudaarithmはONにして、BUILD_opencv_cudaoptflowはOFFにするなど)。
こちらでOpenCVのビルドスクリプトを公開しているのでご参考ください。
おわりに
この記事ではGpuMatの内部でどんな処理が走っているかとGpuMatを使う上でのTipsをいくつか紹介しました。この記事が、OpenCVにあるCUDA実装を読み解いたり、GpuMatと自作CUDAコードを組み合わせる際の助けになりましたら幸いです。

Tags
About Author
yoshimura
Leave a Comment
Tags
Favorite Post

 2023年1月27日
2023年1月27日 2017年8月22日
2017年8月22日
Archives
- 2025年5月
- 2025年4月
- 2024年11月
- 2024年10月
- 2024年7月
- 2024年5月
- 2024年4月
- 2024年2月
- 2024年1月
- 2023年12月
- 2023年6月
- 2023年5月
- 2023年4月
- 2023年2月
- 2023年1月
- 2022年12月
- 2022年10月
- 2021年11月
- 2021年9月
- 2021年6月
- 2021年3月
- 2021年2月
- 2020年12月
- 2020年10月
- 2020年7月
- 2020年6月
- 2020年5月
- 2020年4月
- 2020年3月
- 2020年2月
- 2020年1月
- 2019年12月
- 2019年11月
- 2019年10月
- 2019年9月
- 2019年8月
- 2019年6月
- 2019年4月
- 2019年3月
- 2019年2月
- 2019年1月
- 2018年12月
- 2018年11月
- 2018年10月
- 2018年8月
- 2018年6月
- 2018年5月
- 2018年4月
- 2018年3月
- 2018年2月
- 2017年12月
- 2017年11月
- 2017年10月
- 2017年9月
- 2017年8月
- 2017年7月
- 2017年6月
- 2017年5月
- 2017年3月
- 2016年12月
- 2016年11月
- 2016年8月
- 2016年7月
- 2016年3月
- 2016年2月
- 2016年1月
- 2015年12月
- 2015年11月
- 2015年10月
- 2015年8月
- 2015年6月
- 2015年3月
- 2015年2月
- 2015年1月
- 2014年12月
- 2014年11月
keisuke.kimura in Livox Mid-360をROS1/ROS2で動かしてみた
Sorry for the delay in replying. I have done SLAM (FAST_LIO) with Livox MID360, but for various reasons I have not be...
Miya in ウエハースケールエンジン向けSimulated Annealingを複数タイルによる並列化で実装しました
作成されたプロファイラがとても良さそうです :) ぜひ詳細を書いていただきたいです!...
Deivaprakash in Livox Mid-360をROS1/ROS2で動かしてみた
Hey guys myself deiva from India currently i am working in this Livox MID360 and eager to knwo whether you have done the...
岩崎システム設計 岩崎 満 in Alveo U50で10G Ethernetを試してみる
仕事の都合で、検索を行い、御社サイトにたどりつきました。 内容は大変参考になりま�...
Prabuddhi Wariyapperuma in Livox Mid-360をROS1/ROS2で動かしてみた
This issue was sorted....