このブログは、株式会社フィックスターズのエンジニアが、あらゆるテーマについて自由に書いているブログです。
NVIDIA RTX PRO 6000 Blackwell Max-Q 上でBLASベンチマークを動かしてみる
はじめに
強力なワークステーション向けGPUであるNVIDIA RTX PRO 6000 Blackwell Max-Q(以下 6000 Blackwell Max-Q)が発売されました。
前回の記事では、NVIDIAのデータシートをもとに、ハイエンドGPUであるNVIDIA H100 PCIe(以下 H100 PCIe)との性能比較を行いました。
今回は実機上でのベンチマーク検証です。
行列積をはじめとした行列演算は、AI・ディープラーニング、物理シミュレーションや 3D CGレンダリングなど様々な場面で絶えず実行されており、その性能は特にこのようなアプリケーション全体の実行速度に直結します。 そこで今回は、GPUの基礎体力を測る指標として、BLAS、つまり行列積のベンチマークを通して性能の比較・検証を行っていきます。
ベンチマークについて
今回行ったBLASベンチマークは、\(N \times
N\) の正方行列 \(A, B\) を用いて
\(C = AB\)
の計算速度を計測するものです。 ベンチマークの実装においては、 NVIDIA
cuBLAS 12.9 ライブラリの cublasGemmEx
関数を使用しました。
計算に用いる行列 \(A, B\) の各要素は 0.0~1.0 の範囲のランダムな数で初期化しました。 また、ライブラリ中で初期化処理などが行われる可能性を考慮し、15回同じ条件で実行し後半10回の実行時間の平均を用いて FLOPS を算出しました。
行列サイズ \(N\) については \(16\) からスタートし、2倍ずつ増加させ、それぞれの \(N\) に対してベンチマークを取りました。 \(N\) の上限については 6000 Blackwell Max-Q は 96GB、H100 PCIe は 80GB の GPU メモリを搭載しているため、これを使い切る程度のサイズである \(65536\) としました。
評価精度は、以下の3種類の構成で計測しました。
cublasGemmExでは入力、出力、そして内部計算の精度を個別に指定できるため、それぞれ以下に示す表の通り指定しました。
| テストケース | 入力行列 (A, B) のデータ型 | 出力行列 (C) のデータ型 | 内部計算の精度 |
|---|---|---|---|
| 単精度 (FP32) | FP32 (CUDA_R_32F) |
FP32 (CUDA_R_32F) |
FP32
(CUBLAS_COMPUTE_32F) |
| 半精度 (FP16) | FP16 (CUDA_R_16F) |
FP16 (CUDA_R_16F) |
FP16
(CUBLAS_COMPUTE_16F) |
| TF32 | FP32 (CUDA_R_32F) |
FP32 (CUDA_R_32F) |
TF32
(CUBLAS_COMPUTE_32F_FAST_TF32) |
結果
6000 Blackwell Max-QとH100 PCIeに対してベンチマークを行いました。 結果は横軸 N、縦軸TFLOPSとなるようにグラフ上にプロットしました。
単精度 (FP32)
まずは FP32 でのベンチマークの計測結果です。
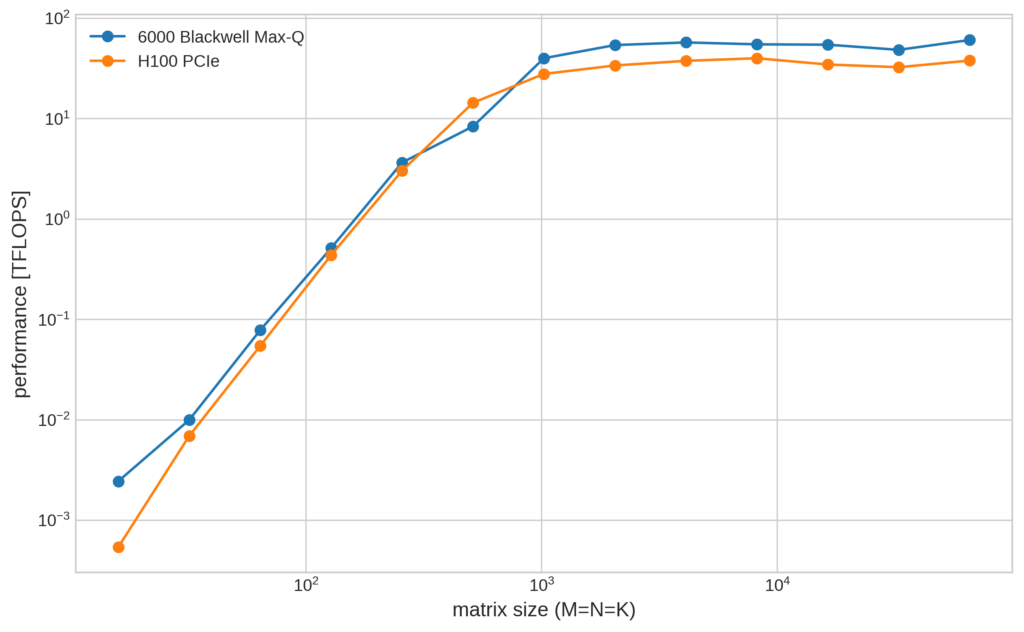
6000 Blackwell Max-Q では最大およそ60 TFLOPSと理論性能の約55%を、H100 PCIe でおよそ39 TFLOPSと理論性能の約76%ほどの性能を達成しています。 6000 Blackwell Max-Q で理論値との間にギャップが生じている原因については、後の考察で詳しく分析します。
半精度 (FP16) / TensorFloat-32 (TF32)
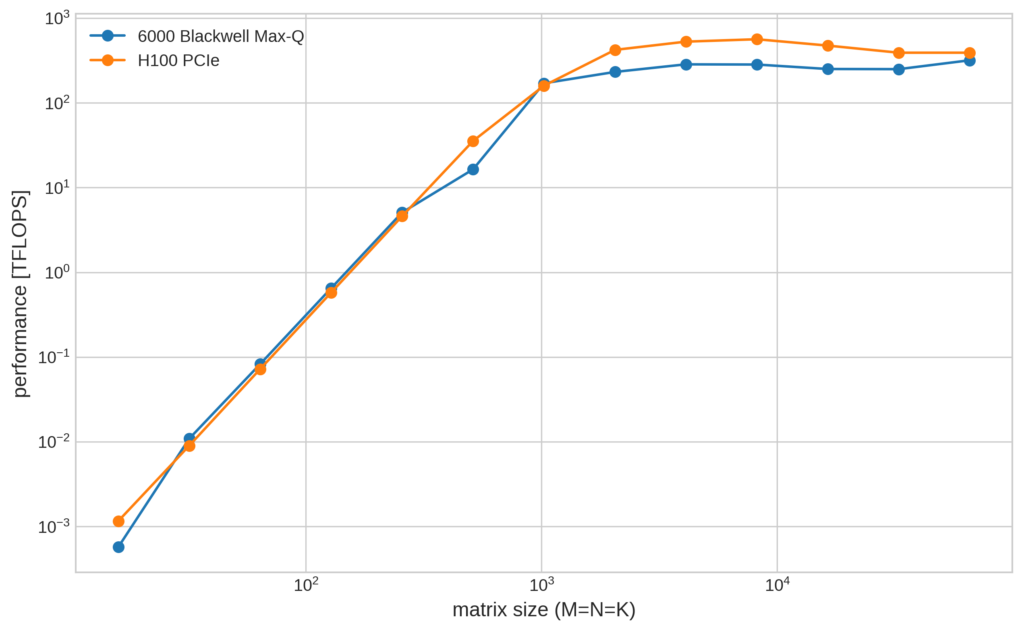
FP16 でのベンチマークの計測結果です。
次にTF32でのベンチマークの計測結果です。
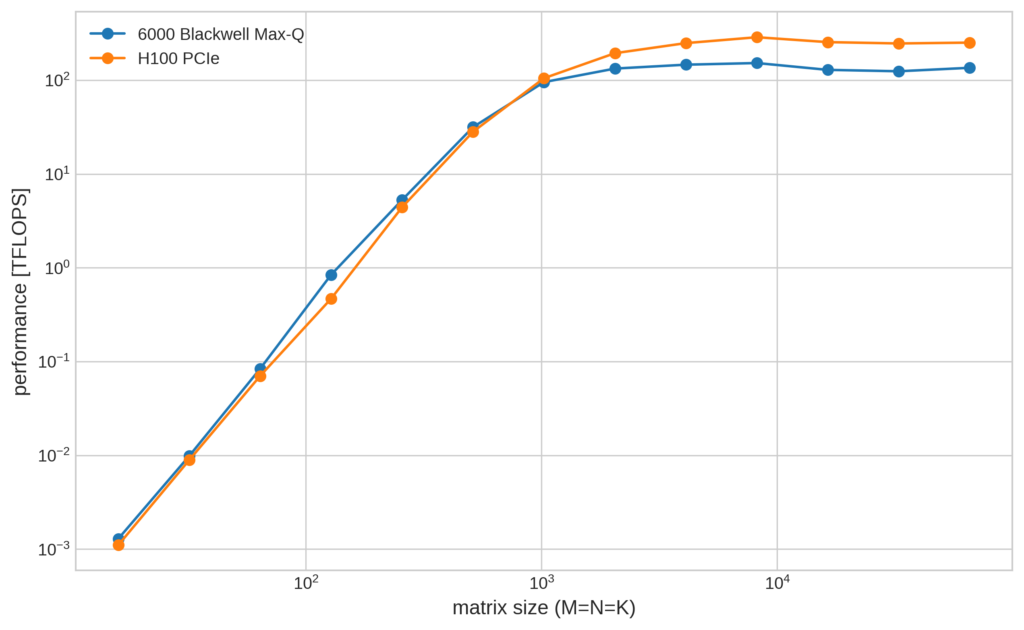
FP16、TF32 に関してはどちらの計測においても最大性能でH100 PCIe のほうが6000 Blackwell Max-Qを上回る結果となりました。 特にTF32 でのベンチマークでは、6000 Blackwell Max-Q がおよそ150 TFLOPS、H100 PCIe がおよそ 290 TFLOPS と、およそ1.9倍の性能差を示しています。
考察
今回の単精度 (FP32) のベンチマークでは、ピーク性能で6000 Blackwell Max-Q はH100 PCIeに対して約1.5倍の性能である結果が得られました。 あまり理論性能に近い性能を発揮できていませんが、それにもかかわらず H100 PCIe よりも高い性能を示している 6000 Blackwell Max-QのFP32演算性能には目を見張るものがあります。
一方、ピーク性能でH100 PCIeは6000 Blackwell Max-Q に対して、半精度 (FP16) のベンチマークで約1.7倍、TensorFloat-32 (TF32) のベンチマークで約1.9倍の性能を記録しました。 TF32などの機械学習用途での高い演算性能を求める場面ではH100 PCIeのほうが適しているといえるでしょう。
では、コストパフォーマンスの観点ではどうでしょうか。 H100 PCIeが約470万円1であるのに対し、6000 Blackwell Max-Qは約160万円2と、価格は3分の1近くに抑えられています。 ベンチマークで見た通り、AI性能の差は価格差ほど大きくなく、FP32性能に至ってはH100を上回っています。この点を踏まえれば、6000 Blackwell Max-Qは非常にコストパフォーマンスに優れたGPUと言えるでしょう。
プロファイラを用いた分析
今回のベンチマークではなぜスペック上は H100 PCIe の2倍近い FP32 性能を持つはずの 6000 Blackwell Max-Q がなぜ1.5倍の性能に留まったのでしょうか。
この謎を解明するため、NVIDIA製のプロファイラツールである Nsight
Compute を用いてFP32の N=8192
におけるベンチマーク実行中のGPU内部の挙動を分析しました。
分析の結果、Compute (SM) Throughput は H100 PCIe は93%を達成しているのに対し、6000 Blackwell Max-Qは78%に留まっていることがわかりました。 さらに、6000 Blackwell Max-QのL1キャッシュのヒット率が0%という奇妙な状態になっていることが観察できました。 つまり、実行されたカーネルのメモリアクセスが、L1キャッシュを完全にバイパスしているか、全くヒットしていないということです。
これは、cuBLASライブラリが 6000 Blackwell Max-Q のアーキテクチャに対して最適な計算カーネルを選択できていない可能性が考えられます。
しかし、それでも H100 PCIe を上回る性能を発揮できたのは、6000 Blackwell Max-Q の持つアーキテクチャの強みのおかげと考えられます。 H100 PCIe の114個を凌駕する188個という豊富なSM数に加え、H100 PCIe の50MB を大きく上回る 128MB の巨大なL2キャッシュなど優れたハードウェアスペックにより、L1キャッシュの失敗による性能低下をある程度食い止めたのではないでしょうか。
将来ライブラリがさらに最適化されれば、このようなソフトウェア的なハンデが埋まり、さらに性能差が大きくなると考えられるのではないでしょうか。
メモリ律速の壁
しかし、図1,2を注意深く見ると、面白い傾向が読み取れます。 行列サイズ \(N\) が1024以下の比較的小さな領域では、両GPUの性能がほぼ同等となっているのです。そして、\(N\)が大きくなるにつれて、その差は開いていきます。
この現象の鍵を握るのが「メモリ律速(Memory-bound)」という概念です。
GPUの性能は、単純な計算能力(FLOPS)だけでなく、データをメモリから演算器へ供給する速度(メモリ帯域幅)にも大きく左右されます。 タスクの性質によって、どちらがボトルネックになるかが決まります。
行列積の演算回数は \(O(N^3)\)、メモリからのデータ読み書き量は \(O(N^2)\) で増加します。 \(N\)が小さいと、計算量に対してデータ移動の割合が大きくなります。 そのため、GPUは計算する時間よりもデータをメモリから持ってくるのを待つ時間が長くなり、性能がメモリ帯域幅で頭打ちになります。(メモリ律速)
両者のメモリ帯域幅は1792GB/s (6000 Blackwell Max-Q) と2039GB/s (H100 PCIe)と比較的近いため、この領域では性能も拮抗するのです。
\(N\)が大きくなると、データ移動量に対して計算量が爆発的に増加します。 こうなるとGPUはメモリからのデータ供給を待つことなく、ひたすら計算に専念できるようになります。(計算律速)
\(N\) が小さいときに性能が出ていないこともこのメモリ律速で説明ができます。
この結果は、比較的小規模な計算やデータバッチを扱うタスクにおいては、6000 Blackwell Max-QでもH100に迫る性能を引き出せる可能性を示唆しています。
まとめ
今回のBLASベンチマークを通して、6000 Blackwell Max-QとH100 PCIe、両者の得意分野が明確になりました。
6000 Blackwell Max-Qの強みとして、卓越した FP32 性能と、優れたコストパフォーマンスが挙げられます。 FP32 演算を多用するような科学技術計算、シミュレーション、CGレンダリングでH100を凌駕する性能を発揮してくれるでしょう。 また、H100には及ばないものの、FP16/TF32でも価格差を考えれば非常に高い性能を持ち、幅広いタスクに対応可能です。
結論として、6000 Blackwell Max-Qは、特定のタスクでH100を上回りつつ、AI用途でも高い水準の性能をより低コストで実現する、極めてバランスの取れたGPUであるといえるでしょう。 H100への投資が難しい研究者や開発者、そして何よりFP32の演算能力を求めるエンジニアやクリエイターにとって、これ以上ない魅力的な選択肢となるのではないでしょうか。

Tags
About Author
ryoga.hosojima
Leave a Comment
Tags
Favorite Post

 2023年1月27日
2023年1月27日 2017年8月22日
2017年8月22日
Archives
- 2026年1月
- 2025年12月
- 2025年11月
- 2025年9月
- 2025年8月
- 2025年5月
- 2025年4月
- 2024年11月
- 2024年10月
- 2024年7月
- 2024年5月
- 2024年4月
- 2024年2月
- 2024年1月
- 2023年12月
- 2023年6月
- 2023年5月
- 2023年4月
- 2023年2月
- 2023年1月
- 2022年12月
- 2022年10月
- 2021年11月
- 2021年9月
- 2021年6月
- 2021年3月
- 2021年2月
- 2020年12月
- 2020年10月
- 2020年7月
- 2020年6月
- 2020年5月
- 2020年4月
- 2020年3月
- 2020年2月
- 2020年1月
- 2019年12月
- 2019年11月
- 2019年10月
- 2019年9月
- 2019年8月
- 2019年6月
- 2019年4月
- 2019年3月
- 2019年2月
- 2019年1月
- 2018年12月
- 2018年11月
- 2018年10月
- 2018年8月
- 2018年6月
- 2018年5月
- 2018年4月
- 2018年3月
- 2018年2月
- 2017年12月
- 2017年11月
- 2017年10月
- 2017年9月
- 2017年8月
- 2017年7月
- 2017年6月
- 2017年5月
- 2017年3月
- 2016年12月
- 2016年11月
- 2016年8月
- 2016年7月
- 2016年3月
- 2016年2月
- 2016年1月
- 2015年12月
- 2015年11月
- 2015年10月
- 2015年8月
- 2015年6月
- 2015年3月
- 2015年2月
- 2015年1月
- 2014年12月
- 2014年11月
keisuke.kimura in Livox Mid-360をROS1/ROS2で動かしてみた
Sorry for the delay in replying. I have done SLAM (FAST_LIO) with Livox MID360, but for various reasons I have not be...
Miya in ウエハースケールエンジン向けSimulated Annealingを複数タイルによる並列化で実装しました
作成されたプロファイラがとても良さそうです :) ぜひ詳細を書いていただきたいです!...
Deivaprakash in Livox Mid-360をROS1/ROS2で動かしてみた
Hey guys myself deiva from India currently i am working in this Livox MID360 and eager to knwo whether you have done the...
岩崎システム設計 岩崎 満 in Alveo U50で10G Ethernetを試してみる
仕事の都合で、検索を行い、御社サイトにたどりつきました。 内容は大変参考になりま�...
Prabuddhi Wariyapperuma in Livox Mid-360をROS1/ROS2で動かしてみた
This issue was sorted....