このブログは、株式会社フィックスターズのエンジニアが、あらゆるテーマについて自由に書いているブログです。
Intel AMX (Advanced Matrix Extension) 解説(基礎編)
TL;DR
- AMX とは
- Advanced Matrix Extension
- Intel が 4th Gen Xeon (Sapphire Rapids) に導入した新命令セット
- 行列積を高速に計算できる専用命令
- 理論性能は、1 コアあたり 3,482 [GFLOPS] (AVX512 の 16 倍)
- ※ AVX512 理論性能:1 コアあたり 217 [GFLOPS]
- サンプルコード
- OpenBLAS での実性能確認
- 1 コアの場合、AVX512 の 11.7 倍
- 112 コアの場合、AVX512 の 2 倍
- ※ 動作周波数や最適化精度によると思われます
はじめに
AI の爆発的な普及に伴い、高性能な計算環境の需要は高まっています。 計算の性質から GPU が広く用いられていますが、同様の計算は CPU でも可能です。 消費電力・発熱等の制約で GPU を利用できない環境でも CPU は利用可能ですが、行列演算に特化しているわけではありません。 Intel/AMD の AVX (Advanced Vector Extensions)、ARM の SVE (Scalable Vector Extension) を用いると高速な計算が可能ですが、行列演算では複数の命令を高度に組み合わせる必要がありました。
そこで、Intel は、2021 年の Xeon Sapphire Rapids (第 4 世代) から新しい命令セット AMX (Advanced Matrix Extension) を導入しました。 これは名前の通り行列演算に特化した拡張命令セットで、AVX を置き換えるものではありません。 AMX は行列積しか扱えない反面、非常にシンプルな命令で、AVX による行列演算と比較して数倍~数十倍程度高速に演算可能です。
インターン生の甲賀さんと一緒に、AMX 命令から各種動作まで調査を行いました。 本記事では、AMX のレジスタ、命令セットに加えて各命令の動作、サンプルコードまで詳細に解説します。
対象読者
- AVX (Advanced VECTOR Extensions) についてある程度理解している方
- AMX (Advanced MATRIX Extensions) について知りたい方
AMXの基礎用語
- タイル
- AMX で一度に参照できる部分行列で、タイル と TILEDATA レジスタは 1:1 で対応します。
- 行列を「タイル」の単位で分割し、「タイル」同士の積和演算で行列積を計算します。
- TILEDATA レジスタ
- タイル を格納するレジスタで、
tmm0, tmm1, ..., tmm7の 8 個のレジスタが存在します。 tmm<N>は、最大で 16 行 x 64-byte (=1024-byte) の領域を格納できます。- 後述の TILECFG で行数・列サイズが 0 の TILEDATA は無効な状態です。
- タイル を格納するレジスタで、
- TILECFG レジスタ
- TILEDATA の設定を格納するレジスタで、1 個だけ存在します。
- このレジスタを設定すると、TILEDATA のサイズを 1 行 x 64-byte などに設定できます。
- パレット
- AMX の動作モードに相当します。
- 「パレット」を指定することで、使用可能なタイルのサイズや演算の種類を指定します(現在は行列積のみ)。
AMX の計算フロー
AMX の実行フローは、主に次の通りです。(各命令の詳細は後述します)
- タイル設定
ldtilecfg命令で、TILECFG レジスタを設定します。この時、TILEDATA レジスタも初期化されます。
- タイルロード
tileloadd命令で、メモリから TILEDATA レジスタにデータを読み込みます。
- TMUL 演算
tdpbf16ps(BF16) などの命令で、TILEDATA レジスタ同士の演算を行います。
- タイルストア
tilestored命令で、TILEDATA レジスタからメモリに結果を書き出します。
- タイル解放
tilerelease命令で、TILECFG を初期状態に戻します。TILEDATA レジスタも初期化されます。

TILECFG レジスタについて
TILECFG レジスタは、以下に示す tileconfig_t 構造体のようなデータ構造となっています。 プログラムからは、この構造体をロードさせることで TILECFG を設定可能です。
struct tileconfig_t {
uint8_t palette_id;
uint8_t startRow;
uint8_t reserved[14];
uint16_t colb[16];
uint8_t rows[16];
};
tileconfig_t の各メンバは、次のような意味を持ちます。
uint8_t pallete_id- パレット。
- 0: デフォルト。AMX 演算は使用できない。
- 1: 行列積演算。8 KB の内部ストレージを持ち、8 個の TILEDATA が、それぞれ最大で 1 KB (16 行 x 64-byte) のデータを持つ。
- それ以外:未定義。設定するとエラー。
- 今後、互換性を失う変更があった場合に 2 以降が定義される。
uint8_t startRow- page fault などで演算を中断した時の再開位置。
- 内部的に利用されるため、設定時は 0 を指定すれば良い。
uint8_t reserved- 予約領域
uint16_t colb[16]- 各 TILEDATA の一行当たりのバイト数。最大で 64。
colb[0] = tmm0のように対応し、col[8]以降は無視される。
uint8_t rows[16]- 各 TILEDATA の行数。最大で 16。
rows[0] = tmm0のように対応し、rows[8]以降は無視される。
AMX 命令セット
AMX の命令セットとサポートするマイクロアーキテクチャは次の通りに定義されています。 本記事の執筆時点 (2025/08) で実際に使用できるのは Granite Rapids D までです。 よって、本記事では IntelⓇ Intrinsics Guide に記載のある AMX-TILE、AMX-BF16、AMX-INT8、AMX-FP16、AMX-COMPLEX までの命令セットについて詳しく説明します。
CPU が対応していない場合 (Diamond Rapids 命令セット含む) も、Intel Software Development Emulator 上で実行可能です。
✅ は対応、❌ は未対応。
| 命令セット (AMX- は省略) | Sapphire Rapids | Granite Rapids | Granite Rapids D | Diamond Rapids | 命令セットの概要 |
|---|---|---|---|---|---|
| TILE | ✅ | ✅ | ✅ | ✅ | タイルのロード、ストア、コンフィグの設定など基本的な命令群 |
| BF16 | ✅ | ✅ | ✅ | ✅ | BF16 型の行列積 |
| INT8 | ✅ | ✅ | ✅ | ✅ | INT8 型の行列積 |
| FP16 | ❌ | ✅ | ✅ | ✅ | FP16 型の行列積 |
| COMPLEX | ❌ | ❌ | ✅ | ✅ | FP16 複素数型の行列積 |
| MOVRS | ❌ | ❌ | ❌ | ✅ | read-sharedとなるメモリ位置からのタイルのロードなど |
| AVX512 | ❌ | ❌ | ❌ | ✅ | TILEDATA から zmm レジスタへの移動など |
| FP8 | ❌ | ❌ | ❌ | ✅ | FP8 型の行列積 |
| TF32 | ❌ | ❌ | ❌ | ✅ | TF32 型の行列積 |
| TRANSPOSE | ❌ | ❌ | ❌ | ✅ | 行列転置などを含む命令群 |
各命令セット (~COMPLEX) で利用可能な命令は次の通りです。
Instruction と Intrinsics は、Intel® Intrinsics Guide からの引用です。 Throughput と Latency は、Intel® 64 and IA-32 Architectures Optimization Reference Manual からの引用です。(- は該当情報が記載されていないことを示します)
| 命令セット | Instruction | Intrinsics | Throughput | Latency |
|---|---|---|---|---|
| TILE | ldtilecfg m512 | void _tile_loadconfig (const void * mem_addr) | – | 204 |
| TILE | sttilecfg m512 | void _tile_storeconfig (void * mem_addr) | – | 19 |
| TILE | tilerelease | void _tile_release () | – | 13 |
| TILE | tileloadd tmm, sibmem | void __tile_loadd (__tile1024i* dst, const void* base, size_t stride)void _tile_loadd (constexpr int dst, const void * base, size_t stride) | 8 | 45 |
| TILE | tileloaddt1 tmm, sibmem | void __tile_stream_loadd (__tile1024i* dst, const void* base, size_t stride)void _tile_stream_loadd (constexpr int dst, const void * base, size_t stride) | 33 | 48 |
| TILE | tilestored sibmem, tmm | void __tile_stored (void* base, size_t stride, __tile1024i src)void _tile_stored (constexpr int src, void * base, size_t stride) | 16 | – |
| TILE | tilezero tmm | void _tile_zero (constexpr int tdest)void _tile_zero (constexpr int tdest) | 0 | 16 |
| BF16 | tdpbf16ps tmm, tmm, tmm | void __tile_dpbf16ps (__tile1024i* dst, __tile1024i src0, __tile1024i src1)void _tile_dpbf16ps (constexpr int dst, constexpr int a, constexpr int b) | 16 | 52 |
| INT8 | tdpbssd tmm, tmm, tmm | void __tile_dpbssd (__tile1024i* dst, __tile1024i src0, __tile1024i src1)void _tile_dpbssd (constexpr int dst, constexpr int a, constexpr int b) | 16 | 52 |
| INT8 | tdpbsud tmm, tmm, tmm | void __tile_dpbsud (__tile1024i* dst, __tile1024i src0, __tile1024i src1)void _tile_dpbsud (constexpr int dst, constexpr int a, constexpr int b) | 16 | 52 |
| INT8 | tdpbusd tmm, tmm, tmm | void __tile_dpbusd (__tile1024i* dst, __tile1024i src0, __tile1024i src1)void _tile_dpbusd (constexpr int dst, constexpr int a, constexpr int b) | 16 | 52 |
| INT8 | tdpbuud tmm, tmm, tmm | void __tile_dpbuud (__tile1024i* dst, __tile1024i src0, __tile1024i src1)void _tile_dpbuud (constexpr int dst, constexpr int a, constexpr int b) | 16 | 52 |
| FP16 | tdpfp16ps tmm, tmm, tmm | void __tile_dpfp16ps (__tile1024i* dst, __tile1024i src0, __tile1024i src1)void _tile_dpfp16ps (constexpr int dst, constexpr int a, constexpr int b) | 16? | 52? |
| COMPLEX | tcmmrlfp16ps tmm, tmm, tmm | void __tile_cmmimfp16ps (__tile1024i* dst, __tile1024i src0, __tile1024i src1)void _tile_cmmrlfp16ps (constexpr int dst, constexpr int a, constexpr int b) | 16? | 52? |
| COMPLEX | tcmmimfp16ps tmm, tmm, tmm | void __tile_cmmrlfp16ps (__tile1024i* dst, __tile1024i src0, __tile1024i src1)void _tile_cmmimfp16ps (constexpr int dst, constexpr int a, constexpr int b) | 16? | 52? |
タイル操作系命令 (AMX-TILE)
ldtilecfg
指定されたメモリ位置から 64-byte 読み込み、TILECFG にロードします。 メモリ位置には、64-byte データが tileconfig_t のフォーマットで配置されている必要があります。 この命令はレイテンシが大きいため、可能な限り同じ設定を使いまわすことが推奨されています。
sttilecfg
指定されたメモリ位置に TILECFG の内容を 64-byte 分書き出します。 ldtilecfg 命令が実行されていない場合は、0 が 64-byte 分書き出されます。
tilerelease
TILEDATA 及び TILECFG を初期状態に戻します。 具体的には、TILEDATA と TILECFG を全てゼロ埋めします。
tileloadd / tileloaddt1
指定されたメモリ位置からデータをロードし、TILEDATA レジスタにロードします。 データのアドレスは SIB アドレッシングで指定され、Intrinsics ではベースアドレス void *base とストライド size_t stride を指定できます。 具体的には、base + i * stride のメモリ位置から colb バイトを TILEDATA の i 行目として読み込みます。 TILECFG の colb が 64 未満、もしくは rows が 16 未満の場合は TILEDATA にはロードされない領域があり、その領域はゼロ埋めされます。 TILECFG が設定されていない場合(つまり、palette_id が 0 の場合)は例外が発生します。
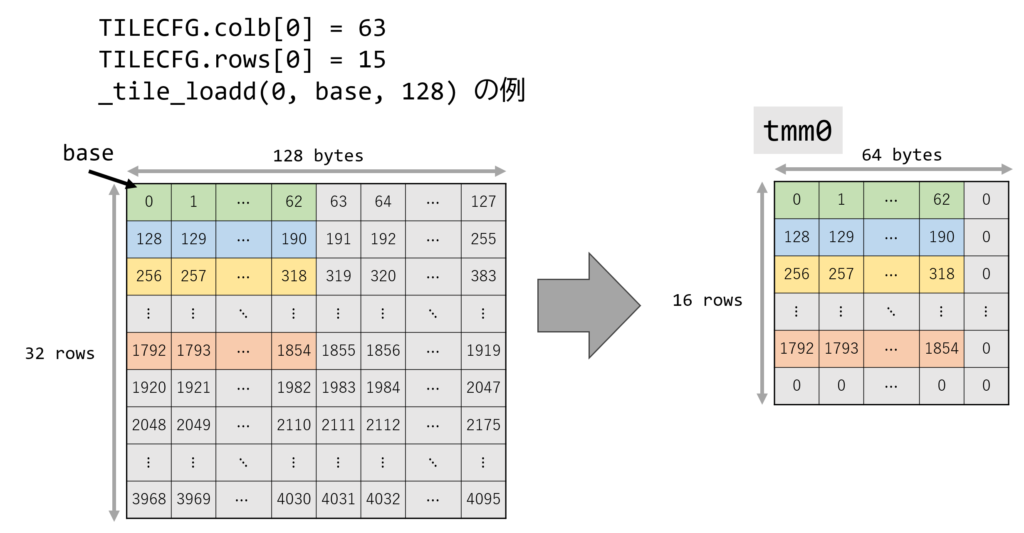
tileloadd の例を次の図に示します。
TILECFG.colb[0] = 63, TILECFG.rows[0] = 15と設定されていますtmm0は 63-byte x 15 行のみ有効
_tile_loadd(0, base, 128)で、先頭アドレスがbaseな行列から、stride=128でロードする- この時、次のように
tmm0へロードされます。- 0 行目は、
base + (0) * (128) = base+0から、63-byte をロード - 1 行目は、
base + (1) * (128) = base+128から、63-byte をロード - 15 行目まで繰り返す
- TILEDATA は 64-byte x 16 行なので、ロードされない領域はゼロ埋め
- 0 行目は、
tileloaddt1 は、tileloadd の non-temporal 版です。 tileloaddt1 でロードされるデータは、時間的極所性が薄いため、キャッシュに保持する必要が無いというヒントを与えます。
tilestored
指定したメモリ位置に、指定した TILEDATA の値を書き込みます。 tileloadd と同様に、データのアドレスは SIB アドレッシングで指定されます。
tilezero
指定された TILEDATA を 0 埋めします。
TMUL 系命令
BF16, INT8, FP16, COMPLEX では、それぞれ対応する TMUL 命令を持ちます。 TMUL 命令は TILEDATA を三個取り、それぞれ X Y Z とすると Z += Matmul(X, Y) のような積和演算を TMUL (Tile Matrix Multiply Unit) で行います。
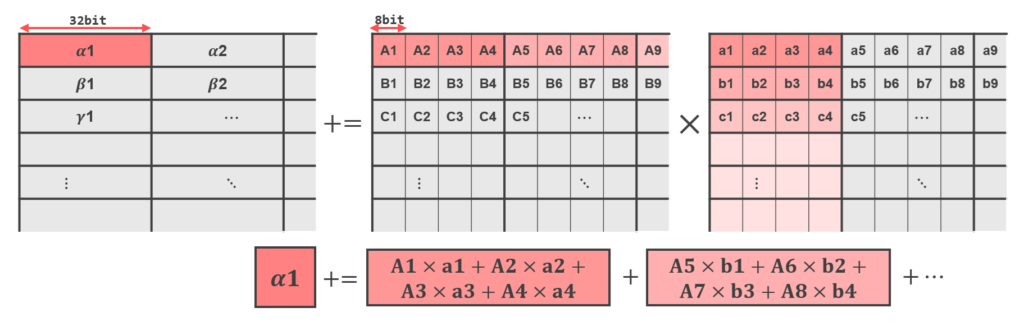
TMUL 系命令は、実際には dot-product SIMD 演算を行うため、TILEDATA のデータを次のルールに従って読み書きします。
- データは行優先 (row-wise) ベース
- 演算単位は 4-byte (32-bit)
例として、入力が INT8 TMUL の場合は次のように 4 つの値を組とし、int32 を出力とする演算をします。
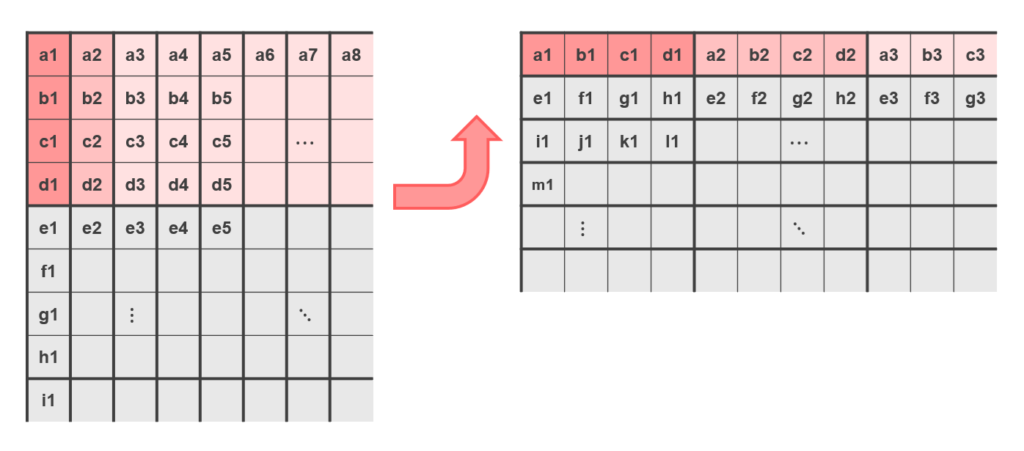
通常の行列積の場合、ソースとなる行列の片方は列優先(col-wise)でアクセスしていました。 AMX では、全てのレジスタを行優先でアクセスするため、次に示すように行列のレイアウトを変更する必要があります。 注意したい点として、このレイアウト変更は行列の転置ではありません。
そのため、通常の行列積を計算したい場合、右の行列の要素を並び変える必要があります。 注意点として、畳み込む方向の長さが 4 の倍数でない場合はエラーになるため、0 でパディングする必要があります。
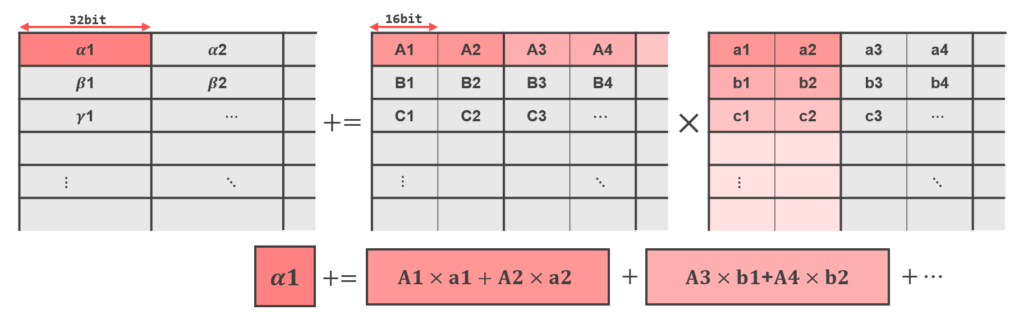
BF16 TMUL の場合は、16-bit の値を 2 個ずつ演算し、float を出力します。
tdpbf16ps
TILEDATA の値を BF16 (BrainFloat16) として解釈し、FP32 行列を出力します。 内部で BF16 は予め FP32 にキャストされ、FP32 で計算されます。
tdpbuud, tdpbsud, tdpbusd, tdpbssd
TILEDATA の値を INT8 (int8_t or uint8_t) として解釈し、INT32 行列を出力します。 tdpb**d の ** 部分は、ソースの TILEDATA の符号解釈を示しています。
uu=Uint8_t x Uint8_tsu=int8_t x Uint8_tus=Uint8_t x int8_tss=int8_t x int8_t
tdpfp16ps
TILEDATA の値を FP16 (int8_t or uint8_t) として解釈し、FP32 行列を出力します。 内部で FP16 は予め FP32 にキャストされ、FP32 で計算されます。
tcmmrlfp16ps, tcmmimfp16ps
TILEDATA の値を Complex16 (実部 real と虚部 imm がどちらも FP16) として解釈し、FP32 行列を出力します。 入力の TILEDATA には real0, imm0, real1, imm1, ... のように実部と虚部が連続して格納されていると解釈されます。 tcmmrlfp16ps は実部、tcmmimfp16ps は虚部を出力します。
AVX と AMX の比較
下の図は、AVX と AMX の行列積演算の違いを示しています。 AVX が行・列ごとに少しずつ演算するのに対し、AMX は部分行列をまとめて演算できることが分かると思います。
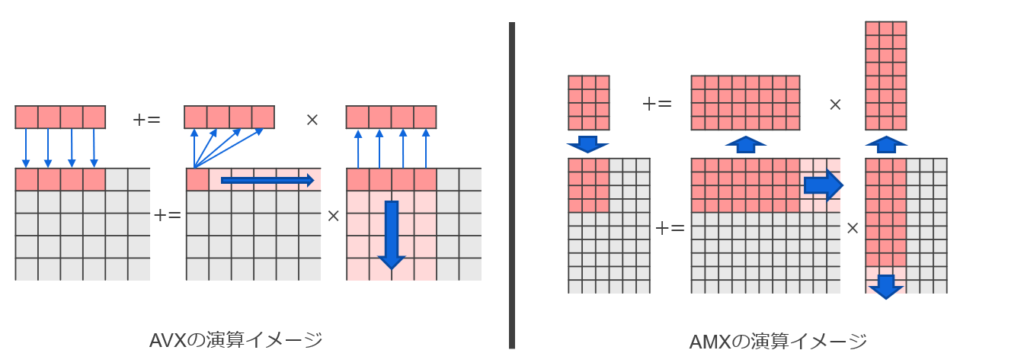
理論性能
AVX と AMX の理論性能を比較してみます。 CPU は Xeon Platinum 8480 (Sapphire Rapids) で、周波数 3.4 GHz で動作するとします。
AVX は、最高効率の _mm512_fmadd_ph (vfmadd***ph) を考えます。
vfmadd***phは 512-bit を処理でき、FMA (和と積が 1 回ずつ)で、スループット 0.5 [inst/cycle] のため、(512/16) × 2 × 0.5 = 32 [FLO/instruction]- 3.4 GHz の CPU は 3.4 G 個の命令を処理できるため、3.4 × 109 [instruction/(Core*s)]
- 56 個の物理コアを持つため 56 [Core]
- 1 物理コアが 2 port 持つため、2 [ports]
- 上記をかけ合わせると、11.9 [TFLOPS]
AMX は BF16 を処理する tdpbf16ps を考えます。
- タイルサイズが最大の時、以下の計算から (32×2) × ((64×16)/4)/16 = 1024 [FLO/instruction]
- デスティネーション TILEDATA の一要素あたり FMA を 32 回行い、自身に加算するため 32 × 2 [FLO/elem]
- デスティネーション TILEDATA は FP32 になるため、(64×16)/4 [elem]
tdpb16psのスループットは 16
- 3.4 GHz の CPU は 3.4 G 個の命令を処理できるため、3.4 × 109 [instruction/(Core*s)]
- 56 個の物理コアを持つため 56 [Core]
- 上記をかけ合わせると、195 [TFLOPS]
よって、理想的で純粋な計算能力では AMX は AVX 比で 16 倍程度の FLOPS を出せることが分かります。 ただし、実際には、AVX は頻繁なレジスタ入れ替えが必要だったり、AMX はタイル設定が必要だったりします。 ユースケースによって AMX が 10 倍以上の性能を発揮することもあれば、2 倍程度に収まってしまうこともあると思います。 AMX の適用時には、ユースケースの特性、ボトルネック解析などを行い、適切なチューニングを行う必要があります。
サンプルコード
AMX の簡単なサンプルコードを示します。 本記事のサンプルコードは、clang++ でコンパイルすることを前提としています。 clang++ は __tile1024i 構造体を使った intrinsic をサポートしており、TILECFG の操作を隠蔽できるためです。 g++ の場合は、tileconfig_t を使って TILECFG を明示的に設定する必要があります。
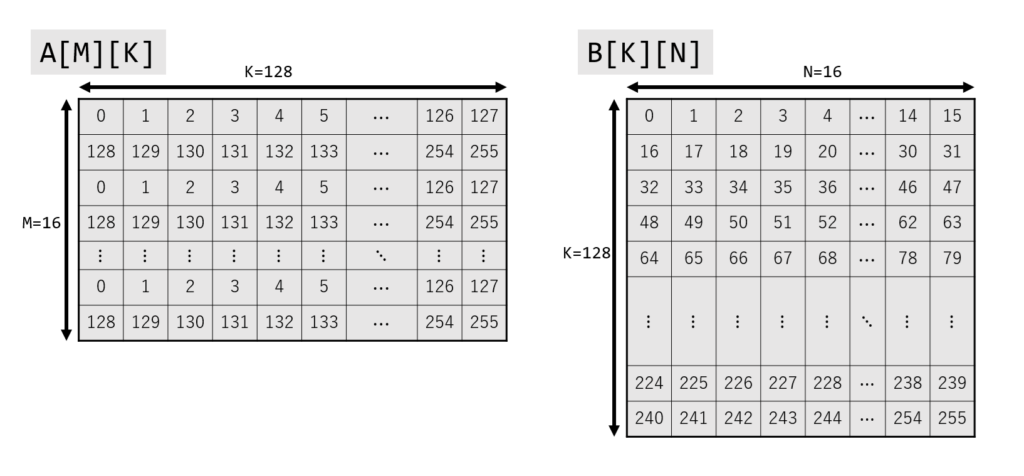
サンプルコードでは、符号なし INT8 行列積:INT8 行列 A[M][K] と INT8 行列 B[K][N] から、INT32 行列 C[M][N] を計算しています。 M = 16, K = 128, N = 16 と設定しました。 TILEDATA は最大で 16 行 x 64-byte を扱えるので、A と B をそれぞれ 2 個に分割して計算します。
必要な操作について、順に解説します。
ヘッダの include
AMX の Instrinsics は、AVX と同じく immintrin.h を include すると参照できます。
#include <immintrin.h>
AMX 有効化
AMX はデフォルトで無効化されている場合があるため、arch_prctl システムコールで有効化しておきます。
if (syscall(SYS_arch_prctl, ARCH_REQ_XCOMP_PERM, XFEATURE_XTILEDATA) < 0) {
printf("Failed to enable XFEATURE_XTILEDATA\n");
exit(-1);
}
行列 A, B, C の初期化
A, B, C を用意し、A, B を適当な値で初期化します。 C の型が uint32_t であることに注意してください。 (A, B の型は uint8_t のため256で割った余りを使っており、途中で 0 に戻っています。)
std::array<std::uint8_t, M * K> A;
std::array<std::uint8_t, K * N> B;
std::array<std::uint32_t, M * N> C;
for (int i = 0; i < M; i++) {
for (int j = 0; j < K; j++) {
A[(i * K) + j] = static_cast<std::uint8_t>(((i * K) + j) % 256);
}
}
for (int i = 0; i < K; i++) {
for (int j = 0; j < N; j++) {
B[(i * N) + j] = static_cast<std::uint8_t>(((i * N) + j) % 256);
}
}
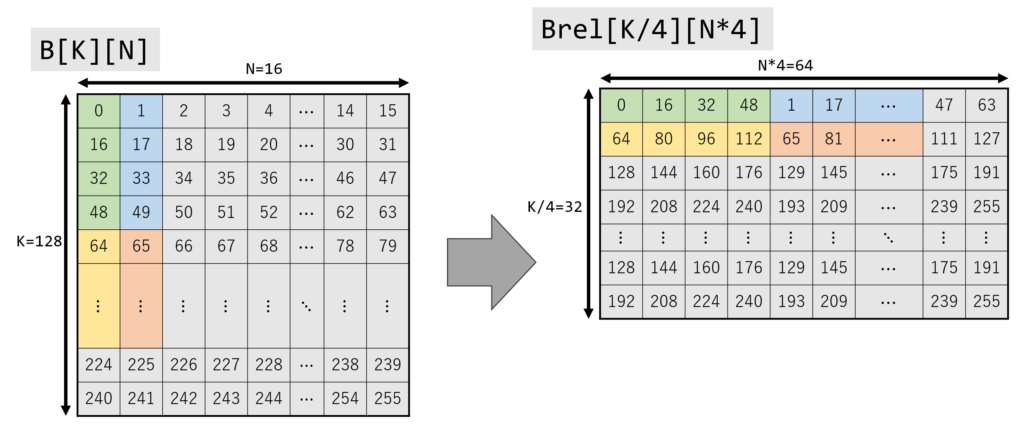
B のメモリ配置変更
AMX に合わせて B のデータを並び変えます。 この時、Brel の行数と列数が変化していることに注意してください。 Brel の行数は、B の行数を 4 で割った数と同じになります。(今回は B は 128 行なので、Brel の行数は 32)
std::array<std::uint8_t, (K / 4) * (N * 4)> Brel;
for (int i = 0; i < K; i += 4) {
for (int j = 0; j < N; j++) {
Brel[(i * N) + (j * 4) + 0] = B[((i + 0) * N) + j];
Brel[(i * N) + (j * 4) + 1] = B[((i + 1) * N) + j];
Brel[(i * N) + (j * 4) + 2] = B[((i + 2) * N) + j];
Brel[(i * N) + (j * 4) + 3] = B[((i + 3) * N) + j];
}
}
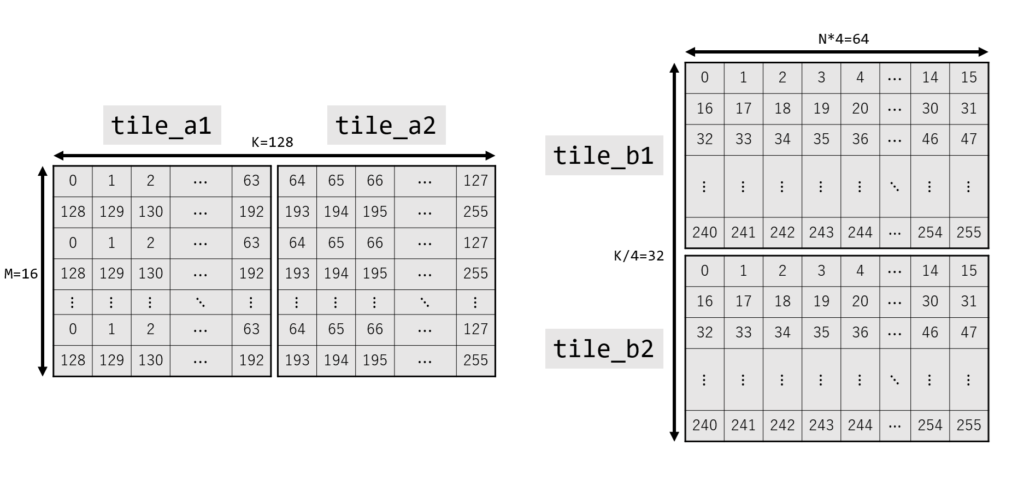
タイル設定
TILEDATA を初期化します。 指定している __tile1024i の引数は行列サイズで、rows, colb の順で指定します。 サンプルコードでは、全て rows = 16, colb = 64 になります。
それぞれ、下の図の tile に対応します。
__tile1024i tile_a1 = {M, K / 2}; // {16, 64}
__tile1024i tile_a2 = {M, K / 2}; // {16, 64}
__tile1024i tile_b1 = {K / 4 / 2, N * 4}; // {16, 64}
__tile1024i tile_b2 = {K / 4 / 2, N * 4}; // {16, 64}
__tile1024i tile_c = {M, N * 4}; // {16, 64}
タイルロード
行列 A, Brel を TILEDATA にロードします。 それぞれ K [bytes/row]、N*4 [bytes/row]、型は uint8_t なので、stride は K と N*4 になります。
__tile_loadd(&tile_a1, A.data(), K);
__tile_loadd(&tile_a2, A.data() + (K / 2), K);
__tile_loadd(&tile_b1, Brel.data(), N * 4);
__tile_loadd(&tile_b2, Brel.data() + ((K / 4) / 2 * N * 4), N * 4);
TMUL 演算
行列積を計算します。 今回は符号なし INT8 なので、dpbuud を使用します。 TILEDATA は初期状態では暗黙的に 0 埋めされているため、tile_c に対して __tile_zero で初期化する必要はありません。
__tile_dpbuud(&tile_c, tile_a1, tile_b1);
__tile_dpbuud(&tile_c, tile_a2, tile_b2);
タイルストア
計算結果を C のメモリにストアします。各行は 4-byte の整数値を N 個で N*4-byte なので、stride には N*4 を指定しています。
__tile_stored(C.data(), N * 4, tile_c);
タイル解放
TILECFG と TILEDATA を初期状態に戻します。
_tile_release();
サンプルコード全体
上の説明で用いたサンプルコード全体を示します。
コード内のコメントは、記事内で対応する節タイトルを示しています。
サンプルコード (__tile1024i ver.)
#include <immintrin.h>
#include <sys/syscall.h>
#include <unistd.h>
#include <array>
#include <cstdint>
#include <cstdio>
constexpr int ARCH_REQ_XCOMP_PERM = 0x1023;
constexpr int XFEATURE_XTILEDATA = 18;
constexpr std::uint8_t M = 16;
constexpr std::uint8_t K = 128;
constexpr std::uint8_t N = 16;
int main() {
// AMX 有効化
if (syscall(SYS_arch_prctl, ARCH_REQ_XCOMP_PERM, XFEATURE_XTILEDATA) < 0) {
std::printf("Failed to enable XFEATURE_XTILEDATA\n");
exit(-1);
}
// 行列 A, B, C の初期化
std::array<std::uint8_t, M * K> A;
std::array<std::uint8_t, K * N> B;
std::array<std::uint32_t, M * N> C;
for (int i = 0; i < M; i++) {
for (int j = 0; j < K; j++) {
A[(i * K) + j] = static_cast<std::uint8_t>(((i * K) + j) % 256);
}
}
for (int i = 0; i < K; i++) {
for (int j = 0; j < N; j++) {
B[(i * N) + j] = static_cast<std::uint8_t>(((i * N) + j) % 256);
}
}
// B のメモリ配置変更
std::array<std::uint8_t, (K / 4) * (N * 4)> Brel;
for (int i = 0; i < K; i += 4) {
for (int j = 0; j < N; j++) {
Brel[(i * N) + (j * 4) + 0] = B[((i + 0) * N) + j];
Brel[(i * N) + (j * 4) + 1] = B[((i + 1) * N) + j];
Brel[(i * N) + (j * 4) + 2] = B[((i + 2) * N) + j];
Brel[(i * N) + (j * 4) + 3] = B[((i + 3) * N) + j];
}
}
// タイル設定
__tile1024i tile_a1 = {M, K / 2}; // {16, 64}
__tile1024i tile_a2 = {M, K / 2}; // {16, 64}
__tile1024i tile_b1 = {K / 4 / 2, N * 4}; // {16, 64}
__tile1024i tile_b2 = {K / 4 / 2, N * 4}; // {16, 64}
__tile1024i tile_c = {M, N * 4}; // {16, 64}
// タイルロード
__tile_loadd(&tile_a1, A.data(), K);
__tile_loadd(&tile_a2, A.data() + (K / 2), K);
__tile_loadd(&tile_b1, Brel.data(), N * 4);
__tile_loadd(&tile_b2, Brel.data() + ((K / 4) / 2 * N * 4), N * 4);
// TMUL 演算
__tile_dpbuud(&tile_c, tile_a1, tile_b1);
__tile_dpbuud(&tile_c, tile_a2, tile_b2);
// タイルストア
__tile_stored(C.data(), N * 4, tile_c);
// タイル解放
_tile_release();
for (int i = 0; i < M; i++) {
for (int j = 0; j < N; j++) {
std::printf("%d ", C[(i * N) + j]);
}
std::printf("\n");
}
}
GCC を使う場合や自分でレジスタ管理をしたい場合は次のようにも書くこともできます。_tile_loadconfigの呼び出しと、引数で__tile1024i構造体を指定していたところがレジスタの番号を指定するように変わってます。
関数名が__tile_*から_tile_*になっていること、_tile_storedの引数の順番が変わっていることに注意してください。
コード全体(GCC 特有の箇所には //GCC 特有 のコメントを入れています)
#include <immintrin.h>
#include <sys/syscall.h>
#include <unistd.h>
#include <array>
#include <cstdint>
#include <cstdio>
constexpr int ARCH_REQ_XCOMP_PERM = 0x1023;
constexpr int XFEATURE_XTILEDATA = 18;
constexpr std::uint8_t M = 16;
constexpr std::uint8_t K = 128;
constexpr std::uint8_t N = 16;
// GCC 特有:TILECFG を示す構造体の定義
struct tileconfig_t
{
std::uint8_t palette_id;
std::uint8_t startRow;
std::uint8_t reserved_0[14];
std::uint16_t colb[16];
std::uint8_t rows[16];
};
int main() {
if (syscall(SYS_arch_prctl, ARCH_REQ_XCOMP_PERM, XFEATURE_XTILEDATA) < 0) {
std::printf("Failed to enable XFEATURE_XTILEDATA\n");
exit(-1);
}
std::array<std::uint8_t, M * K> A;
std::array<std::uint8_t, K * N> B;
std::array<std::uint32_t, M * N> C;
for (int i = 0; i < M; i++) {
for (int j = 0; j < K; j++) {
A[(i * K) + j] = static_cast<std::uint8_t>(((i * K) + j) % 256);
}
}
for (int i = 0; i < K; i++) {
for (int j = 0; j < N; j++) {
B[(i * N) + j] = static_cast<std::uint8_t>(((i * N) + j) % 256);
}
}
std::array<std::uint8_t, (K / 4) * (N * 4)> Brel;
for (int i = 0; i < K; i += 4) {
for (int j = 0; j < N; j++) {
Brel[(i * N) + (j * 4) + 0] = B[((i + 0) * N) + j];
Brel[(i * N) + (j * 4) + 1] = B[((i + 1) * N) + j];
Brel[(i * N) + (j * 4) + 2] = B[((i + 2) * N) + j];
Brel[(i * N) + (j * 4) + 3] = B[((i + 3) * N) + j];
}
}
// GCC 特有:TILECFG の設定
const tileconfig_t config = {
.palette_id = 1,
.startRow = 0,
.colb = {K / 2, K / 2, N * 4, N * 4, N * 4}, // {64, 64, 64, 64, 64}
.rows = {M, M, K / 4 / 2, K / 4 / 2, M}, // {16, 16, 16, 16, 16}
};
_tile_loadconfig(&config);
// GCC 特有:TILEDATA の位置をタイル番号で指定
_tile_loadd(0, A.data(), K);
_tile_loadd(1, A.data() + (K / 2), K);
_tile_loadd(2, Brel.data(), N * 4);
_tile_loadd(3, Brel.data() + (K / 4 / 2 * N * 4), N * 4);
_tile_dpbuud(4, 0, 2);
_tile_dpbuud(4, 1, 3);
_tile_stored(4, C.data(), N * 4);
_tile_release();
for (int i = 0; i < M; i++) {
for (int j = 0; j < N; j++) {
std::printf("%d ", C[(i * N) + j]);
}
std::printf("\n");
}
}
コンパイル/実行
上記サンプルコードをコンパイル・実行すると、行列積が計算されて出力されます。 AMX 命令を含むため、対応コンパイラとコンパイルオプション -mamx-tile -mamx-int8 が必要です。
AMX 命令に未対応の CPU 上でも、Intel® Software Development Emulator でエミュレーションできます。 実行時は sde64 -spr -- <exec file> のように指定してください。 (spr = SaPphire Rapids)
実行している CPU が AMX をサポートしているかなどの情報については、lscpu コマンドや、cpuid 命令で確認できます。
[参考] AMXのサポート状況を判定する C++ プログラム
#include <cstdio>
#include <cpuid.h>
int main() {
unsigned int eax_07_0, ebx_07_0, ecx_07_0, edx_07_0;
unsigned int eax_07_1, ebx_07_1, ecx_07_1, edx_07_1;
unsigned int eax_0d_0, ebx_0d_0, ecx_0d_0, edx_0d_0;
unsigned int eax_1d_0, ebx_1d_0, ecx_1d_0, edx_1d_0;
unsigned int eax_1d_1, ebx_1d_1, ecx_1d_1, edx_1d_1;
unsigned int eax_1e_0, ebx_1e_0, ecx_1e_0, edx_1e_0;
__cpuid_count(0x07, 0, eax_07_0, ebx_07_0, ecx_07_0, edx_07_0);
__cpuid_count(0x07, 1, eax_07_1, ebx_07_1, ecx_07_1, edx_07_1);
__cpuid_count(0x0d, 0, eax_0d_0, ebx_0d_0, ecx_0d_0, edx_0d_0);
__cpuid_count(0x1d, 0, eax_1d_0, ebx_1d_0, ecx_1d_0, edx_1d_0);
__cpuid_count(0x1d, 1, eax_1d_1, ebx_1d_1, ecx_1d_1, edx_1d_1);
__cpuid_count(0x1e, 0, eax_1e_0, ebx_1e_0, ecx_1e_0, edx_1e_0);
std::printf("TILECFG state: %d\n", eax_0d_0>>17&1);
std::printf("TILEDATA state: %d\n", eax_0d_0>>18&1);
std::printf("AMX-BF16: %d\n", edx_07_0>>22&1);
std::printf("AMX-TILE: %d\n", edx_07_0>>24&1);
std::printf("AMX-INT8: %d\n", edx_07_0>>25&1);
std::printf("AMX-FP16: %d\n", eax_07_1>>21&1);
std::printf("AMX-COMPLEX: %d\n", edx_07_1>> 8&1);
std::printf("max_palette: %d\n", eax_1d_0);
std::printf("total_tile_bytes: %d\n", eax_1d_1 &0xffff);
std::printf("bytes_per_tile: %d\n", eax_1d_1>>16&0xffff);
std::printf("bytes_per_row: %d\n", ebx_1d_1 &0xffff);
std::printf("max_names: %d\n", ebx_1d_1>>16&0xffff);
std::printf("max_rows: %d\n", ecx_1d_1 &0xffff);
std::printf("tmul_maxk: %d\n", ebx_1e_0 &0xff);
std::printf("tmul_maxn: %d\n", ebx_1e_0>> 8&0xffff);
return 0;
}
# AMX 未サポートの CPU
TILECFG state: 0
TILEDATA state: 0
AMX-BF16: 0
AMX-TILE: 0
AMX-INT8: 0
AMX-FP16: 0
AMX-COMPLEX: 0
max_palette: 0
total_tile_bytes: 0
bytes_per_tile: 0
bytes_per_row: 0
max_names: 0
max_rows: 0
tmul_maxk: 0
tmul_maxn: 0
# AMX サポートの CPU (Sapphire Rapids)
TILECFG state: 1
TILEDATA state: 1
AMX-BF16: 1
AMX-TILE: 1
AMX-INT8: 1
AMX-FP16: 0 <=== Granite Rapids ならここも 1 になる
AMX-COMPLEX: 0
max_palette: 1
total_tile_bytes: 8192
bytes_per_tile: 1024
bytes_per_row: 64
max_names: 8
max_rows: 16
tmul_maxk: 16
tmul_maxn: 64
性能確認
実際に、AMX が AVX512 に比べてどの程度の性能が出るのか、OpenBLAS v0.3.29 を用いて確認します。
計測環境は次の通りです。
| 環境 | 設定 |
|---|---|
| OS | Red Hat Enterprise Linux 9.2 |
| CPU | Intel(R) Xeon(R) Platinum 8480CL x2 (56 Core x 2, HT-disabled) |
| メモリ | 512GB (DDR5 32GB x 16) |
| コンパイラ | g++ 14.1.0 |
| コンパイルオプション | -O3 -march=native |
計測条件は、次の 4 種類です。
- AVX512_BF16 / 1-Thread
- AVX512_BF16 / 112-Threads
- AMX (BF16) / 1-Thread
- AMX (BF16) / 112-Threads
各条件において、BF16 型の N*N 行列積を cblas_sbgemm で計算し、実行時間を計測しました。 OpenBLAS は各条件用にそれぞれコンパイルしています。AMXを使用しないようにするフラグはなかったため、ターゲットアーキテクチャとしてAMXに対応していないCooper Lakeを指定しています。
- AVX512_BF16:
TARGET=COOPERLAKE BUILD_BFLOAT16=1 - AMX (BF16):
TARGET=SAPPHIRERAPIDS BUILD_BFLOAT16=1- カーネル関数
sbgemm_kernel_16x16_spr.c
- カーネル関数
計測結果を次の表に示します。
各実装の行列サイズ N に対する実行時間([ms]、5 回平均)
| N | AMX/1スレッド | AVX512/1スレッド | AMX/112スレッド | AVX512/112スレッド |
|---|---|---|---|---|
| 512 | 0.8 | 3.9 | 0.9 | 1.1 |
| 1024 | 3.1 | 28.1 | 1.6 | 1.9 |
| 1536 | 9.0 | 93.6 | 2.3 | 2.6 |
| 2048 | 19.8 | 221.1 | 2.9 | 4.2 |
| 2560 | 37.2 | 442.5 | 6.3 | 6.4 |
| 3072 | 62.5 | 742.7 | 4.5 | 9.4 |
| 3584 | 98.1 | 1180.2 | 7.3 | 13.7 |
| 4096 | 150.4 | 1763.3 | 10.5 | 20.6 |
また、上記表をグラフにしたものを次に示します。AMX 1-Thread を基準とした正規化を行っています。
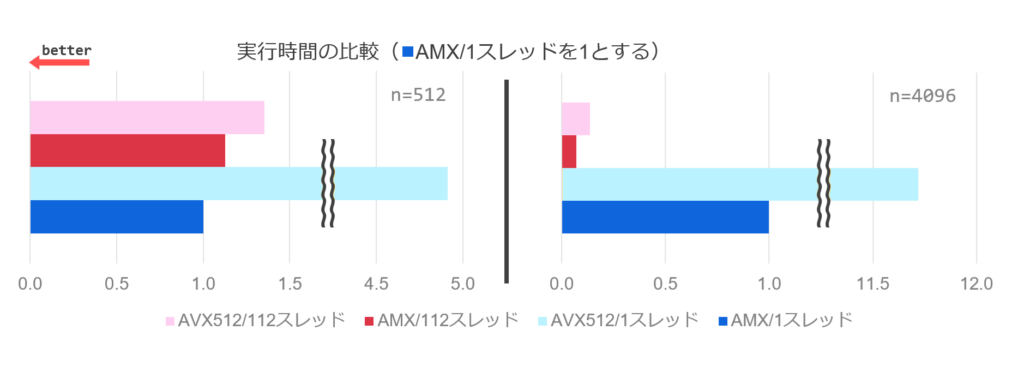
シングルスレッド性能では、AMX (青) は、AVX512 (黄) に比べて最大 11.7 倍程度 (N = 4096) 高速に計算できることが分かります。 マルチスレッド性能でも、AMX (赤) は AVX512 (緑) より勝っていますが、シングルスレッドより伸び幅は鈍化しています。 詳細は要調査ですが、各種最適化、演算器自体の動作周波数などが影響していると考えられます。
まとめ
本記事では、AMX の命令セットから AVX との性能比較まで、詳細に行いました。
次回は AMX の性能を引き出すための最適化について紹介します! お楽しみに!
参考資料
- Intel® Intrinsics Guide, https://www.intel.com/content/www/us/en/docs/intrinsics-guide/index.html
- Intel® Architecture Instruction Set Extensions Programming Reference, https://www.intel.com/content/www/us/en/content-details/843860/intel-architecture-instruction-set-extensions-programming-reference.html
- Intel® 64 and IA-32 Architectures Software Developer’s Manual, https://www.intel.co.jp/content/www/jp/ja/content-details/782158/intel-64-and-ia-32-architectures-software-developer-s-manual-combined-volumes-1-2a-2b-2c-2d-3a-3b-3c-3d-and-4.html
- Intel® 64 and IA-32 Architectures Optimization Reference Manual: Volume 1, https://www.intel.co.jp/content/www/jp/ja/content-details/671488/intel-64-and-ia-32-architectures-optimization-reference-manual-volume-1.html

Tags
About Author
OmoriYu
Leave a Comment
Tags
Favorite Post

 2023年1月27日
2023年1月27日 2017年8月22日
2017年8月22日
Archives
- 2026年2月
- 2026年1月
- 2025年12月
- 2025年11月
- 2025年8月
- 2025年5月
- 2025年4月
- 2024年11月
- 2024年10月
- 2024年7月
- 2024年5月
- 2024年4月
- 2024年2月
- 2024年1月
- 2023年12月
- 2023年6月
- 2023年5月
- 2023年4月
- 2023年2月
- 2023年1月
- 2022年12月
- 2022年10月
- 2021年11月
- 2021年9月
- 2021年6月
- 2021年3月
- 2021年2月
- 2020年12月
- 2020年10月
- 2020年7月
- 2020年6月
- 2020年5月
- 2020年4月
- 2020年3月
- 2020年2月
- 2020年1月
- 2019年12月
- 2019年11月
- 2019年10月
- 2019年9月
- 2019年8月
- 2019年6月
- 2019年4月
- 2019年3月
- 2019年2月
- 2019年1月
- 2018年12月
- 2018年11月
- 2018年10月
- 2018年8月
- 2018年6月
- 2018年5月
- 2018年4月
- 2018年3月
- 2018年2月
- 2017年12月
- 2017年11月
- 2017年10月
- 2017年9月
- 2017年8月
- 2017年7月
- 2017年6月
- 2017年5月
- 2017年3月
- 2016年12月
- 2016年11月
- 2016年8月
- 2016年7月
- 2016年3月
- 2016年2月
- 2016年1月
- 2015年12月
- 2015年11月
- 2015年10月
- 2015年8月
- 2015年6月
- 2015年3月
- 2015年2月
- 2015年1月
- 2014年12月
- 2014年11月
keisuke.kimura in Livox Mid-360をROS1/ROS2で動かしてみた
Sorry for the delay in replying. I have done SLAM (FAST_LIO) with Livox MID360, but for various reasons I have not be...
Miya in ウエハースケールエンジン向けSimulated Annealingを複数タイルによる並列化で実装しました
作成されたプロファイラがとても良さそうです :) ぜひ詳細を書いていただきたいです!...
Deivaprakash in Livox Mid-360をROS1/ROS2で動かしてみた
Hey guys myself deiva from India currently i am working in this Livox MID360 and eager to knwo whether you have done the...
岩崎システム設計 岩崎 満 in Alveo U50で10G Ethernetを試してみる
仕事の都合で、検索を行い、御社サイトにたどりつきました。 内容は大変参考になりま�...
Prabuddhi Wariyapperuma in Livox Mid-360をROS1/ROS2で動かしてみた
This issue was sorted....