このブログは、株式会社フィックスターズのエンジニアが、あらゆるテーマについて自由に書いているブログです。
llama.cpp を使って RTX 6000 Ada で Llama 4 Scout を動かす
以前の検証では、 Llama 4 Scout を動かすために NVIDIA H100 GPU が搭載されたサーバーを使っていました。 H100 はコストが高く、消費電力や騒音などの面からも導入できる場所は限られています。今回はその代替として、比較的安価で静音性に優れた RTX 6000 Ada が 2 枚搭載されたサーバー で Llama 4 Scout を動かす方法を解説します。
環境構築
バックエンドとして今回は llama.cpp を利用します。
git clone git@github.com:ggml-org/llama.cpp.git
cd llama.cpp
llama.cpp に対応した gguf 形式の Llama 4 Scout モデルをダウンロードします。このモデルは前回とは異なり既に int4 量子化されています。
wget https://huggingface.co/unsloth/Llama-4-Scout-17B-16E-Instruct-GGUF/resolve/main/Q4_K_M/Llama-4-Scout-17B-16E-Instruct-Q4_K_M-00001-of-00002.gguf
wget https://huggingface.co/unsloth/Llama-4-Scout-17B-16E-Instruct-GGUF/resolve/main/Q4_K_M/Llama-4-Scout-17B-16E-Instruct-Q4_K_M-00002-of-00002.gguf
ビルドを実行します。今回は GPU を使うので、 CUDA を有効にします。
cmake -B build -DGGML_CUDA=ON
cmake --build build --config Release . -j $(nproc)
ビルドが完了したらバージョンを確認します。
./build/bin/llama-cli --version
下記の環境であることが確認できました。
ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no
ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no
ggml_cuda_init: found 2 CUDA devices:
Device 0: NVIDIA RTX 6000 Ada Generation, compute capability 8.9, VMM: yes
Device 1: NVIDIA RTX 6000 Ada Generation, compute capability 8.9, VMM: yes
version: 5106 (47ba87d0)
built with cc (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0 for x86_64-linux-gnu
動作確認
次のコマンドでモデルとのチャットを始めることができます。
./build/bin/llama-cli -m Llama-4-Scout-17B-16E-Instruct-Q4_K_M-00001-of-00002.gguf
ただし、GPU 利用率を確認するとほとんど使われていないことが分かります。
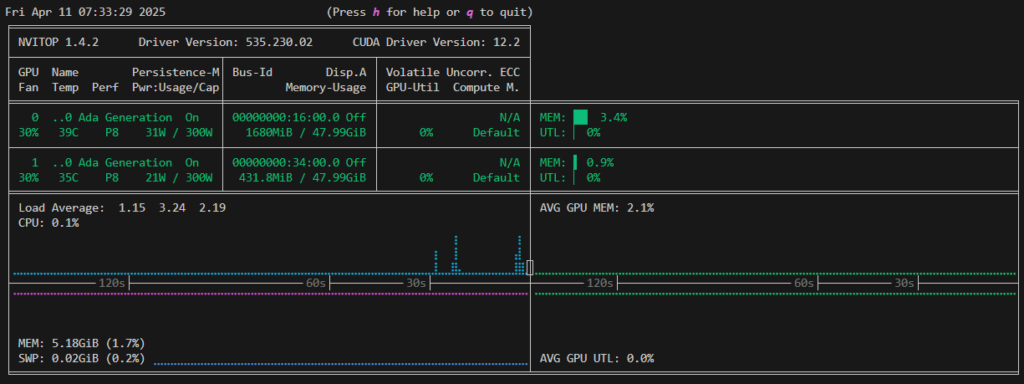
実行速度も 13 tokens/sec とかなり遅い状態となっています。
llama_perf_sampler_print: sampling time = 2.40 ms / 31 runs ( 0.08 ms per token, 12911.29 tokens per second)
llama_perf_context_print: load time = 3647.47 ms
llama_perf_context_print: prompt eval time = 1146.86 ms / 29 tokens ( 39.55 ms per token, 25.29 tokens per second)
llama_perf_context_print: eval time = 2221.27 ms / 29 runs ( 76.60 ms per token, 13.06 tokens per second)
llama_perf_context_print: total time = 298561.78 ms / 58 tokens
ログを確認すると、レイヤが GPU にオフロードされていませんでした。
load_tensors: offloaded 0/49 layers to GPU
--n-gpu-layers オプションを指定して、オフロードするレイヤ数を指定します。今回は 49 レイヤすべてを GPU にオフロードします。
./build/bin/llama-cli -m Llama-4-Scout-17B-16E-Instruct-Q4_K_M-00001-of-00002.gguf --n-gpu-layers 49
レイヤが GPU にオフロードされているためGPUメモリ利用率が上昇しており、実行速度も 54 tokens/sec に向上していることも分かります。
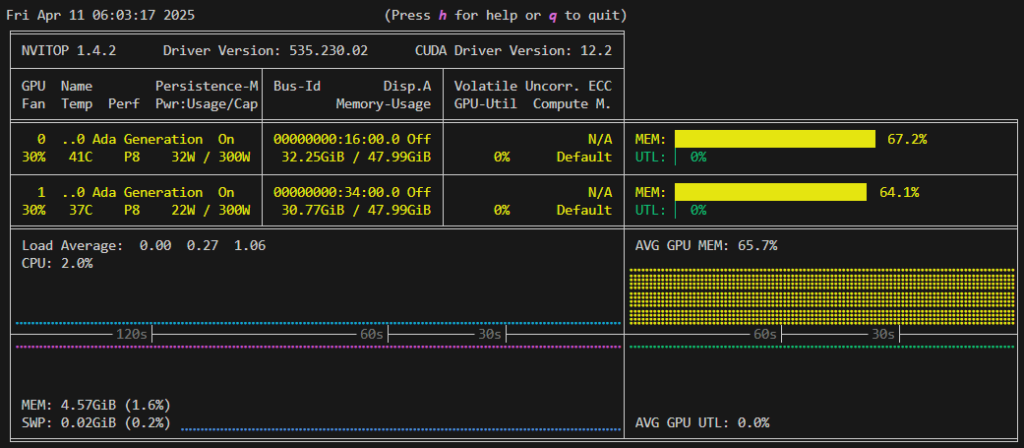
llama_perf_sampler_print: sampling time = 4.43 ms / 47 runs ( 0.09 ms per token, 10616.67 tokens per second)
llama_perf_context_print: load time = 10594.40 ms
llama_perf_context_print: prompt eval time = 641.05 ms / 148 tokens ( 4.33 ms per token, 230.87 tokens per second)
llama_perf_context_print: eval time = 22941.50 ms / 1246 runs ( 18.41 ms per token, 54.31 tokens per second)
llama_perf_context_print: total time = 560738.71 ms / 1394 tokens
ベンチマーク比較(llama.cpp vs vLLM)
次に、 llama-bench で推論速度を確認します。GPU を利用した場合、推論速度は 56 tokens/sec となり、チャットとほぼ同じ速度であることが確認できました。
./build/bin/llama-bench -m Llama-4-Scout-17B-16E-Instruct-Q4_K_M-00001-of-00002.gguf
ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no
ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no
ggml_cuda_init: found 2 CUDA devices:
Device 0: NVIDIA RTX 6000 Ada Generation, compute capability 8.9, VMM: yes
Device 1: NVIDIA RTX 6000 Ada Generation, compute capability 8.9, VMM: yes
| model | size | params | backend | ngl | test | t/s |
| ------------------------------ | ---------: | ---------: | ---------- | --: | ------------: | -------------------: |
| llama4 17Bx16E (Scout) Q4_K - Medium | 60.86 GiB | 107.77 B | CUDA | 99 | pp512 | 2356.32 ± 7.54 |
| llama4 17Bx16E (Scout) Q4_K - Medium | 60.86 GiB | 107.77 B | CUDA | 99 | tg128 | 56.00 ± 0.01 |
build: 47ba87d0 (5106)
以前の記事 で vLLM による推論について確認しましたが、このときの実行速度は 70 tokens/sec 程度となっていました。それに比べると若干遅いため llama.cpp は小規模なワークロードに適しており、大規模な場合は vLLM など別のライブラリを使うのが良いと考えられます。
なお、 CPU (Intel(R) Xeon(R) w5-3535X, 20C40T) のみを使った場合は 12 tokens/sec となっています。リアルタイム性や大量処理が必要ではないユースケースであれば、 CPU のみを使っても低コストで推論を試すことができます。
CUDA_VISIBLE_DEVICES= ./build/bin/llama-bench -m Llama-4-Scout-17B-16E-Instruct-Q4_K_M-00001-of-00002.gguf
ggml_cuda_init: failed to initialize CUDA: no CUDA-capable device is detected
| model | size | params | backend | ngl | test | t/s |
| ------------------------------ | ---------: | ---------: | ---------- | --: | ------------: | -------------------: |
| llama4 17Bx16E (Scout) Q4_K - Medium | 60.86 GiB | 107.77 B | CUDA | 99 | pp512 | 44.13 ± 0.23 |
| llama4 17Bx16E (Scout) Q4_K - Medium | 60.86 GiB | 107.77 B | CUDA | 99 | tg128 | 11.99 ± 0.06 |
build: 47ba87d0 (5106)
まとめ
Llama 4 Scout をNVIDIA H100 以外でデプロイする選択肢として RTX 6000 Ada と llama.cpp を利用する方法を紹介しました。また、同じモデルでも実装や環境によって速度が変わることが確認できました。
引き続き、GPUベンチマークやAI推論環境に関する検証を継続し、様々な環境における最適なデプロイ構成について考えていきます。

Tags
About Author
kota.iizuka
Leave a Comment
Tags
Favorite Post

 2023年1月27日
2023年1月27日 2017年8月22日
2017年8月22日
Archives
- 2026年2月
- 2026年1月
- 2025年12月
- 2025年11月
- 2025年8月
- 2025年5月
- 2025年4月
- 2024年11月
- 2024年10月
- 2024年7月
- 2024年5月
- 2024年4月
- 2024年2月
- 2024年1月
- 2023年12月
- 2023年6月
- 2023年5月
- 2023年4月
- 2023年2月
- 2023年1月
- 2022年12月
- 2022年10月
- 2021年11月
- 2021年9月
- 2021年6月
- 2021年3月
- 2021年2月
- 2020年12月
- 2020年10月
- 2020年7月
- 2020年6月
- 2020年5月
- 2020年4月
- 2020年3月
- 2020年2月
- 2020年1月
- 2019年12月
- 2019年11月
- 2019年10月
- 2019年9月
- 2019年8月
- 2019年6月
- 2019年4月
- 2019年3月
- 2019年2月
- 2019年1月
- 2018年12月
- 2018年11月
- 2018年10月
- 2018年8月
- 2018年6月
- 2018年5月
- 2018年4月
- 2018年3月
- 2018年2月
- 2017年12月
- 2017年11月
- 2017年10月
- 2017年9月
- 2017年8月
- 2017年7月
- 2017年6月
- 2017年5月
- 2017年3月
- 2016年12月
- 2016年11月
- 2016年8月
- 2016年7月
- 2016年3月
- 2016年2月
- 2016年1月
- 2015年12月
- 2015年11月
- 2015年10月
- 2015年8月
- 2015年6月
- 2015年3月
- 2015年2月
- 2015年1月
- 2014年12月
- 2014年11月
keisuke.kimura in Livox Mid-360をROS1/ROS2で動かしてみた
Sorry for the delay in replying. I have done SLAM (FAST_LIO) with Livox MID360, but for various reasons I have not be...
Miya in ウエハースケールエンジン向けSimulated Annealingを複数タイルによる並列化で実装しました
作成されたプロファイラがとても良さそうです :) ぜひ詳細を書いていただきたいです!...
Deivaprakash in Livox Mid-360をROS1/ROS2で動かしてみた
Hey guys myself deiva from India currently i am working in this Livox MID360 and eager to knwo whether you have done the...
岩崎システム設計 岩崎 満 in Alveo U50で10G Ethernetを試してみる
仕事の都合で、検索を行い、御社サイトにたどりつきました。 内容は大変参考になりま�...
Prabuddhi Wariyapperuma in Livox Mid-360をROS1/ROS2で動かしてみた
This issue was sorted....