このブログは、株式会社フィックスターズのエンジニアが、あらゆるテーマについて自由に書いているブログです。
AIStationで LLM 強化学習はどこまで可能か:verl を用いた 3B/7B モデルの検証
概要
- Fixstars AIStation(以降 AIStation)を利用し、verl による強化学習を試行しました。
- 検証の結果、特定の条件下において、 Qwen2.5-7B-Instruct は OOM(Out of Memory)により学習不可能でしたが、より小さいモデルである Qwen2.5-3B-Instruct は学習可能であることが判明しました。
- このことから、条件に依存するものの、小規模なパラメータを持つモデルであれば、AIStation でも verl による強化学習が実施可能であることが示されました。
はじめに
こんにちは、ソリューション第四事業部ディレクターの森高です。
フィックスターズは AIStation という製品を提供しています。AIStation は NVIDIA RTX PRO 6000 Blackwell Max-Q Workstation Edition(以降 Max-Q)を 2 枚搭載しています。AIStation については [1] を、Max-Q の詳細を知るには過去の投稿 [2] を参照してください。
これまでに、当社は AIStation 上で BLAS ベンチマークの試行 [3] や、LoRA による学習 [4] を実施しました。本稿では、verl [5] という OSS の強化学習フレームワークを使って AIStation 上で強化学習を試します。
本稿では AIStation で verl を動かしたとき、どれくらいの性能が出るのか試した結果を示します。まずは verl で強化学習できるのかを確かめ、そのあと verl のパラメータを振って動作する限界を探します。
verl について
verl は ByteDance Seed チームが開発を始め、現在は verl コミュニティがメンテナンスをしている LLM 向け強化学習のフレームワークで、[6] のオープンソース版実装です。verl は、RL アルゴリズムの変更や既存の LLM との統合も簡単であるなど柔軟性を備え、さらに SoTA クラスのスループットを発揮するフレームワークであると言われています。今回はこの verl を利用した強化学習を AIStation で試してみました。
実験内容概要
verl を使って GSM8K [7] というデータセットの学習 2 種類の実験を行いました。1 つは学習を完走させることです。もう 1 つは短時間の性能計測のみを行い学習を途中 10 ステップで打ち切ります。それぞれの学習のスループットやメモリ消費量、消費電力を測定します。
実験環境
以下に実験環境のハードウェアや OS、フレームワークなどの機種、バージョンを示します。学習実行時に設定する各種パラメータはここには記載せず後述の実験結果と考察セクションに記載します。
表:実験環境
| 項目 | 値 |
|---|---|
| CPU | Intel(R) Xeon(R) w5-2455X |
| Memory | 256 GB |
| GPU | NVIDIA RTX PRO 6000 Blackwell Max-Q Workstation Edition (Driver: 580.95.05) (x 2) |
| OS | Ubuntu 24.04 |
| Kernel | 6.8.0-87-generic |
| Docker | Docker version 28.5.2, build ecc6942 |
| PyTorch | 2.8.0+cu128 |
| verl | v0.6.1 (d62da495) |
※現在提供中の AIStation とは一部スペックが異なります。ただし GPU のスペック、枚数は同じです。
測定の方法について以下に補足します。
- スループットは verl の出力するログの値
perf/throughputを測定値として利用します。perf/throughputはTokens processed per second per GPUです(参考 [8])。 - メモリ消費量、消費電力は
nvidia-smiの出力を測定値として利用します。
実験結果
以下に実験結果を示します。
完走実験
まずは以下のパラメータで学習を完走させた結果を示します。ここでいう完走は、後述の性能測定実験とは対照的に、ステップ数を指定するオプション
trainer.total_training_steps は何も指定せず
--epochs=1 オプションを指定し実行したものです。
表:完走実験のパラメータ
| 項目 | 値 |
|---|---|
| モデル | Qwen2.5-3B-Instruct |
| アルゴリズム | Proximal Policy Optimization (PPO) [9] |
| GPU 数 | 1 |
| バッチサイズ | 256 |
| ミニバッチサイズ | 128 |
| マイクロバッチサイズ | 16 |
| プロンプトサイズ | 1024 |
| レスポンスサイズ | 1024 |
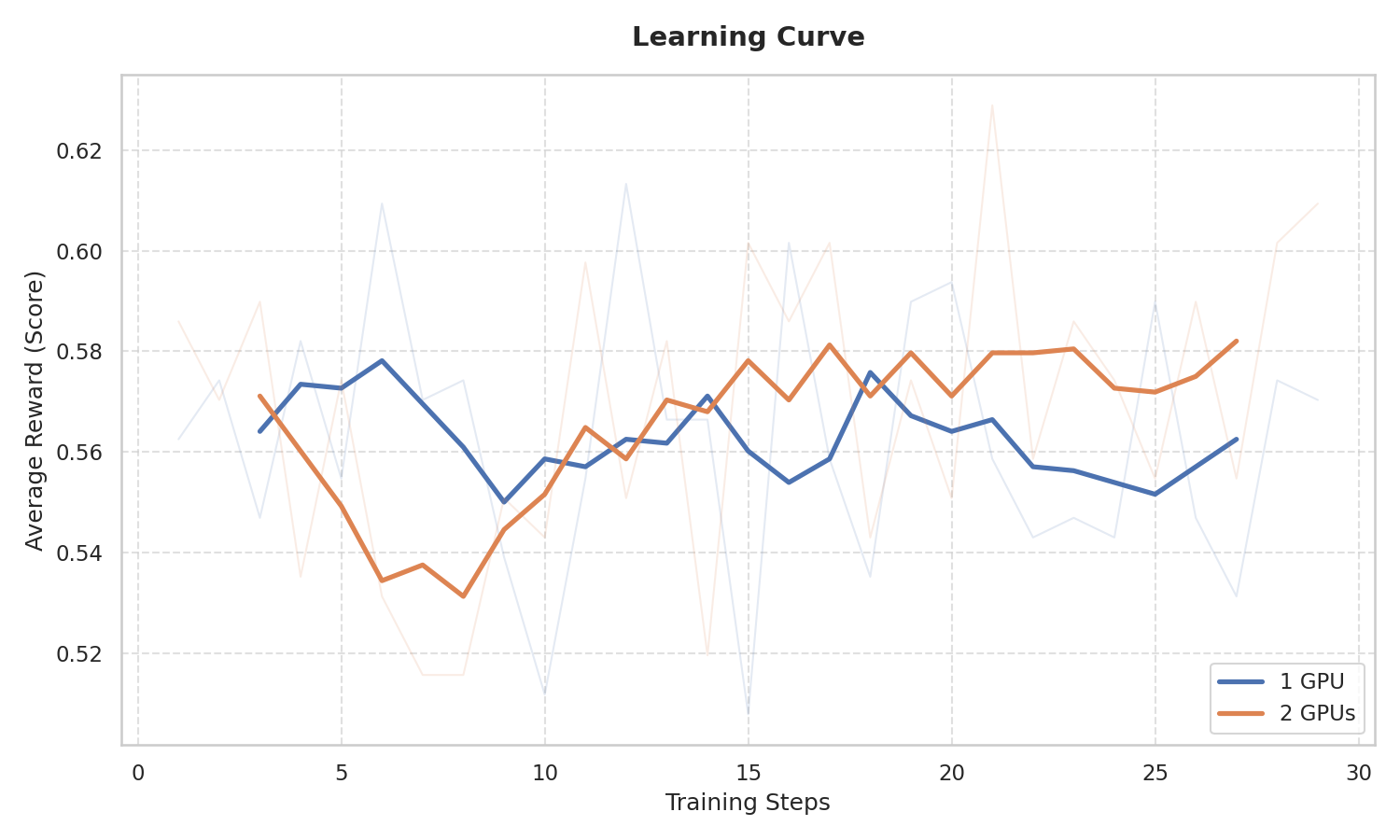
上図は学習を完走させたときの学習曲線です。薄く細い線はステップごとのスコア、太い青と橙の線はデータ全体の 5% の区間で移動平均です。ステップごとの評価だとグラフの通りスコアが乱高下するため移動平均でトレンドを示すようにしています。青い線は 1 GPU での結果、橙の線は 2 GPU での結果です。
このグラフからは、1 GPU でのスコアはほぼ横ばい、2 GPU でのスコアはやや右肩上がりであることがわかります。学習ステップ数が小さいのでこれから学習がうまくいっていることや安定性を論じるのは難しいですが、少なくとも本実験の条件では完走することが確認できました。
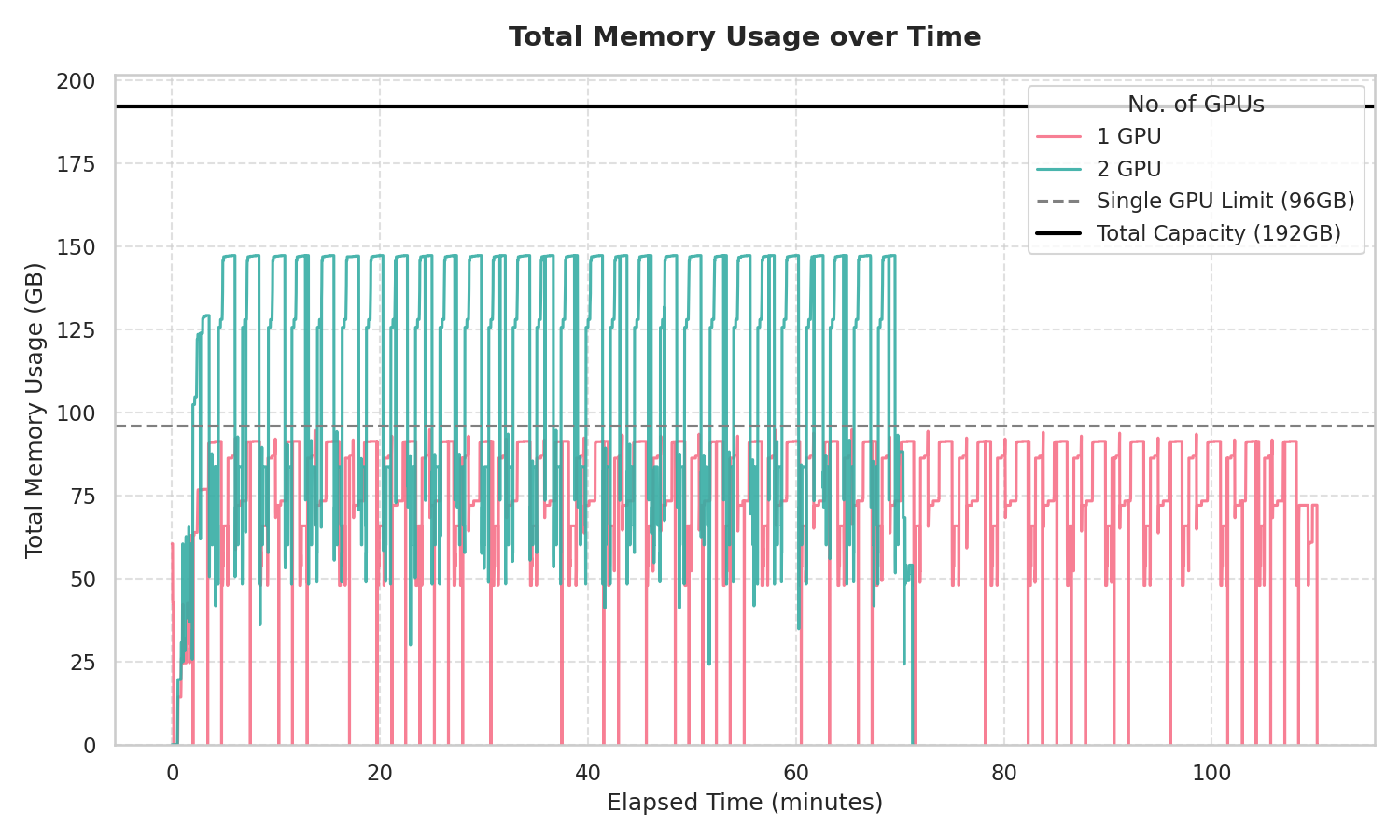
上のグラフはメモリの消費量を示します。縦軸がメモリの消費量、横軸が学習の経過時間です。赤い線が 1 GPU での消費量、青い線が 2 GPU での消費量で、黒い実線が 2 GPU の合計メモリサイズ(96 x 2 = 192 GB)、破線が 1 GPU のメモリサイズ(96 GB)を示します。
はじめに、学習時間について見てみます。各折れ線グラフの終端を見てみると、1 GPU は 110 分程度、2 GPU は 70 分程度で学習が終わっています。2 GPU にした分、バッチ数が倍に増えたため学習がより短時間で完了しています。
次にメモリの消費量です。1 GPU での結果に注目すると、黒い破線(96 GB)に触れることはなくぎりぎりのメモリ消費量で学習が完走しています。2 GPU の青い線は少し余裕をもって学習が完走していることを示しています。ただし、GPU 全体のメモリサイズが学習に必要なメモリサイズを許容しても、1 GPU に割り当てられるワークロードに必要なメモリサイズがその GPU のメモリサイズを超えると OOM になってしまうことには注意してください。
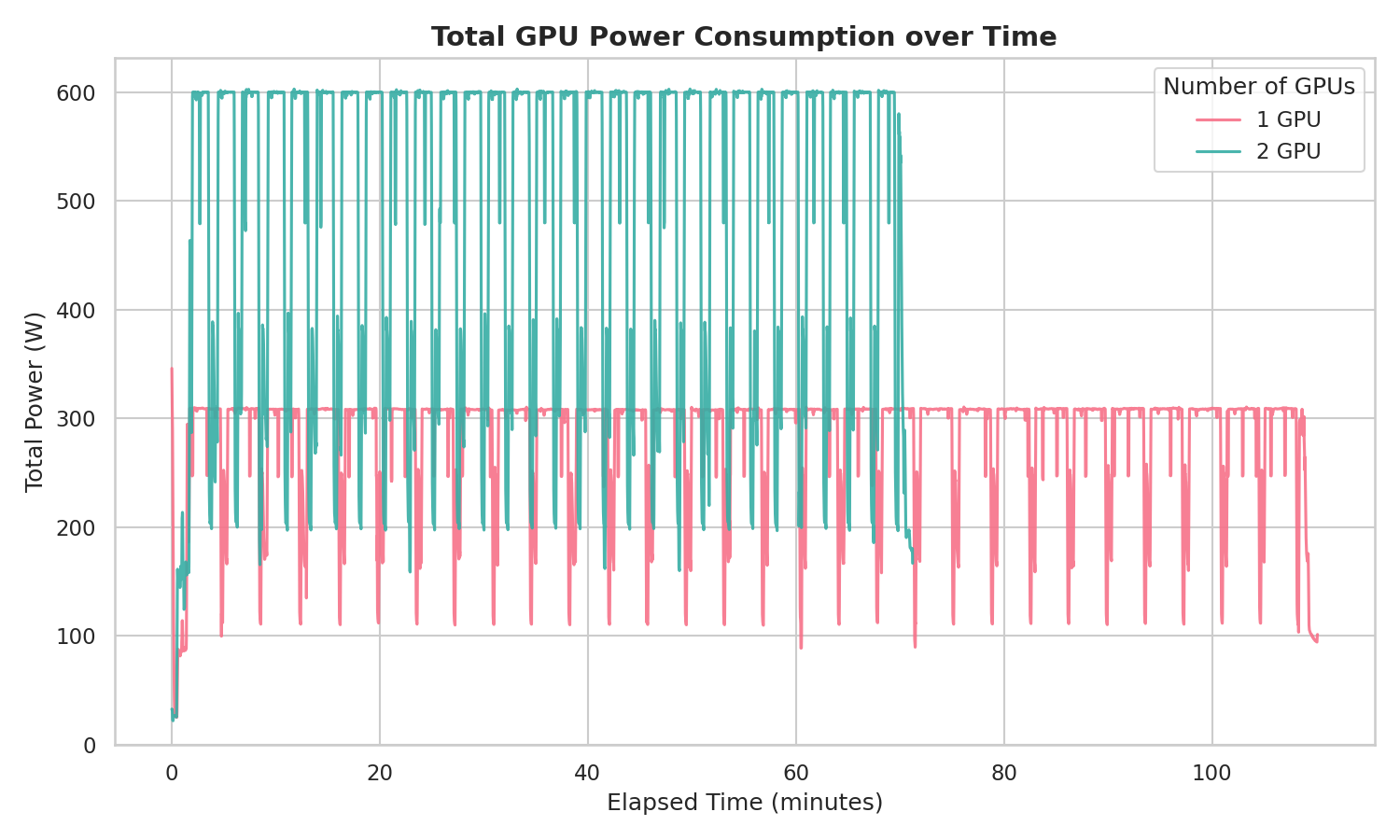
最後に、消費電力のグラフを示します。縦軸が消費電力、横軸が学習の経過時間です。赤い線が 1 GPU での消費量、青い線が 2 GPU での消費量です。
[2] によると、Max-Q の TGP は 300 W でした。1 GPU、2 GPU それぞれの場合で、TGP を少し上回る程度で学習が完走しました。
性能測定実験
次に性能測定の結果を示します。前述の通り、10 ステップで学習を打ち切っていることに注意してください。
この実験の結果は、パラメータごとに学習のスループットやそれを元に試算した学習時間、メモリ使用量、消費電力を示します。
表:性能測定実験のパラメータ
| 項目 | 値 |
|---|---|
| モデル | Qwen2.5-3B-Instruct, Qwen2.5-7B-Instruct |
| アルゴリズム | Proximal Policy Optimization (PPO) [9] |
| GPU 数 | 2 |
| バッチサイズ | 256 |
| ミニバッチサイズ | 64 |
| マイクロバッチサイズ | 1, 2, 4, …, 512 |
| プロンプトサイズ | 1024 |
| レスポンスサイズ | 1024 |
| 学習打ち切りステップ | 10 |
完走実験ではモデルは「Qwen2.5-3B-Instruct」のみを使用しましたが、性能測定実験ではそれに加え「Qwen2.5-7B-Instruct」も学習させてみます。また、マイクロバッチサイズも変化させて計測しました。実験のパラメータを増やしたのは、AIStation でどこまで学習させられるかを見たいためです。
ただし、先に断っておくと Qwen2.5-7B-Instruct の学習はいずれのパラメータでも OOM が発生しました。本稿ではグラフなどの実験結果は載せず、OOM してしまったという事実のみを記します。
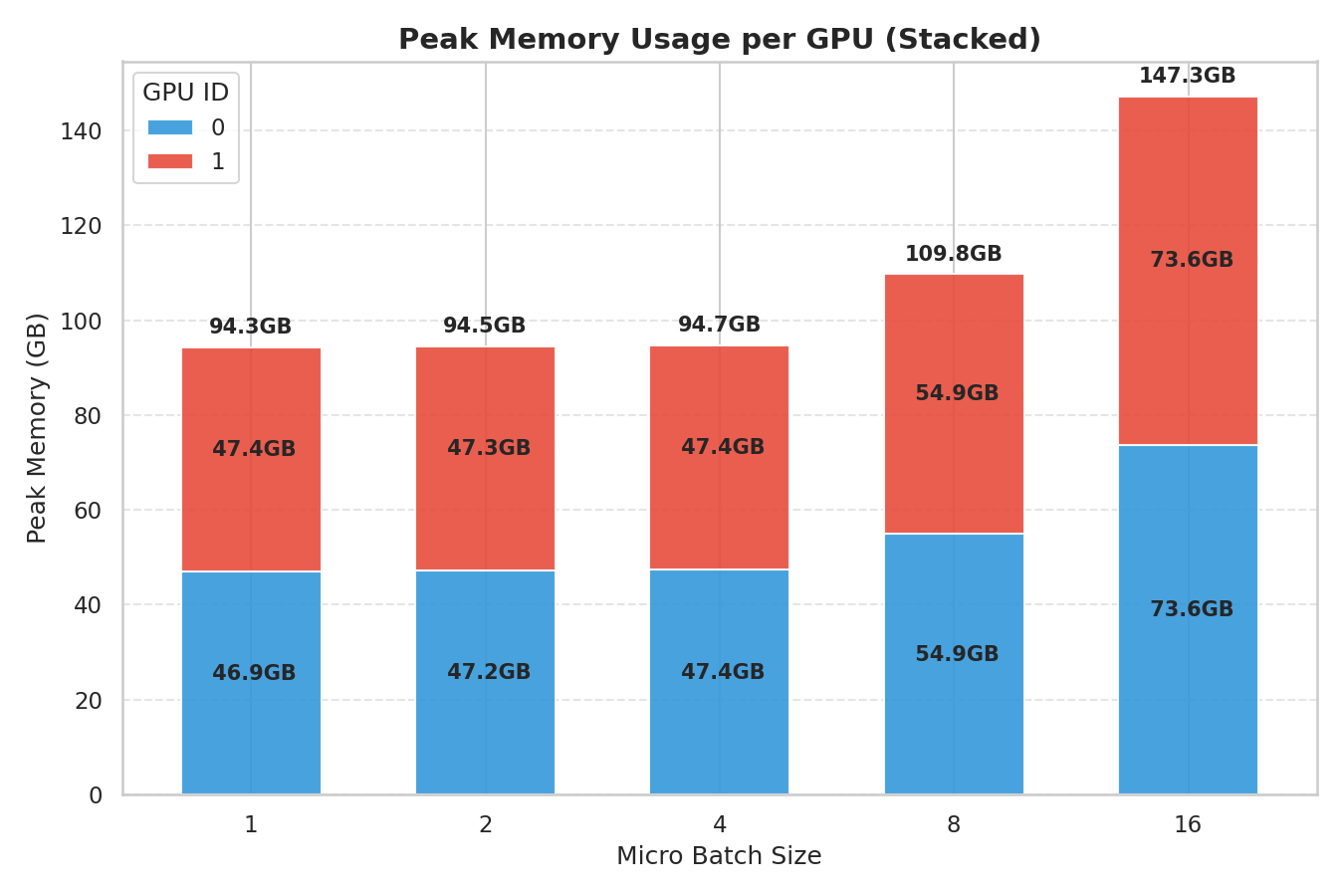
さて、上図はマイクロバッチサイズを振った時の最大のメモリ消費量を示したグラフです。横軸はマイクロバッチサイズ、縦軸は最大メモリ消費量を示します。2 GPU 分の積み上げ棒グラフであり、青が GPU 0、赤が GPU 1 を示します。
今回の実験では、両 GPU とも 96 GB を上回ることはありませんでした。最初の 10 ステップで学習を打ち切っているのですが、いずれの条件でも OOM せずに完走する可能性は十分ありそうです。
ちなみに、マイクロバッチサイズ 32 と 64 は学習開始後 OOM でエラー終了、128 以上はマイクロバッチサイズがミニバッチサイズより大きくなってしまい学習開始前にアサーションエラーでエラー終了しました。
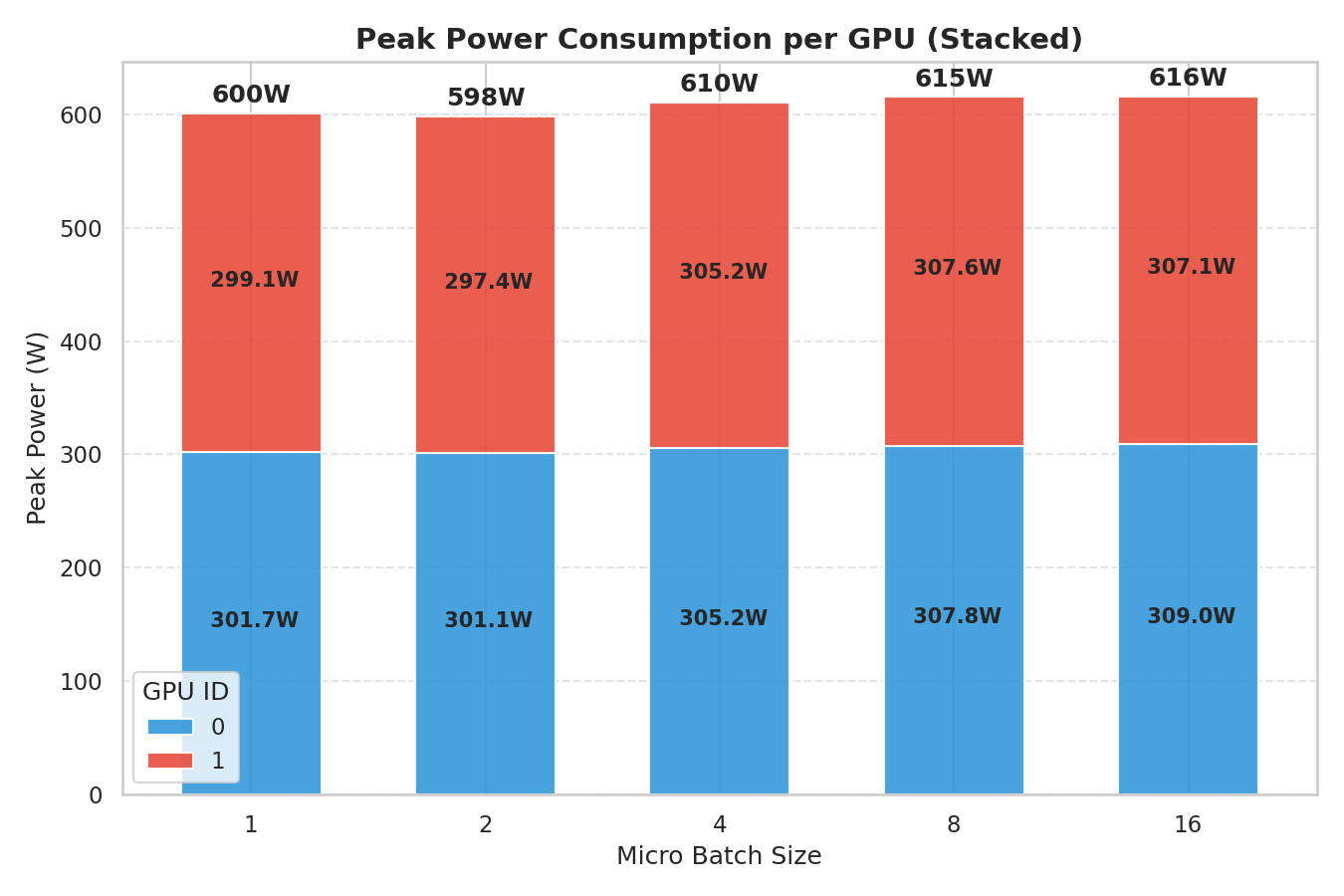
続いて消費電力のグラフです。上図はマイクロバッチサイズを振った時の最大消費電力を示したグラフです。横軸はマイクロバッチサイズ、縦軸は最大消費電力を示します。2 GPU 分の積み上げ棒グラフであり、青が GPU 0、赤が GPU 1 を示します。いずれの条件でも、600 W を大きく上回ることはありませんでした。学習を完走させていたとしても 600 W を大きく上回ることはまずないと言えそうです。
最後に、下表にスループットを示します。マイクロバッチサイズが大きくなるにつれてスループットも上がっていきますが、4 → 8 → 16 とだんだんサチっていく様子がわかります。
| Micro Batch Size | Throughput (Tokens processed / sec / GPU) |
|---|---|
| 1 | 151 |
| 2 | 246 |
| 4 | 322 |
| 8 | 349 |
| 16 | 361 |
ミニバッチサイズについて
少し話は外れますがミニバッチサイズについて実験を通してわかったことを記しておきます。今回の実験では、学習スクリプトのオプションには 128 を渡しましたが実行時には 64 になっていました。この 64 は、128 を GPU 数の 2 で割ったものだと推測されます。つまり、1 つのミニバッチはさらに GPU の数分のミニバッチに分けられていると考えられます。
本件の発見の経緯についてです。ある実験において、ミニバッチサイズ 128、マイクロバッチサイズ 128 を設定したところ、ミニバッチサイズがマイクロバッチサイズより小さいためにエラーストップすることがありました。ログを読むと上述の通りミニバッチサイズが 128 ではなく 64 になっていたので本件の発見と推測に至りました。
そのときの設定値とエラー内容は以下の通りです。いずれも verl のログより抽出しています。
設定
(TaskRunner pid=143165) 'ppo_mini_batch_size': 128,エラー
AssertionError: normalized ppo_mini_batch_size 64 should be divisible by ppo_micro_batch_size_per_gpu 128
エラーログを読めばすぐにわかることですが、verl を利用されるときはご注意ください。
まとめ
本検証を通じて、NVIDIA RTX PRO 6000 Blackwell Max-Q Workstation Edition (96GB) を搭載した AIStation における LLM 強化学習(verl)の挙動と特性について以下の知見が得られました。
- 3Bクラスモデルにおける学習の可能性
- 7B モデルではメモリ消費量がボトルネックとなり OOM が発生しましたが、3B クラスのモデルであれば 96 GB のメモリ内に収まり、一定のマイクロバッチサイズでの動作が確認できました。 このことから、より軽量なモデルを用いたアルゴリズムの動作検証や、小規模な実験サイクルを回す用途においては、本環境が有効に機能する可能性があります。
- オフィス環境への適合性(電力)
- デュアル GPU 構成で高負荷な学習を実行した際も、消費電力は合計で 600 W 前後で推移しました。 これは一般的な 100 V 電源(1500 W)の容量に対して十分な余裕があり、特別な電源設備を持たないオフィス環境でも、電力面での運用ハードルは低いと考えられます。
- 長時間稼働における安定性
- 一定の条件下では、エラーによる停止や極端な性能低下は見られず学習プロセスが完走することを確認しました。 ハードウェアおよびソフトウェア(verl)の組み合わせにおいて、一定の安定性が確保されていることが示唆されます。
最後に、AIStation は 3B クラスの軽量モデルを対象とした強化学習タスクにおいて十分なメモリ容量と安定性を備えていることが確認できました。大規模なインフラを必要とせず、身近な環境で学習実験を開始できる点において、ローカル LLM 開発の有力な選択肢の一つとなり得ると言えます。
今回は PPO というアルゴリズムを使った実験を行いましたが、今後は GRPO, GSPO など PPO 以外のアルゴリズムを使った実験も試してみたいと思います。
参考文献
- Fixstars AIStation – 最新AIをローカルLLMでセキュアに活用 – 株式会社フィックスターズ
- NVIDIA RTX PRO 6000 Blackwell Max-Q はどのようなGPUなのか? – Fixstars Tech Blog /proc/cpuinfo
- NVIDIA RTX PRO 6000 Blackwell Max-Q 上でBLASベンチマークを動かしてみる – Fixstars Tech Blog /proc/cpuinfo
- NVIDIA Blackwell 上での LoRA チューニングに向けたプロファイリングと最適化 – Fixstars Tech Blog /proc/cpuinfo
- GitHub – volcengine/verl: verl: Volcano Engine Reinforcement Learning for LLMs
- HybridFlow: A Flexible and Efficient RLHF Framework
- openai/gsm8k · Datasets at Hugging Face
- https://github.com/volcengine/verl/blob/d0997d2a0e14ce8a2a9bb19acbe47ab87ca3a498/verl/trainer/ppo/metric_utils.py#L287
- [1707.06347] Proximal Policy Optimization Algorithms

Tags
About Author
kodai.moritaka
Leave a Comment
Tags
Favorite Post

 2023年1月27日
2023年1月27日 2017年8月22日
2017年8月22日
Archives
- 2026年2月
- 2026年1月
- 2025年12月
- 2025年11月
- 2025年8月
- 2025年5月
- 2025年4月
- 2024年11月
- 2024年10月
- 2024年7月
- 2024年5月
- 2024年4月
- 2024年2月
- 2024年1月
- 2023年12月
- 2023年6月
- 2023年5月
- 2023年4月
- 2023年2月
- 2023年1月
- 2022年12月
- 2022年10月
- 2021年11月
- 2021年9月
- 2021年6月
- 2021年3月
- 2021年2月
- 2020年12月
- 2020年10月
- 2020年7月
- 2020年6月
- 2020年5月
- 2020年4月
- 2020年3月
- 2020年2月
- 2020年1月
- 2019年12月
- 2019年11月
- 2019年10月
- 2019年9月
- 2019年8月
- 2019年6月
- 2019年4月
- 2019年3月
- 2019年2月
- 2019年1月
- 2018年12月
- 2018年11月
- 2018年10月
- 2018年8月
- 2018年6月
- 2018年5月
- 2018年4月
- 2018年3月
- 2018年2月
- 2017年12月
- 2017年11月
- 2017年10月
- 2017年9月
- 2017年8月
- 2017年7月
- 2017年6月
- 2017年5月
- 2017年3月
- 2016年12月
- 2016年11月
- 2016年8月
- 2016年7月
- 2016年3月
- 2016年2月
- 2016年1月
- 2015年12月
- 2015年11月
- 2015年10月
- 2015年8月
- 2015年6月
- 2015年3月
- 2015年2月
- 2015年1月
- 2014年12月
- 2014年11月
keisuke.kimura in Livox Mid-360をROS1/ROS2で動かしてみた
Sorry for the delay in replying. I have done SLAM (FAST_LIO) with Livox MID360, but for various reasons I have not be...
Miya in ウエハースケールエンジン向けSimulated Annealingを複数タイルによる並列化で実装しました
作成されたプロファイラがとても良さそうです :) ぜひ詳細を書いていただきたいです!...
Deivaprakash in Livox Mid-360をROS1/ROS2で動かしてみた
Hey guys myself deiva from India currently i am working in this Livox MID360 and eager to knwo whether you have done the...
岩崎システム設計 岩崎 満 in Alveo U50で10G Ethernetを試してみる
仕事の都合で、検索を行い、御社サイトにたどりつきました。 内容は大変参考になりま�...
Prabuddhi Wariyapperuma in Livox Mid-360をROS1/ROS2で動かしてみた
This issue was sorted....