このブログは、株式会社フィックスターズのエンジニアが、あらゆるテーマについて自由に書いているブログです。
NVIDIA Blackwell におけるマルチモーダル学習の高速化
はじめに
Fixstars でアルバイトをしている若林大起です。
これまでの連載では、LoRA 学習のプロファイリング や MPS による GPU 活用 を通じて、同アーキテクチャの性能を引き出す手法を模索してきました。しかし、画像とテキストを同時に扱う大規模マルチモーダルモデル (LMM) は、その計算コストの高さと複雑なデータ構造ゆえに、単一のテキストモデルよりも最適化の難易度が高い傾向にあります。そこで今回は、LMM の学習最適化におけるベストプラクティスを調査するため、NVIDIA Blackwell アーキテクチャおよび LLaVA-NeXT を題材に、LLM の高速化で一般に用いられる FP8 量子化や torch.compile の導入による高速化の効果とトレードオフを体系的に検証します。また、動的シェイプによる再コンパイルの増加など、今回の検証を通じて確認できた LMM 特有の高速化の課題についても詳述します。
背景:ローカル LMM の需要増と、最適化の必要性
GPT-4V [1] の登場以降、画像とテキストを統合的に理解する LMM の活用が急速に進んでいます。特にオープンソースコミュニティでは LLaVA-NeXT [2] のような高性能モデルが登場し、機密情報を扱うオンプレミス環境や、特定のドメイン(医療画像診断、製造ラインの監視、アニメーション制作など)に特化させるためのファインチューニングをローカル環境で実行するケースが増えています。例えば、鉄鋼表面の微細な欠陥検出においてオープンソースの LMM である Qwen2.5-VL [3] を LoRA でファインチューニングし、高い検出精度と説明性を実現した研究 [4] などが挙げられます。
しかし、LMM の学習プロセスには、テキスト単体モデル (LLM) とは根本的に異なる計算リソース上の課題が存在します。下図に示すように、一般的な LLM がテキスト入力のみを Tokenizer を介して処理するのに対し、LMM は画像入力を処理するための独立したパイプラインを持っています。具体的には、高解像度画像を特徴量に変換する Vision Encoder(CLIP [5] や SigLIP [6] など)と、その画像特徴量を言語モデルが理解できる形式に変換する Projection 層が追加されます。
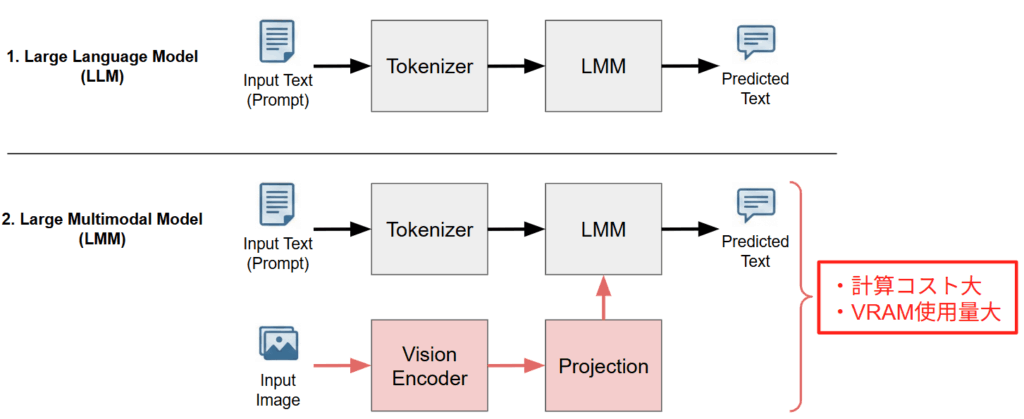
このアーキテクチャの違いにより、LMM の学習は LLM に比べて計算コストが著しく高くなります。数十億パラメータの LLM に加えて Vision Encoder がメモリ上に展開されるため VRAM 使用量が肥大化し、かつ画像処理の計算負荷が上乗せされるため学習時間が長期化します。したがって、巨大な LMM をローカル環境で扱う場合、省メモリ化・高速化といった最適化は、もはやオプションではなく、学習を成立させるための必須要件となっています。
目的:複雑化した構造に LLM の高速化における定石は通用するのか?
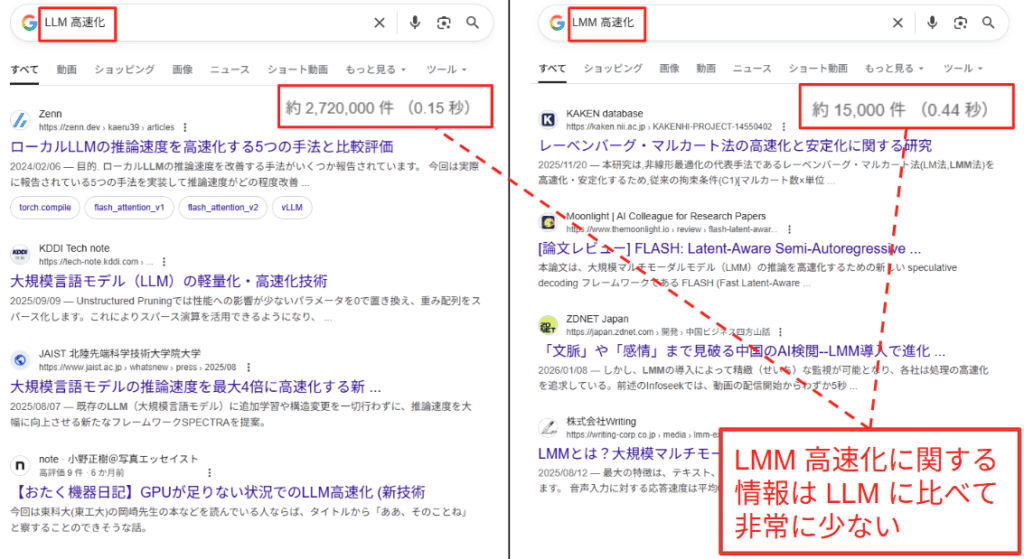
LMM の学習には最適化が不可欠であるにもかかわらず、そのベストプラクティスについてはブラックボックスとなっている部分が大きいです。LLM では、量子化や torch.compile [7] といった高速化手法が標準化されつつあります。しかし、LMM は Vision Encoder という追加のモジュールを内包しており、データフローやメモリアクセスのパターンが LLM よりも複雑です。そのため、LLM で劇的な効果を上げた手法が、LMM においても同様に機能するのか、あるいはボトルネックとなってしまうのかが自明ではありません。下図は LLM/LMM 高速化に関する Google 検索の結果画面ですが、LLM に比べて LMM の高速化手法は一般に周知されていないことが分かります。
そこで本記事では、LMM の最適化について、NVIDIA Blackwell アーキテクチャを対象に検証を行います。最新のハードウェア機能を活用する FP8 量子化、ソフトウェアによる最適化である torch.compile、そしてアルゴリズムによる軽量化である QLoRA [8]、これらを順に適用し、LMM 学習における高速化の最適解を探ります。
実験環境
実験には、NVIDIA のモバイルワークステーション向けハイエンド GPU である Blackwell を使用しました。
- ハードウェア: NVIDIA RTX PRO 6000 Blackwell Max-Q Workstation Edition [9]
- モデル: llava-hf/llava-v1.6-mistral-7b-hf (7B パラメータ) [10]
- データセット: beans (Hugging Face Datasets) [11]
- 植物の葉の画像データセットを用い、各画像に対して「Describe(説明せよ)」というプロンプトを与えてラベルを生成させるタスクを想定しました。
- 最大ステップ数: 10 (定常状態の速度を測るため)
- バッチサイズ: 1, 2, 4, 8, 16, 24
ベースライン性能
まず、最適化を何も適用しない標準的な状態(BF16 精度)でのパフォーマンスを測定しました。以降、この数値を基準として各手法を評価します。
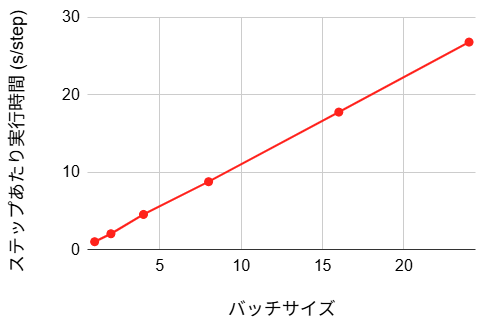
- ステップあたり実行時間:
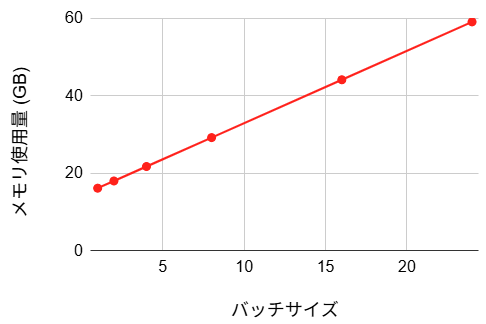
- メモリ使用量:
- 初期ステップ時間:1.48 s
- ステップ 10 における評価損失:9.05
以降のセクションでは、通常の BF16 学習をベースラインとして以下の 4 つのアプローチを比較検証します。
- FP8 量子化の導入:Blackwell で強化された Tensor Core を活用する
torch.compileの導入:ソフトウェアによる一般的な高速化の定石を適用する- シェイプの固定化:動的シェイプを排除し、コンパイラの性能を引き出す
- QLoRA の利用:メモリ効率を最優先した手法との比較
1. FP8 量子化の導入
LLM の高速化手法の一つに、パラメータや計算過程で扱う数値の情報量を減らすことで計算コストの低減とメモリ使用量の削減を図る、量子化があります。本セクションでは、FP8 量子化が LMM の学習性能およびメモリ効率に及ぼす影響を定量的に調査します。なお、Blackwell アーキテクチャでは更に高速な FP4 演算も新たにサポートされています [12] が、学習用途における収束性の確保が難しく、ライブラリのサポートもまだ実験的な段階であることを考慮し、本検証では現在実用段階にある FP8 に焦点を当てます。
FP8 量子化に伴う問題
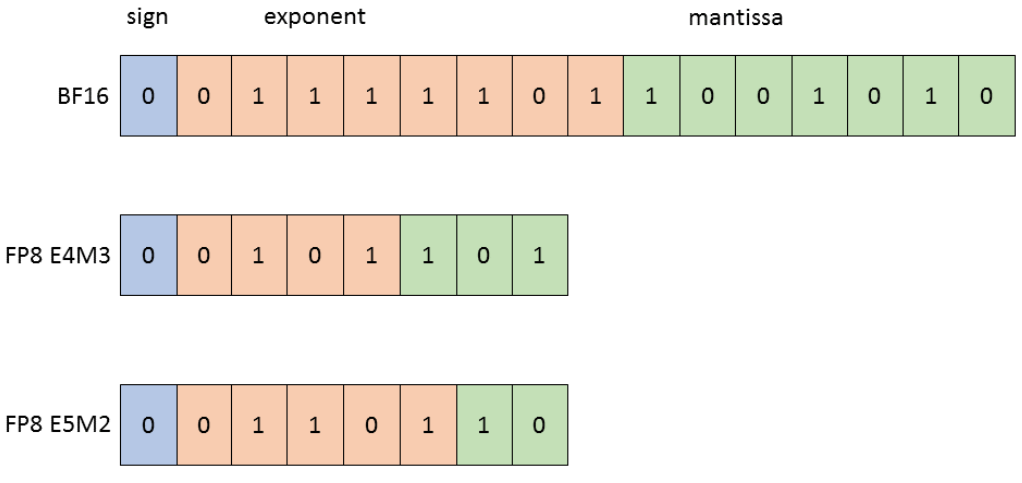
ディープラーニングの標準的な精度である BF16 は 16 ビットで一つの数値を表現しますが、FP8 はその半分の 8 ビットで表現します。数値の表現は符号、指数部、仮数部のビット配分によって定義されます。BF16 は指数部を 8 ビット保持することで広範な数値範囲をカバーします。FP8 にはビット配分に応じて E4M3 と E5M2 と呼ばれる 2 つの数値精度がありますが、どちらも総ビット数が BF16 の半分であるため、表現可能な精度や範囲が物理的に制限されます。この制約の下でデータ量を削減することにより、メモリ帯域の節約と演算スループットの向上が実現します。
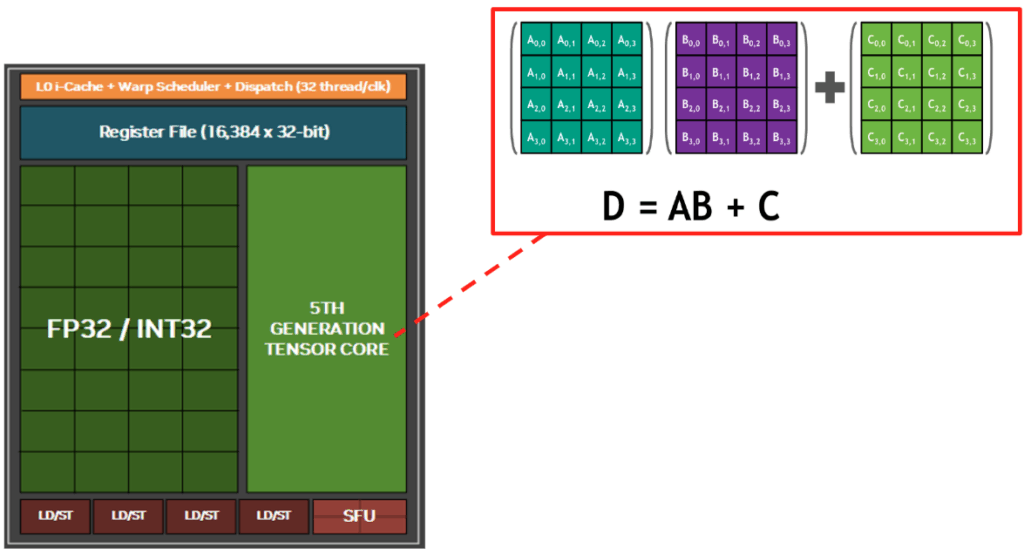
さらに、最新の Blackwell アーキテクチャには、行列演算を物理層で加速する 第 5 世代 Tensor Core [14] が搭載されています。通常の CUDA コアが 1 クロックごとに 1 つの数値計算を順次処理するのに対し、Tensor Core は行列積和演算($D = A \times B + C$) に特化した専用回路であり、1 クロックで $4 \times 4$ などの行列計算を一括して並列処理します。Blackwell の第 5 世代 Tensor Core は FP8 演算をネイティブにサポートしており、BF16 と比較して 2 倍の演算スループット を実現します。これは、データサイズが 16 ビットから 8 ビットに半減したことで、Tensor Core 内部のパイプラインに一度に投入できるデータ量が 2 倍になるためです。単にメモリ容量を節約できるだけでなく、2倍のデータを一度に計算できるハードウェア特性を活かすことができるようになります。
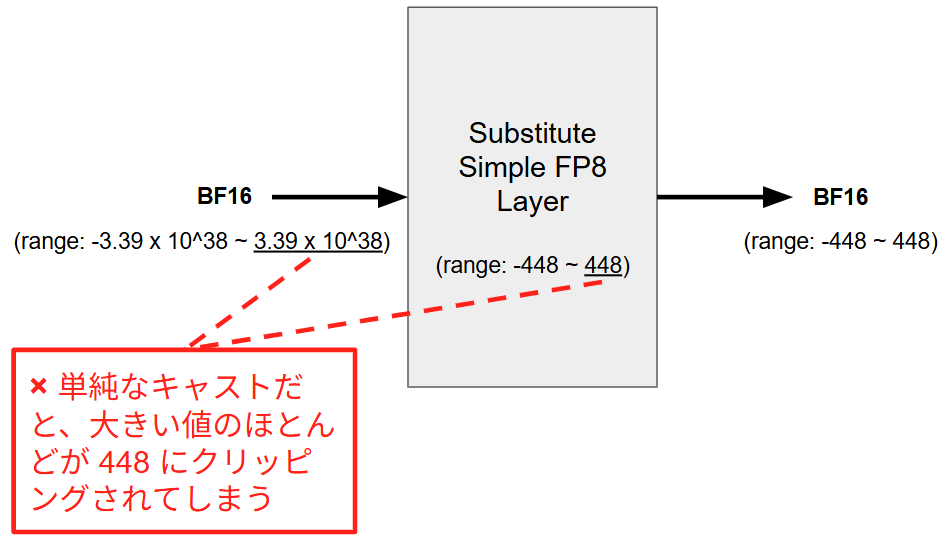
BF16 をベースに構築された学習モデルを FP8 化するためには、精度の低い 8 ビット形式でも学習の安定性を損なわないための数値制御が必要となります。通常、モデル内の各層間では BF16 精度でデータがやり取りされますが、FP8 は BF16 に比べて表現可能な数値の幅が著しく狭いため、そのままの数値を通すとモデルの出力が破綻してしまいます。
まず、オーバーフローの問題について説明します。BF16 での値域はおよそ $-3.39 \times 10^{38} \sim 3.39 \times 10^{38}$ ですが、FP8 (E4M3) の値域はわずか $-448 \sim 448$ です。このため、そのまま BF16 の値を FP8 にキャストしてしまうと、大きな値は 448、小さな値は -448 に張り付いてしまいます。このため、例えば本来 1,000、1,000,000 といった差があった重みがキャストした瞬間に同じ 448 として扱われてしまいます。これではネットワークは特徴の強弱を学習することができません。
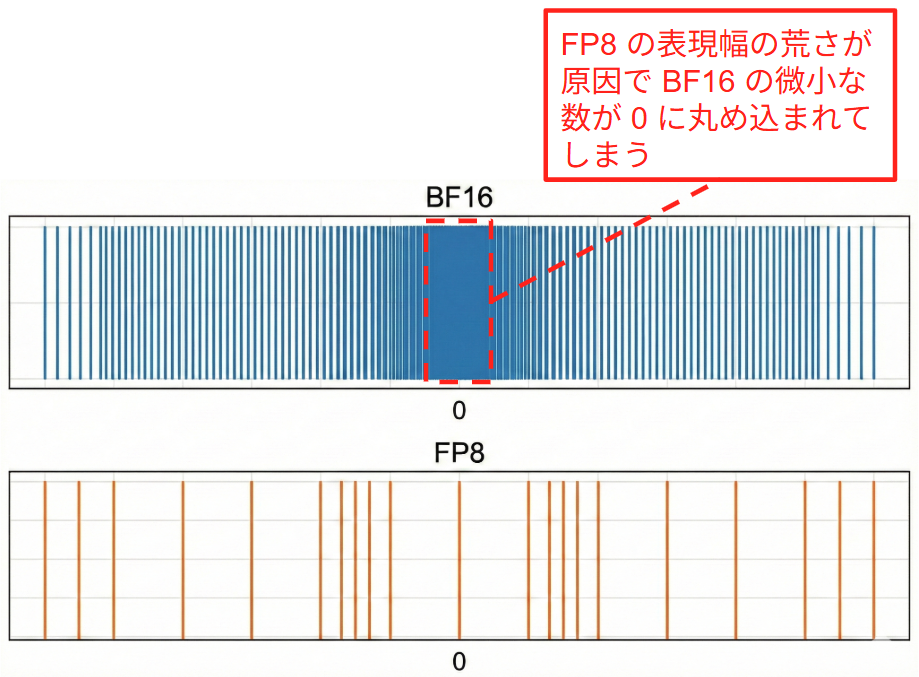
また、微小な数のキャストについてもアンダーフローというもう一つの落とし穴が存在します。FP8 の最小表現幅は BF16 よりもずっと荒いため、BF16 で表現できていた 0.00005 のような重みが FP8 では 0 とみなされてしまいます。学習において重みや勾配の微調整は重要になりますが、そのままキャストするとこれらがすべてゼロとみなされて学習が止まってしまいます。
アプローチ:Transformer Engine によるスケーリング
この課題を解決するために、ビット数を抑えつつも BF16 がサポートする数値範囲をカバーするためのスケーリング処理を行います。これは、数値全体の分布に基づいて適切な範囲に引き伸ばしたり圧縮したりする操作を指します。具体的には、絶対値の最大値 AMAX を追跡し、それに基づいて算出されたスケール因子 S を乗じることで、数値を FP8 の表現可能な領域にマッピングします。
以下の具体例を用いて説明します。ここでは入力となる BF16 テンソルが $-1000 \sim 10000$ の範囲に分布しているケースを想定します。このままキャストすると FP8 の最大値 448 を超えてしまいますが、入力の絶対最大値(AMAX=10000)を用いてスケーリング係数 $S_{INPUT} = \frac{448}{10000} = 0.0448$ を算出します。この係数を乗じることで、入力データは $-44.8 \sim 448$ という FP8 で表現可能な範囲に圧縮されます。FP8 空間で行われた演算結果には、逆変換の係数($1 / (S_{INPUT} \times S_{WEIGHT})$)が乗じられ、最終的な出力は $-70000 \sim 25000$ といった本来の BF16 スケールへと復元されます。これにより、内部計算は高速な FP8 で実行しつつ、モデル全体としては BF16 相当のダイナミックレンジを維持することが可能になります。
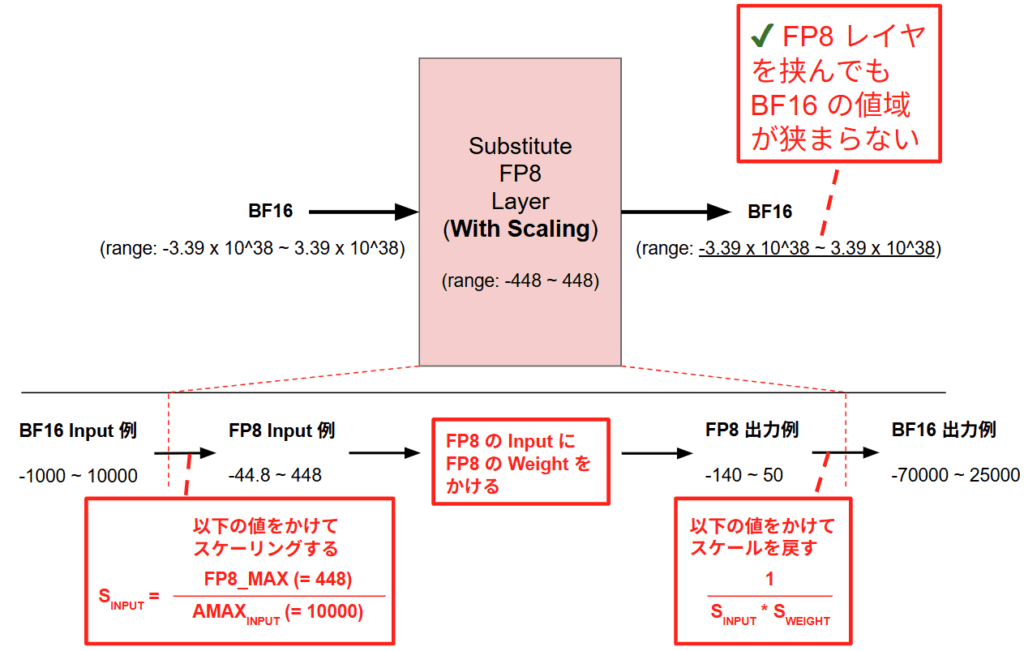
実際の実装においては、PyTorch 標準の nn.Linear ではなく、NVIDIA の Transformer Engine ライブラリ [17] が提供する te.Linear へ置換を行うことで、これらのスケーリング処理を自動的に実行することが可能です。te.Linear は内部でスケーリングと量子化をシームレスに統合しており、ユーザーが明示的に数値のクリッピングや型変換を記述することなく FP8 演算の恩恵を享受できる設計となっています。
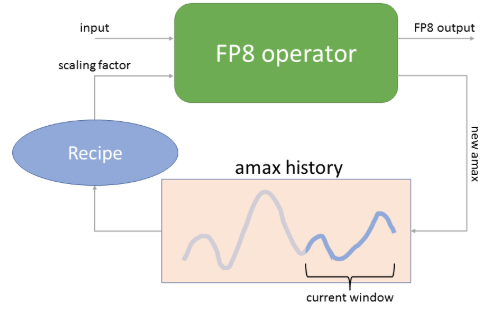
内部処理の核心となるのが動的スケーリング、とりわけ Delayed Scaling と呼ばれる手法です。上図では現在の入力の最大値 10000 を AMAX として採用していますが、現在の入力データの最大値を見てからスケールを決めると、最大値測定と FP8 への変換で2回データを読む必要があり、非効率です。そこで Transformer Engine における te.Linear では、下図に示すように今回の入力の最大値ではなく、過去数ステップの最大値の履歴から推定したスケーリング係数を今回の変換に利用します。この動的なアプローチにより、計算コストの増加を最小限に抑えつつ、学習過程で変動する活性化関数や勾配の数値分布に高い精度で追従することが可能となります。これは、学習中の重みの分布は急激には変化しないという統計的性質を利用したものです。
実装
本実験の実装では、モデル内の全線形層を FP8 へ変換する構成をとっています。具体的には、LLaVA-v1.6 を構成する言語モデルおよび Projector の全モジュールを再帰的に走査し、nn.Linear を te.Linear へ置き換えています。これにより、主要な計算ブロックにおいて FP8 Tensor Core の恩恵を最大限に受けることを意図しています。
PEFT と Transformer Engine の互換性について: 本来、量子化を用いた学習では「ベースモデルを量子化→LoRA アダプタを適用」という順序が一般的です。しかし、現時点での PEFT ライブラリ [18] は Transformer Engine の te.Linear レイヤを LoRA の適用先としてネイティブにサポートしていません。先にモデルを FP8 化してしまうと、PEFT がターゲット層を見つけられずエラーとなります。具体的には、以下のログに示すように PEFT は nn.Linear などの標準的な PyTorch モジュールのみをサポート対象としており、Transformer Engine 独自の te.Linear 型を認識できずに ValueError となります。
ValueError: Target module Linear() is not supported.
Currently, only the following modules are supported: `torch.nn.Linear`, `torch.nn.Embedding`, `torch.nn.Conv1d`, `torch.nn.Conv2d`, `torch.nn.Conv3d`, `transformers.pytorch_utils.Conv1D`, `torch.nn.MultiheadAttention.`.
そこで本実験では、検証のために通常の BF16 モデルに LoRA を適用した後、強制的にベースレイヤを te.Linear に置換するという手法をとりました。これにより、LoRA の構造を維持したまま、バックエンドの演算のみを Blackwell の Tensor Core (FP8) で実行させる構成を擬似的に再現しています。この構成は実運用環境での安定性を保証するものではありませんが、Blackwell アーキテクチャにおける FP8 演算のポテンシャルを測定するベンチマークとしては有効であるためこのような構成としています。呼び出し元を含む具体的な実装コードは以下の通りです。
# 置換関数:nn.Linear を te.Linear へ再帰的に置換
def convert_to_te_layers(module):
for name, child in module.named_children():
if isinstance(child, nn.Linear):
has_bias = child.bias is not None
# FP8 対応の te.Linear への置き換え
te_layer = te.Linear(child.in_features, child.out_features, bias=has_bias)
# 重みデータの移行
te_layer.weight.data = child.weight.data.clone()
te_layer.weight.requires_grad = child.weight.requires_grad
if has_bias:
te_layer.bias.data = child.bias.data.clone()
te_layer.bias.requires_grad = child.bias.requires_grad
setattr(module, name, te_layer)
else:
convert_to_te_layers(child)
convert_to_te_layers(model.language_model)
convert_to_te_layers(model.multi_modal_projector)
結果
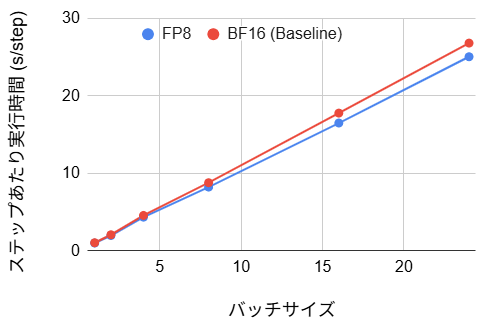
- ステップあたり実行時間:(4~7% の改善)
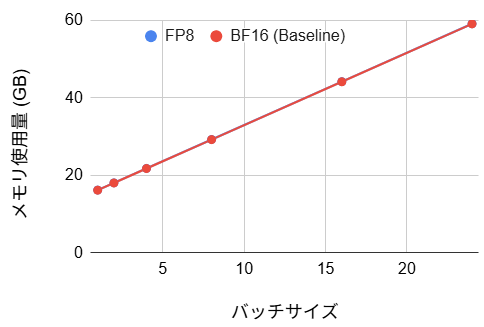
- メモリ使用量:(変化なし)
- 初期ステップ時間:1.41 s (5% の改善)
- ステップ 10 における評価損失:10.36 (14% の悪化)
考察
ステップあたりの実行時間はベースライン比で 4~7% の短縮が確認されました。しかし、期待されたほど劇的な改善に至らなかった背景には、処理の冒頭に位置する Vision Encoder の影響があります。Vision Encoder を FP8 量子化しようとすると、レイヤ構造の技術的制約によりモデルがエラー終了となるため、前述の呼び出し例の通り変換対象からは除外(BF16 のまま維持)しています。この Vision Encoder 部分の計算時間が短縮されていないことに加え、FP8 化変換プロセスのオーバーヘッドが重なったことが、速度向上の幅を限定的にしたと考えられます。また、バッチサイズと実行時間の関係を見ると、バッチサイズが大きくなるほど FP8 の優位性が増しています。これは高負荷になるほど処理が演算律速へとシフトし、Blackwell の Tensor Core が持つ高いスループット性能がより効果的に発揮されたためと考えられます。FP8 の表現力制約により評価損失は 14% 悪化しましたが、この精度の低下が許容できるタスクであれば、FP8 量子化は実効速度を向上させるための有用な選択肢となり得ます。なお、今回は検証のために全線形層を FP8 化していますが、精度劣化を抑えるために、感度の高い層(例えば Attention の出力層など)のみ BF16 に戻すといった混合精度(Mixed Precision)のチューニングを行うことで、速度と精度のバランスをさらに改善できる余地があります。
# Vision Encoder を FP8 化した場合に発生するエラー
# - Vision Encoder は 577 トークンを出力する
# - が、FP8 演算カーネルが要求する「入力次元の積が 16 の倍数」という制約に違反してしまう
AssertionError: FP8 execution requires the product of all dimensions except the last to be divisible by 8 and the last dimension to be divisible by 16, but got tensor with dims=[5, 577, 1024]
メモリ使用量については理論上期待される半減効果は見られず、ベースラインとほぼ同等の結果となりました。これには大きく 2 つの要因が推測されます。第一に、新旧の重みが一時的に重複してメモリに確保されている可能性です。今回は LoRA 適用後にレイヤを置換する手法を採用しているため、管理用メタデータや重複領域がメモリを圧迫していると考えられます。第二に、前段で述べた技術的制約により Vision Encoder が FP8 化できていない点です。ここが依然として BF16 レイヤとしてメモリを消費し続けているため、LLM 部分での削減効果が相殺され、結果としてメモリ総量に変化が現れなかったと考えられます。
2. torch.compile の導入
次に、PyTorch 2.0 以降で導入された JIT (Just-In-Time) コンパイル機能である torch.compile の適用を試みます。前回のブログにおける実験 では torch.compile の適用によって約 38% の大幅な性能向上が確認されましたが、今回は LMM に対して、同様の恩恵が得られるかを検証します。
仕組み
torch.compile が学習を高速化する主な原理は、動的な Python コードを元に、演算の流れを表現する Computational Graph を構築し、それに基づいて演算をまとめることにあります。例えば、下図に示すような Conv2d(畳み込み)、BatchNorm(正規化)、ReLU(活性化)という一連の処理を行う def foo(x) 関数を考えます。
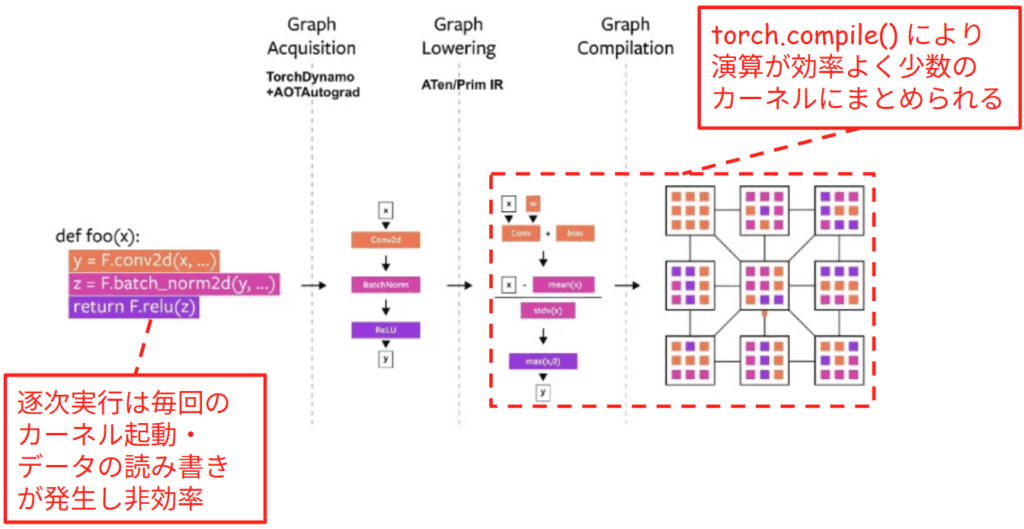
PyTorch の標準的な実行モードである Eager Mode では、Python のコードが 1 行実行されるたびに、それに対応する GPU カーネル が個別に起動されます。GPU カーネルとは、GPU 上で並列実行されるように設計された小さなプログラムの単位です。Eager Mode の場合、これらは独立したバラバラのタスクとして扱われます。まず畳み込みのカーネルを起動して計算結果を VRAM に書き出し、それが完了してから次の正規化のカーネルを起動してデータを読み出す、といった手順を繰り返します。このように演算ごとに細切れに実行される方式は、カーネルを起動する際のオーバーヘッドが生じるだけでなく、中間データの頻繁な読み書きが発生するため、GPU のポテンシャルを最大限に活用できず非効率です。
この非効率な逐次実行を解消するために、torch.compile は実行前にプログラム全体の流れを解析します。図の中央に示されるように、TorchDynamo が Python コードから Computational Graph を抽出します。さらに、BatchNorm のような複雑な演算を、より基本的な計算単位へと分解・正規化します。これにより、コンパイラは計算の細部までを把握し、最適化の余地を見つけ出せるようになります。解析された計算の流れに基づき、複数の演算を一つにまとめます。図の右端にあるグリッドは、統合されたカーネルを表しています。内部に橙・桃・紫の 3 色が詰まっているのは、本来別々だった「畳み込み」「正規化」「活性化」の工程が、一つのカーネルに統合されたことを示しています。これにより、GPU は一度のカーネル起動で一連の計算を一気に処理できるようになります。中間データを VRAM に書き戻す必要がなくなるため、データ移動の無駄を排除した極めて効率的な実行が可能となります。
実装
実装においては、モデルの定義後、学習ループに入る前にモデル全体をコンパイル対象として指定します。オプションとしては、最も汎用的な default モードを使用しました。
# モデル定義
model = LlavaNextForConditionalGeneration.from_pretrained(...)
# ... (LoRA や FP8 レイヤの適用) ...
# モデル全体をコンパイル対象としてラップする
model = torch.compile(model, mode="default")
結果
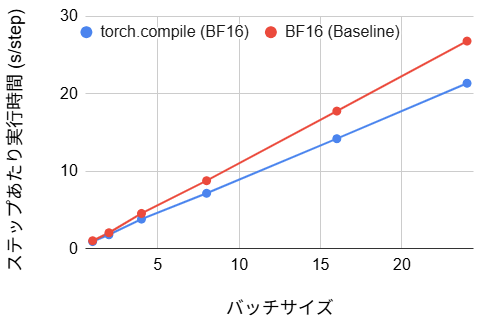
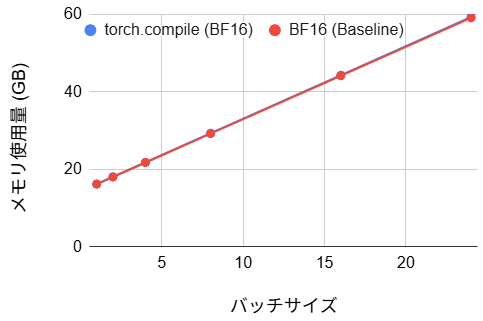
【BF16 バージョン】
- ステップあたり実行時間:(11~20% の改善)
- メモリ使用量:(変化なし)
- 初期ステップ時間:105 s (71 倍の悪化)
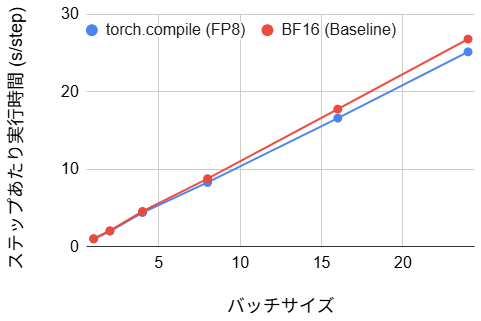
【FP8 バージョン】
- ステップあたり実行時間:(2~6% の改善)
- メモリ使用量:(変化なし)
- 初期ステップ時間:61 s (41 倍の悪化)
考察
1. コンパイル効率と Graph Break の影響
ステップあたりの実行時間を見ると、BF16 版では 11~20% の高速化が見られましたが、Stable Diffusion における前回ブログの実験で観測されたような大幅な性能向上には至りませんでした。また、学習開始時のコンパイル時間として 61~105 秒もの待ち時間が発生しており、数ステップ程度の小規模な実験やデバッグ用途では、このオーバーヘッドが高速化の恩恵を相殺してしまいます。いずれにせよ、マルチモーダル学習において、安易なコンパイルは効果が薄いことが分かりました。バッチサイズ1の場合の損益分岐点(コンパイル時間の元が取れる回数)を計算すると約 950 ステップとなり、小規模な実験では導入するメリットが薄いです。加えて、ステップあたりの実行時間では、BF16 版と比較して FP8 版では torch.compile による高速化の恩恵が小さくなっています。これは、BF16 版ではコンパイラが標準レイヤ間のカーネル統合を効果的に行えるのに対し、FP8 版では Transformer Engine のカスタムカーネルが障壁となり、コンパイラによる最適化の適用範囲が限定されてしまうためと考えられます。なお、全体として高速化効果が薄い根本的な原因については後に詳述します。
興味深い点として、FP8 版の方が BF16 版よりも初期コンパイル時間が短い(105秒 → 61秒)という現象が確認されました。これは、Transformer Engine の te.Linear レイヤが torch.compile から見て解析不可能なブラックボックスとして扱われていることに起因すると推測されます。te.Linear が Graph Break を引き起こし、コンパイラが最適化の対象とする Computational Graph の範囲が分断され、グラフの規模が縮小したためにコンパイル時間が短縮されたと考えられます。その反面、モデル全体を統合した最適化の余地も失われたため、実行時間の改善幅も 2~6% に留まったと考えられます。
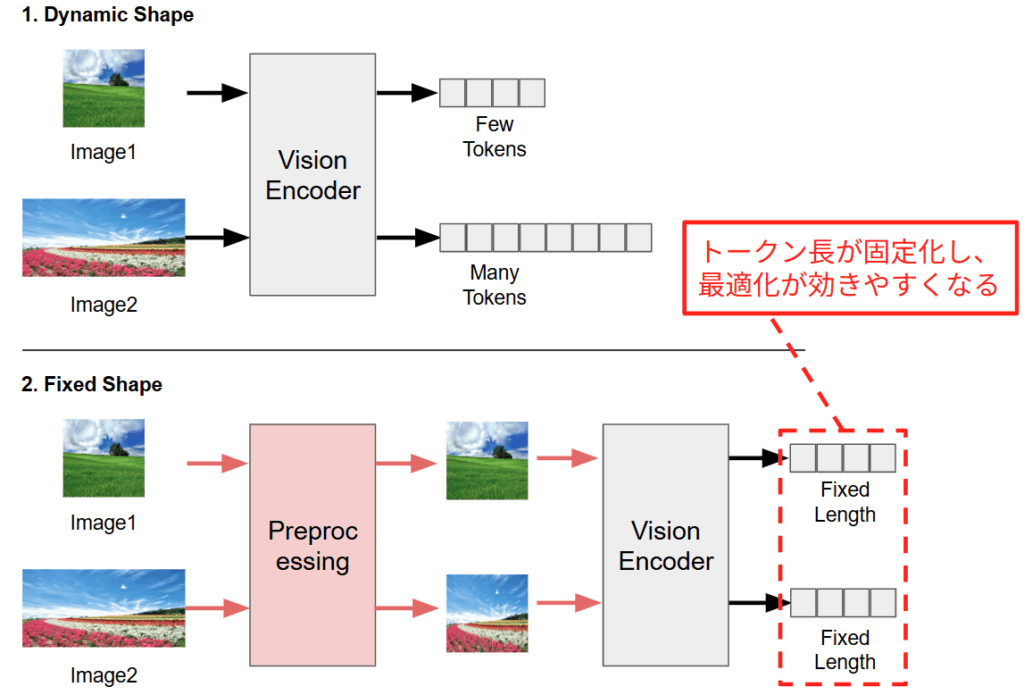
2. 構造的ボトルネック:AnyRes 機構と可変トークン長
torch.compile の効果が限定的であった最大の要因は、LLaVA-NeXT が採用している AnyRes 機構 [20] による可変長のトークンにあることがわかりました。近年の高性能な LMM は、画像の解像度やアスペクト比に応じて、トークン長を動的に変化させる仕組みを持っています。下図に示すように、解像度の低い画像が入力された場合、Vision Encoder は少数のトークンのみを出力します。一方で、高解像度画像が入力された場合は、詳細を捉えるために大量のトークンが生成されます。使用する画像に応じてトークン長が変化してしまうと、コンパイラはステップごとにこのシェイプ用のカーネルは存在するかということをチェックし、存在しなければ新たなカーネルを生成する再コンパイルを実行してしまうために余計なオーバーヘッドが追加されてしまいます。
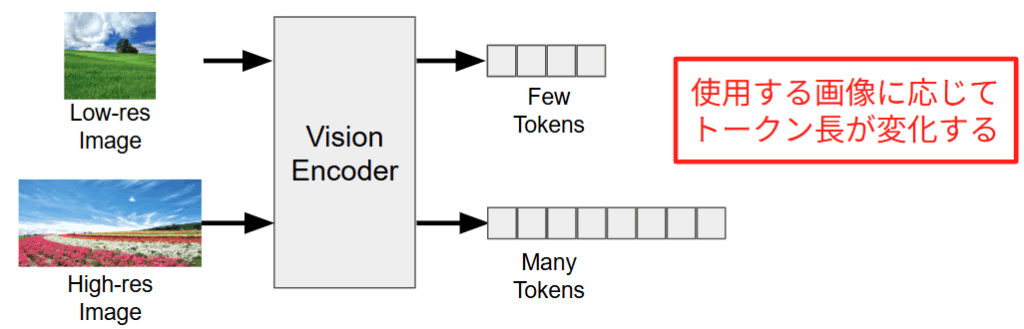
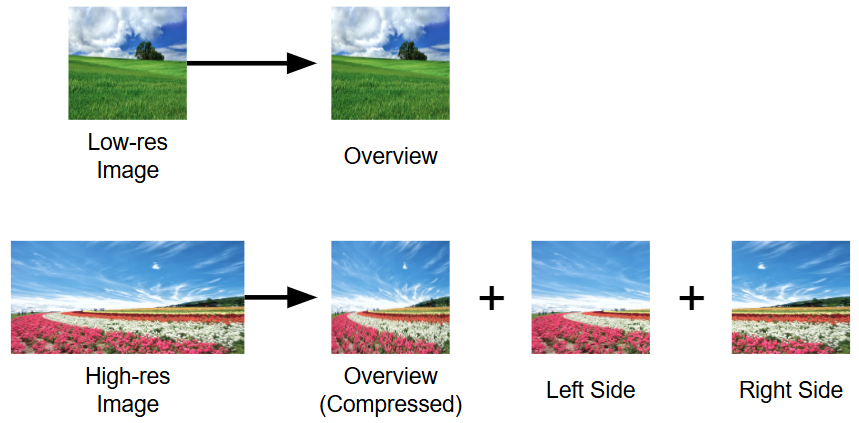
このようなトークン長の変動が生まれる背景には、画像の情報を可能な限り損失なくモデルに伝えるための工夫があります。従来のモデルでは画像を強制的に正方形(例: $224 \times 224$)にリサイズすることが多いですが、これではアスペクト比の崩れや解像度低下により、文字認識や細部の認識精度が著しく低下してしまいます。この問題を解決するため、最新の LMM では下図のように入力画像を動的に分割してエンコードする手法を採用しています。
- 低解像度画像の場合:画像全体を 1 枚のパッチとして処理するため、トークン数は最小限で済みます。
- 高解像度画像の場合:画像全体を縮小した「Overview」に加え、高解像度のまま分割した「Left Side」、「Right Side」などのパッチを個別にエンコードします。
画像を無理に圧縮せず、元の解像度を維持したまま複数のパッチとして扱うことで、画像内の細かな文字情報やテクスチャのディテールを損なうことなくモデルに伝達できます。これにより、文字認識や微細な物体の検出といったタスクにおいて、圧縮に起因する認識精度の低下を根本から回避することができます。一方でこの処理により、例えば $1:1$ の画像と $1:2$ の画像では、Vision Encoder が処理するパッチの枚数が物理的に変化し、結果として LLM に入力されるトークン総数が数倍の規模で変動することになります。
3. シェイプの固定化
アプローチ
前セクションの分析から、LMM における動的シェイプ対応が最適化の足かせになっていることが明らかになりました。たしかに動的シェイプは微細な文字や詳細を読み取るには不可欠ですが、全てのタスクで必須というわけではありません。例えば、大まかな物体の分類や、風景のキャプション生成など、画像の全体的なコンテキストさえ掴めれば十分なケースも多々あります。
そこで、本セクションでは「あえて LMM を固定長モデルとして扱う」 ことで、torch.compile のポテンシャルを最大限に引き出し、どれほどの高速化が得られるかを検証します。具体的には、前処理段階で全ての画像を強制的に固定サイズ(例: 336×336)にリサイズし、テキスト長も固定長パディングを行います。これにより、モデルに入力される Tensor のシェイプを完全固定にします。これにより、torch.compile はトークン長が不変であるという前提で、極限まで最適化されたカーネルを生成できるようになります。
実装
実装における変更点は、データ前処理に集約されます。AnyRes の複雑なパッチ分割処理をバイパスし、単純なリサイズとパディングを適用します。
# 1. 画像の強制リサイズ (AnyRes の無効化)
fixed_resolution = (336, 336)
resize_transform = transforms.Compose([
transforms.Resize(fixed_resolution),
transforms.ToTensor(),
...
])
# 2. テキストの固定長パディング
if fixed_shape:
enc = processor(
text=prompt,
images=image,
return_tensors="pt",
padding="max_length",
max_length=2048,
truncation=True
)
結果
【BF16 バージョン】
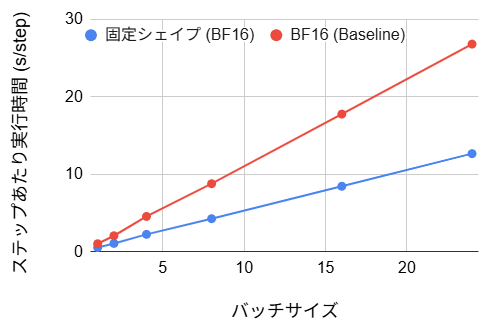
- ステップあたり実行時間:(47~53% の改善)
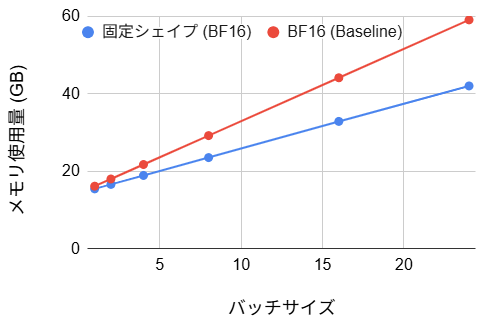
- メモリ使用量:(4~29% の改善)
- 初期ステップ時間:106 s (71 倍の悪化)
- ステップ10 における評価損失:9.23 (2% の悪化)
【FP8 バージョン】
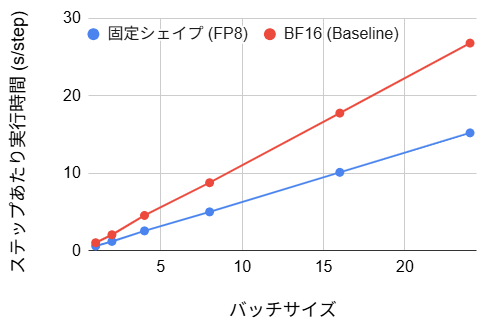
- ステップあたり実行時間:(40~43% の改善)
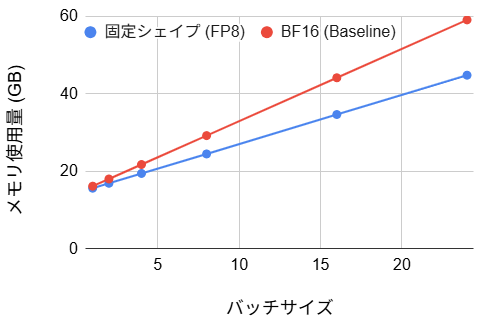
- メモリ使用量:(4~24% の改善)
- 初期ステップ時間:57 s (39 倍の悪化)
- ステップ10 における評価損失:10.51 (16% の悪化)
考察
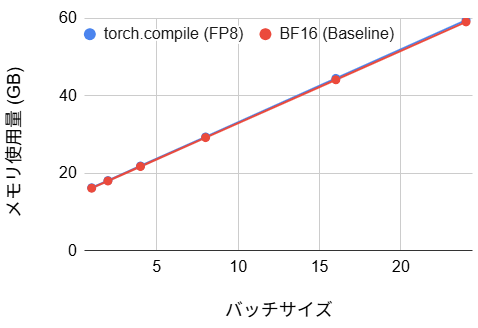
ステップあたりの実行時間は、ベースラインと比較して約 50% 程度の削減を達成しました。これは動的シェイプという制約が外れたことで、コンパイラが本来の最適化能力を発揮し、カーネルの統合が効率的に行われた結果と言えます。BF16 の場合、初期コンパイルに 106 秒のオーバーヘッドが発生しますが、バッチサイズ1の場合の損益分岐点は約 220 ステップです。実用的な学習は通常数千ステップ以上に及ぶため、初期の待ち時間を投資する価値は十分にあるといえます。FP8 ではさらに初期ステップ時間が短くなり、損益分岐点は約 135 ステップとなるため、ステップ数が 135~220 の場合には FP8 が有用と言えます。
また、メモリ使用量に関しては最大で約 29% の削減が達成されました。従来の FP8 化や torch.compile 単体では有意な変化が見られなかったのに対し、サイズ固定化はメモリ効率を大幅に改善しました。この主要因は、AnyRes 無効化に伴う入力トークン数の削減による、Activation 時のメモリ圧縮にあります。学習プロセスにおいて、GPU メモリはモデルの重みパラメータだけでなく、逆伝播計算のために一時保存される各層の演算結果によっても消費されます。この Activation のメモリ量はバッチサイズおよびトークン長に比例して増大するため、トークン数の削減は直接的なメモリ節約につながります。特に、バッチサイズを大きく設定するほどメモリ総量に占める Activation の割合が支配的となるため、トークン長短縮による削減効果がより顕著に観測されたと考えられます。
一方で、この手法は画像を強制的にリサイズするため、アスペクト比の変更による画像の歪みや解像度低下による情報の損失は避けられません。実際、ステップ 10 時点の評価損失は 2〜16% 増大しており、特に FP8 版では「解像度低下」と「粗い量子化」の複合要因により劣化が顕著となりました。解像度を上げれば損失は抑えられますが、その分計算コストが増大し高速化のメリットが相殺されてしまいます。したがって、シェイプ固定化は、監視カメラや製造ラインの検査といった、入力画像の画角やアスペクト比が一定であるドメインにおいて、歪みを最小限に抑えつつ高速化を享受できる有効な選択肢と言えます。
4. QLoRA の利用
最後に、比較対象としてローカル LLM 学習のデファクトスタンダードである QLoRA を検証します。これは、事前学習済みの重みを 4-bit (NF4形式) で固定し、学習対象の LoRA アダプタのみを高精度で計算する手法です。今回は bitsandbytes ライブラリ [21] を用いて、メモリ効率を最優先した構成でのパフォーマンスを測定しました。
実装
実装における変更点は、モデルロード時の量子化設定の注入です。具体的には BitsAndBytesConfig を定義し、load_in_4bit=True とすることで、モデルの重みを 4-bit Normal Float (NF4) 形式で VRAM に展開します。計算自体は BF16 で行う設定にしています。
# QLoRA 用の設定
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4"
)
# モデルロード時に設定を渡す
model = LlavaNextForConditionalGeneration.from_pretrained(
MODEL_ID,
torch_dtype=torch.bfloat16,
quantization_config=quantization_config,
# ...
)
# 量子化モデルの学習準備
model = prepare_model_for_kbit_training(model)
# LoRA アダプタの適用
peft_config = LoraConfig(...)
model = get_peft_model(model, peft_config)
結果
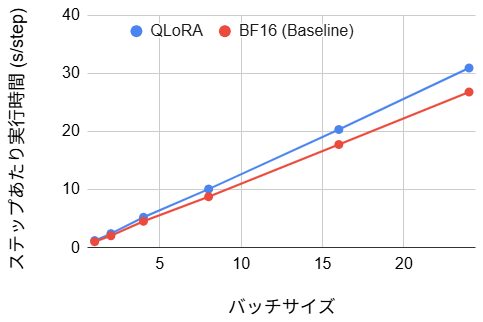
- ステップあたり実行時間:(15~19% の悪化)
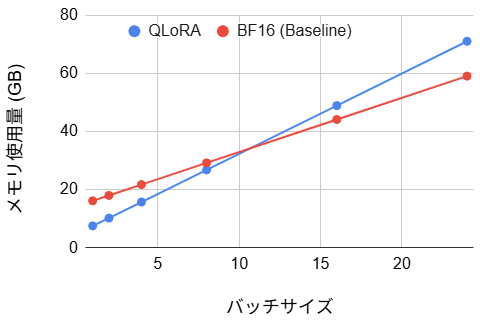
- メモリ使用量:(バッチサイズ1で53% の改善、バッチサイズ24で20% の悪化)
- 初期ステップ時間:1.69 s (14% の悪化)
- ステップ10 における評価損失: 8.88 (2% の改善)
考察
実行速度に関しては、全バッチサイズ領域においてベースラインよりも約15から19%の低下が見られました。これはQLoRAの構造的特性によるものです。QLoRAはメモリ削減を主目的としており、計算時には4ビット形式からBF16形式への解凍処理が都度発生します。Blackwellのような演算性能が高いGPUでは、この解凍に伴うオーバーヘッドが隠蔽できず、純粋なBF16演算と比較してスループットが低下しました。
メモリ使用量については、バッチサイズ1の時点では重み圧縮効果により7.54GBまで抑制され、ベースラインの半分以下の数値を記録しました。しかしながらバッチサイズを拡大するにつれて増加勾配が急峻になり、バッチサイズ24においては逆にベースラインを上回る逆転現象が観測されました。この要因としては、QLoRA特有のメモリ消費構造が影響していると推測されます。QLoRAは重みを4ビット化することで静的なメモリ消費を抑えますが、学習中に発生する中間活性化データは圧縮されず、バッチサイズに比例して増大します。バッチサイズが増大しメモリ消費の主たる要因が重みから中間活性化へと移行する局面において、重み圧縮による節約効果よりも活性化データの増加が支配的となった結果、メモリ効率の悪化が生じたと考えられます。
特筆すべき点として、評価損失が8.88と、BF16 (9.05)やFP8 (10.36)よりも良好な値を記録しました。通常、量子化は情報を落とすため精度は下がりますが、今回は学習データ数が少ない(Beansデータセット)ため、4ビット化による表現力の制約が一種のノイズとして働き、過学習を抑制する正則化のような効果をもたらした可能性があります。あるいは、NF4というデータ形式が重みの分布を効率的に捉えていたとも考えられます。
QLoRA は本記事で紹介した他の最適化手法と併用が難しいという課題があります。
- torch.compile: bitsandbytes の提供する Linear レイヤ(
bnb.nn.Linear4bit)は、カスタム CUDA カーネルで実装されています。これは PyTorch コンパイラから見てブラックボックスであり、グラフの分断を引き起こします。そのため、カーネル統合による高速化の恩恵を受けることができません。 - シェイプを固定: シェイプを固定しても、上記のデクオンタイズ処理がボトルネックとして残るため、静的グラフ化による速度向上は限定的です。
VRAM が逼迫している環境では QLoRA が唯一無二の選択肢ですが、Blackwell のようなハイエンド GPU 環境において学習速度を追求する場合、QLoRA はボトルネックとなり得ます。リソースに余裕があるならば、BF16 または FP8 を選択し、torch.compile やシェイプ固定化と組み合わせる方が、スループットと拡張性の観点で有利と言えます。
結論:マルチモーダル学習における最適化の指針
目的別の LMM 最適化方針
以上の実験から得られた LMM 最適化の指針を以下のチャートにまとめます。
- VRAM が足りない(かつバッチサイズが小さい)場合
- そもそも実行できないという状況を回避するために、QLoRA の利用が推奨されます。ただし、トレードオフとして実行時間がやや増大します。バッチサイズが大きい場合、QLoRA では逆に使用メモリ量が増大する可能性があるので注意が必要です。
- 学習を高速化したい場合
- 2-1. 学習ステップ数が多い場合
- 固定シェイプ +
torch.compile( + 場合に応じて FP8 量子化を併用)が推奨されます。固定シェイプ化は高速化効果が大きいですが、推論性能とのトレードオフとなります。本手法を用いる場合、初期コンパイル時間をカバーするだけのステップ数が必要になります。
- 固定シェイプ +
- 2-2. 学習ステップ数が少ない場合
- FP8 量子化が推奨されます。
torch.compileは初期コンパイル時間が大幅に増大するため推奨されません。
- FP8 量子化が推奨されます。
| 手法 | ステップあたり実行時間 (s/step) | 初期ステップ時間 (s) | メモリ使用量 (GB) | 評価損失 | 特記事項 |
|---|---|---|---|---|---|
| BF16 (ベースライン) | – | 1.48 | – | 9.05 | – |
| FP8 量子化 | 4~7% の改善 | 1.41 | 変化なし | 10.36 | 実行時間が削減されるが, 精度は劣化 |
torch.compile あり (BF16/FP8) | 2~20% の改善 | 105/61 | 変化なし | – (※) | 実行時間は改善するが、コンパイル時間が大幅に増大 |
| サイズ固定化 (BF16/FP8) | 40~53% の改善 | 106/57 | 4~29% の改善 | 9.23 | コンパイル時間は長いが、ステップ時間を大幅に削減可能 |
| QLoRA | 15~19% の悪化 | 1.69 | バッチサイズ1で53% の改善、バッチサイズ24で20% の悪化 | 8.88 | 小バッチサイズでは使用メモリは大幅に削減されるが、実行時間が増加 |
(※:ロギングのフックがグラフ最適化の影響で正しく機能しなかったため, 欠損としています)
LMM 学習における更なる高速化の可能性
以上が現状における最適化の指針となりますが、本検証では同時に、LMM 学習高速化を阻む真のボトルネックが GPU 性能そのものではなく、ソフトウェア側の課題にあることも定量的に特定できました。現状のスタックでは Blackwell の性能を完全には活かしきれませんでしたが、この分析結果は、今後のライブラリの進化によって飛躍的な効率化が期待できることを示唆しています。例えばメモリ面では、現在の実装だと変換前の BF16 モデルと FP8 モデル両方の重みを保持してしまっており約 16GB の VRAM を消費していますが、将来的に PEFT が FP8 をネイティブにサポートし重みを重複なくロードすることが可能になれば、メモリ使用量は QLoRA と同等の水準にまで劇的に削減されるはずです。また速度面においても、現在は te.Linear がブラックボックスとなりコンパイラの Computational Graph を分断してしまう課題がありますが、これが解消され、かつ入力サイズ $N$ が変動してもカーネルを再生成せずに $N$ を引数として受け取れる汎用カーネルを生成する機能がサポートされれば、AnyRes の柔軟性を維持したまま、今回シェイプ固定化で記録された高速化が実現できると推測されます。ハードウェアの進化と並行してこれらソフトウェアスタックが最適化し、Blackwell のポテンシャルが完全に解放される日が来ることを楽しみにしています。
まとめ・感想
本記事では、NVIDIA Blackwell アーキテクチャ上での LMM (LLaVA-NeXT) 学習を題材に、様々な最適化手法の効果と課題を体系的に検証しました。特に、テキスト単体モデルとは異なる LMM 特有の動的シェイプ構造が torch.compile によるカーネル最適化を阻害するメカニズムを解明し、シェイプ固定化というトレードオフを伴う改善策が大きな高速化を実現することを実証しました。加えて、最新の FP8 量子化や QLoRA といった多様なアプローチについても速度・メモリ効率・損失の大きさといった面から比較検証を行い、それぞれの特性に応じたマルチモーダル学習における現実的な高速化の指針を提示できたと考えています。本記事で得られた知見が、複雑化する LMM 学習環境におけるパフォーマンスチューニングの一助となり、皆様のプロジェクトにおける最適解の探索に貢献できれば幸いです。
今回の作業の感想ですが、これまで取り組んできたテキスト単体の LLM 高速化と比較して、LMM の最適化はよりチャレンジングな課題だったと思います。特に torch.compile が期待通りに機能しない原因を特定し改善策を講じるプロセスでは、カーネル統合の内部挙動、LMM 特有の動的シェイプ機構、そして GPU プロファイリングによるボトルネック特定といった多角的な知識を総動員する必要があり、一筋縄ではいかない難しさがありました。しかし、その高いハードルを乗り越える試行錯誤を通じて、PyTorch や GPU アーキテクチャ、そして LMM の内部構造に対する理解を深めることができました。今後もブラックボックスな挙動に直面した際は、安易な対処に走るのではなく、事象を丁寧に分析し、メカニズムへの深い理解に基づいた上で適切な最適化を施すという姿勢を大切にしていきたいと思います。
最後に、本記事の執筆ならびに作業を進めるにあたってご指導いただいたメンターの二木さんにこの場を借りて心より感謝申し上げます。
Fixstars では、通年でインターンシップを募集しています。高専生、大学生、大学院生の皆さん、Fixstars で新しい技術に触れませんか? インターンシップの詳細は こちら をご覧ください。
参考
[2] https://github.com/LLaVA-VL/LLaVA-NeXT
[3] https://huggingface.co/Qwen/Qwen2.5-VL-7B-Instruct
[5] https://arxiv.org/pdf/2103.00020
[6] https://arxiv.org/pdf/2303.15343
[7] https://docs.pytorch.org/docs/stable/generated/torch.compile.html
[8] https://arxiv.org/pdf/2305.14314
[9] https://www.nvidia.com/ja-jp/products/workstations/professional-desktop-gpus/rtx-pro-6000-max-q/
[10] https://huggingface.co/llava-hf/llava-v1.6-mistral-7b-hf
[11] https://huggingface.co/datasets/AI-Lab-Makerere/beans
[13] https://docs.nvidia.com/deeplearning/transformer-engine/user-guide/examples/fp8_primer.html
[14] https://www.nvidia.com/ja-jp/data-center/tensor-cores/
[16] https://www.nvidia.com/content/apac/gtc/ja/pdf/2017/1041.pdf
[17] https://docs.nvidia.com/deeplearning/transformer-engine/user-guide/index.html
[18] https://huggingface.co/docs/peft/index
[19] https://pytorch.org/get-started/pytorch-2-x/#technology-overview
[20] https://llava-vl.github.io/blog/2024-01-30-llava-next/
[21] https://github.com/bitsandbytes-foundation/bitsandbytes

Tags
About Author
daiki.wakabayashi
Leave a Comment
Tags
Favorite Post

 2023年1月27日
2023年1月27日 2017年8月22日
2017年8月22日
Archives
- 2026年2月
- 2026年1月
- 2025年12月
- 2025年11月
- 2025年8月
- 2025年5月
- 2025年4月
- 2024年11月
- 2024年10月
- 2024年7月
- 2024年5月
- 2024年4月
- 2024年2月
- 2024年1月
- 2023年12月
- 2023年6月
- 2023年5月
- 2023年4月
- 2023年2月
- 2023年1月
- 2022年12月
- 2022年10月
- 2021年11月
- 2021年9月
- 2021年6月
- 2021年3月
- 2021年2月
- 2020年12月
- 2020年10月
- 2020年7月
- 2020年6月
- 2020年5月
- 2020年4月
- 2020年3月
- 2020年2月
- 2020年1月
- 2019年12月
- 2019年11月
- 2019年10月
- 2019年9月
- 2019年8月
- 2019年6月
- 2019年4月
- 2019年3月
- 2019年2月
- 2019年1月
- 2018年12月
- 2018年11月
- 2018年10月
- 2018年8月
- 2018年6月
- 2018年5月
- 2018年4月
- 2018年3月
- 2018年2月
- 2017年12月
- 2017年11月
- 2017年10月
- 2017年9月
- 2017年8月
- 2017年7月
- 2017年6月
- 2017年5月
- 2017年3月
- 2016年12月
- 2016年11月
- 2016年8月
- 2016年7月
- 2016年3月
- 2016年2月
- 2016年1月
- 2015年12月
- 2015年11月
- 2015年10月
- 2015年8月
- 2015年6月
- 2015年3月
- 2015年2月
- 2015年1月
- 2014年12月
- 2014年11月
keisuke.kimura in Livox Mid-360をROS1/ROS2で動かしてみた
Sorry for the delay in replying. I have done SLAM (FAST_LIO) with Livox MID360, but for various reasons I have not be...
Miya in ウエハースケールエンジン向けSimulated Annealingを複数タイルによる並列化で実装しました
作成されたプロファイラがとても良さそうです :) ぜひ詳細を書いていただきたいです!...
Deivaprakash in Livox Mid-360をROS1/ROS2で動かしてみた
Hey guys myself deiva from India currently i am working in this Livox MID360 and eager to knwo whether you have done the...
岩崎システム設計 岩崎 満 in Alveo U50で10G Ethernetを試してみる
仕事の都合で、検索を行い、御社サイトにたどりつきました。 内容は大変参考になりま�...
Prabuddhi Wariyapperuma in Livox Mid-360をROS1/ROS2で動かしてみた
This issue was sorted....