このブログは、株式会社フィックスターズのエンジニアが、あらゆるテーマについて自由に書いているブログです。
NVIDIA Blackwell における Multi-Process Service (MPS) を用いた GPU 利用効率の改善
はじめに
Fixstars でアルバイトをしている若林大起です。
前回の記事では、最新の NVIDIA Blackwell アーキテクチャ上での LoRA ファインチューニングにおいて、PyTorch Profiler を駆使してカーネル発行のボトルネックを特定し、単一 AI タスクの学習速度を高速化する手法を紹介しました。しかし、GPU リソースの活用という観点では、「1つのタスクを速くする」ことだけが正解ではありません。特に推論サーバや多数の実験を回す MLOps 基盤においては、「いかに多くのタスクを同時にさばくか(スループット)」がコスト対効果を決定づけます。今回は、このようなスループット向上のための NVIDIA GPU の機能である Multi-Process Service (MPS) に焦点を当てます。GPU 利用率が表示上 100% に達していても内部の演算器(SM)が十分に使われていない場合があるという問題点を指摘したのちに、Blackwell 世代の最新 GPU において MPS を用いることでどれほどの性能向上をもたらすのかということを、特性の異なる4種類のワークロードを用いて検証します。本記事では、その検証プロセスと得られた知見、予期せぬボトルネックによる性能劣化、そして予備実験におけるモニタリングの苦労についても共有します。
[追記・訂正 (2026/01/13)] DCGM Exporter の DCP モジュールについて「Tesla, A100, H100 といったデータセンタ向け GPU でのみサポート」と記述しておりましたが、より正確な条件である「Volta アーキテクチャ以降の データセンタ向け GPU でのみサポート」という記述に訂正いたしました。ご指摘いただきありがとうございました。
背景:AI プラットフォーム開発における GPU リソース活用
GPU の需要増加とコストのジレンマ
近年の AI 需要の爆発的な増加に伴い、GPU リソースのコスト最適化は大きな課題となっています。市場調査によれば、データセンタ向け GPU 市場は 2024 年から 2030 年にかけて数倍の規模へ急成長すると予測されており [1]、NVIDIA のデータセンタ向け GPU 出荷数も年間数百万基規模に達しています [2]。
しかし、ハイエンド GPU サーバの調達コストは、汎用 CPU サーバと比較して桁違いに高額であり、システム全体で数千万円規模の投資が必要となるケースも珍しくありません。特に Blackwell [3] のような最新アーキテクチャは、前世代を遥かに凌ぐ演算性能とメモリ帯域を持っています。極めて高コストなリソースであるからこそ、その巨大な計算能力をわずかでも無駄にすることなく、限界まで使い切ることが求められています。
活用のための2つのアプローチ
このような GPU リソースを限界まで利用する手段には、大きく分けて2つのアプローチがあります。
- 単一タスクの高速化
- 1つ1つのタスクを早く終わらせることで、単位時間あたりの処理数を増やします。前回の記事で取り上げた
torch.compileやnum_workersの調整による最適化はこのアプローチに該当します。
- 1つ1つのタスクを早く終わらせることで、単位時間あたりの処理数を増やします。前回の記事で取り上げた
- 複数プロセスの集約
- 複数のタスク(推論リクエストや小規模な学習タスク)を並行して実行し、GPU を常に稼働状態にするのがこのアプローチです。同様の考え方で、クラウド環境などでも複数の仮想マシンを1つの物理マシンに集約することで CPU 利用率を高める手法が採用されています。今回の記事では、この集約をメインに取り上げます。
問題点:GPU 利用率 100% でも SM が空く — 時分割制御の限界
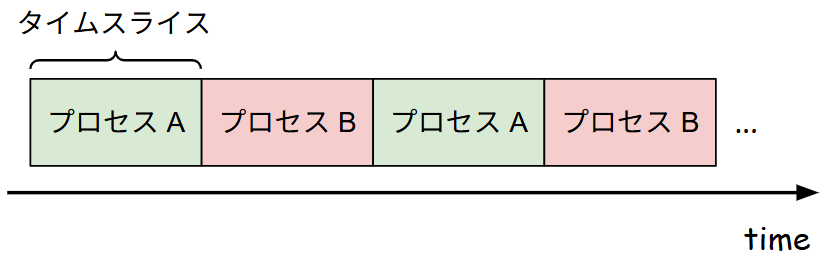
GPU のデフォルト挙動:時分割
通常、1つの GPU に複数のプロセスを投入すると、GPU ドライバは 時分割でこれらを制御します。OS が CPU コアを複数のプロセスで切り替えて使うのと同様に、GPU も短い時間単位で実行権をプロセス A、プロセス B、と切り替えます。あるプロセスが実行されている間、他のプロセスは待機状態となり、このコンテキストスイッチを高速に行うことで、見かけ上の同時実行を実現しています。予めプロセスを多く集約しておくことで、1つのプロセスの実行が終了しても他のプロセスが実行され、CPU/GPU の利用率を高い状態に保つことができます。
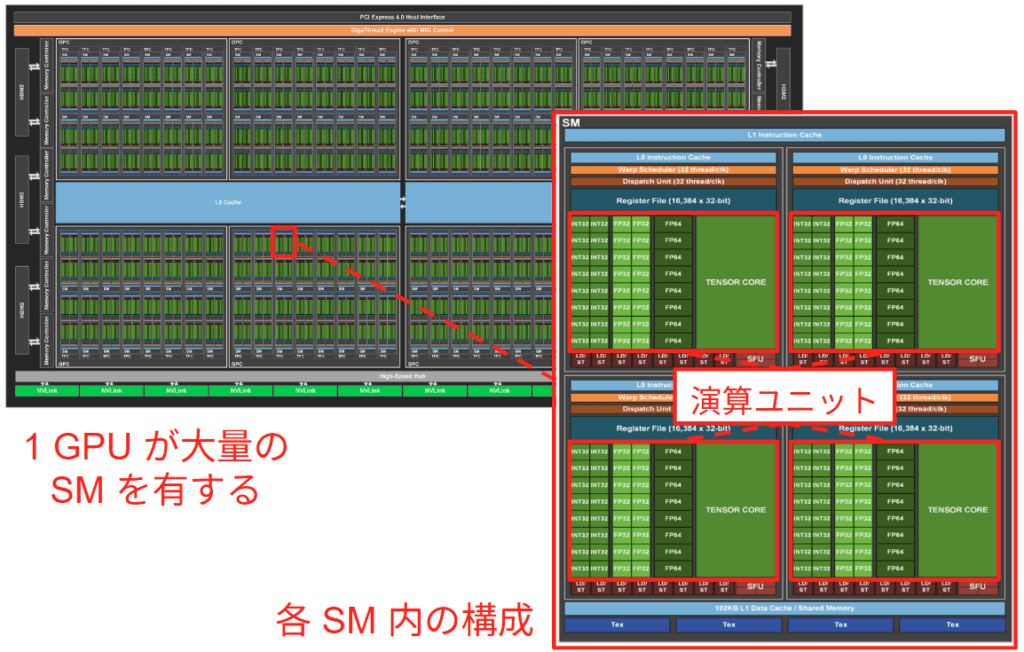
この方式の構造的な問題点を指摘する前に、CPU と GPU の設計思想の違いについて説明します。CPU は少数の強力なコアを持ち、複雑な分岐予測や大きなキャッシュを用いて、単一スレッドの処理速度を最大化するように設計されています。対して GPU は、スループットを最大化するために、より単純なコアを大量に並列配置する設計をとっています。この「コアの集合体」の単位が Streaming Multiprocessor (SM) [4] です。例えば GA100 GPU はシステム全体で 128 個の SM を擁する巨大なプロセッサとなっています [5]。 SM 内部には、浮動小数点演算を行う CUDA コア、行列演算に特化した Tensor コア、命令発行を行う Warp スケジューラ、そしてレジスタファイルや共有メモリといったリソースが集約されています。こちらの図は Ampere 世代のものですが、基本的な概念は Blackwell でも同様です。
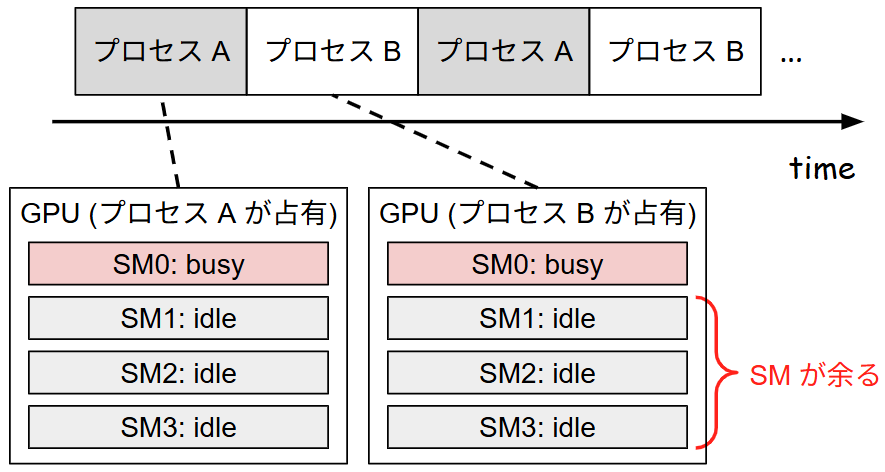
標準的な時分割制御では GPU 全体が単一のプロセスによって排他的に占有されますが、これが計算資源の余剰を生む原因になります。推論タスクやバッチサイズの小さい学習など、比較的軽量なワークロードでは、計算に必要なリソースが GPU 全体の能力に比べて著しく小さい場合があります。例えば、ある推論プロセスが計算のために 20 個の SM しか必要としない場合でも、時分割制御下ではそのプロセスが実行権を持っている間、残りの 100 個以上の SM は他のプロセスの計算を行うことができず、アイドル状態となってしまいます。
予備実験:GPU の「見かけの飽和」と「実質の余剰」
目的
前節で紹介した GPU の時分割制御は計算資源の利用率低下につながりますが、実際の実行環境下では看過されてしまうことも少なくありません。この問題点を指摘するために、時分割制御下において多数のプロセスが実行されている際の GPU における計算資源の利用状況を調べてみます。実験環境は以下の通りであり、BERT [6] 学習タスク 24 プロセスを 1GPU に集約します。
実行環境
- CPU: Intel(R) Xeon(R) w5-2455X 24 core (Hyper-Threading enabled)
- GPU: NVIDIA RTX PRO 6000 Blackwell Max-Q Workstation Edition
- OS: Ubuntu 22.04
- Kernel: Linux 6.8.0
- Docker 28.3.3
- PyTorch: 2.8.0
まず、GPU をモニタリングする際に一般的に用いられる nvitop [7] コマンドで稼働状況を確認してみます(その他, nvidia-smi コマンドなどでも同様の挙動となります)。下図に示す通り、GPU 利用率は 100% を示しており、限界まで GPU を利用しているように見えます。
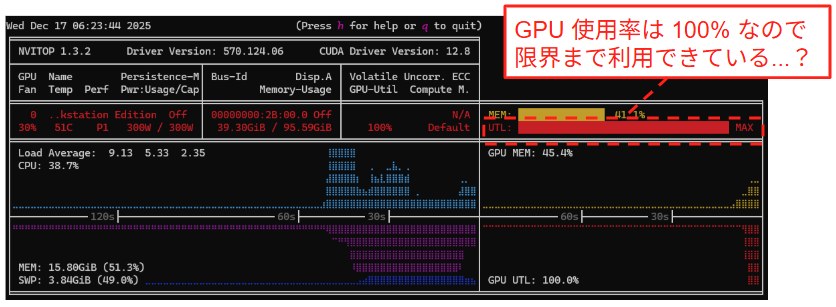
しかし、ここで重要なのが、このような CLI ツールで示されている GPU Utilization は一般に GPU の「時間的な」利用率を指すということです。この GPU Utilization が具体的に何を指しているのかを確認するため、nvitop の Git リポジトリ を調査しました。 GPU Utilization の意味については、nvitop/api/device.py 内 1199 行目の gpu_utilization メソッドにおける記述が参考になります。
def gpu_utilization(self) -> int | NaType:
"""Percent of time over the past sample period during which one or more kernels was executing on the GPU.
...
"""
return self.utilization_rates().gpu
このメソッドは内部で utilization_rates() を呼び出していますが、その実装を追うと NVIDIA ドライバの管理インターフェースである NVIDIA Management Library (NVML) [8] の API である nvmlDeviceGetUtilizationRates に到達します。NVML およびドライバの内部実装はオープンソースではないため、これ以上詳細な計測ロジックをソースコードから直接確認することはできませんでした。しかし、上記関数内のコメントとして明記されている通り、この数値は「過去のサンプリング期間において、1つ以上のカーネルが GPU 上で実行されていた時間の割合」を示しているとあります。極端な例を挙げれば、GPU 上の SM のうち、たった1つのコアしか使わない小さなカーネルであっても、それが切れ目なく実行されていれば、定義上この GPU Utilization は 100% となるということです。すなわち、SM 全体が利用されているかどうかという状態はこのメトリクスには反映されません。
このような「空間的な」GPU の利用率を調べるため、プロファイリングツール NVIDIA Nsight Systems (nsys) [9] を用いてモニタリングを行いました。このような GPU の空間的な利用率を確認するための手法は他にも複数存在しますが、それぞれ利用に注意点があるため後のセクションにて紹介させていただきます。nsys では、以下のコマンドを実行することでシステム全体のモニタリング結果が、カレントディレクトリ配下に output.nsys-rep として保存されます。--gpu-metrics-devices を指定することで、GPU から、定期的な間隔で状態を取得する機能を有効にすることができます。
sudo nsys profile --gpu-metrics-devices=all --output=output
GUI を利用できるマシンで NVIDIA Nsight Systems をインストール し、このファイルを開くことで実行中の GPU の詳しい利用状況を確認することができます。nsys における GPU の使用状況は以下の通りです。こちらの図から分かる通り、GPU Active (nvitop における GPU Utilization に相当) の値が 100% となっている一方で、GPU の空間的な利用率を表す SMs Active の値は 40~50% を推移しており、半分以上の SM がアイドル状態になってしまっていることが分かりました。
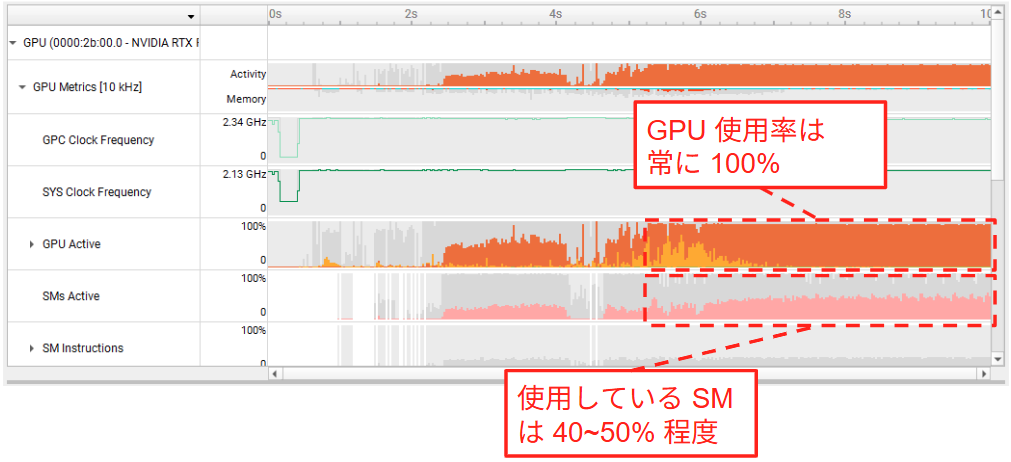
以上の結果より、
- (1) 複数の学習タスクを集約させた場合でも、標準の時分割制御では GPU の SM 全体が利用しきれていないこと
- (2) このような時分割制御における GPU の未活用は、GPU の時間的な利用率が 100% を示すことによって隠蔽されやすくなっていること
が示唆されました。
解決策:Multi-Process Service(MPS)による GPU の空間分割
上記のような集約における GPU の空間利用率を向上させる手法として GPU の分割があります。並列にプロセスを実行しても同時期には1つのスレッドが GPU を占有してしまうという問題点を解決するため、利用できる GPU コアを分割し各プロセスに割り当てることで並列にプロセスを実行可能にするという技術です。

GPU の分割手法
スレッドが GPU を分割して利用する方法には、ハードウェアレベル・ソフトウェアレベルの2つのアプローチがあります。今回の検証の目的は GPU リソースの余剰を極限まで使い切ることであるため、空いている SM を動的に利用できる MPS を採用します。
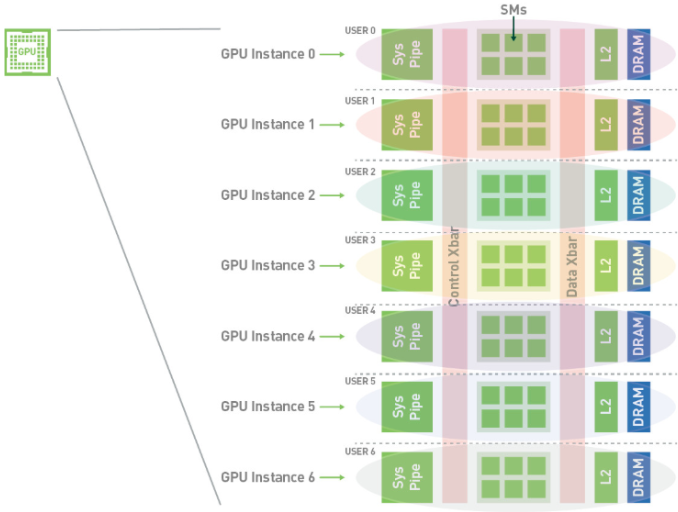
- ハードウェアレベルでの分割:Multi-Instance GPU (MIG) [10]
- SM やメモリ帯域を物理的にパーティション分けし、完全に独立したミニ GPU として動作させます。隔離性が高く Quality of Service (QoS) が保証されますが、分割サイズが固定的であるため、空いているリソースを動的に融通することができません。
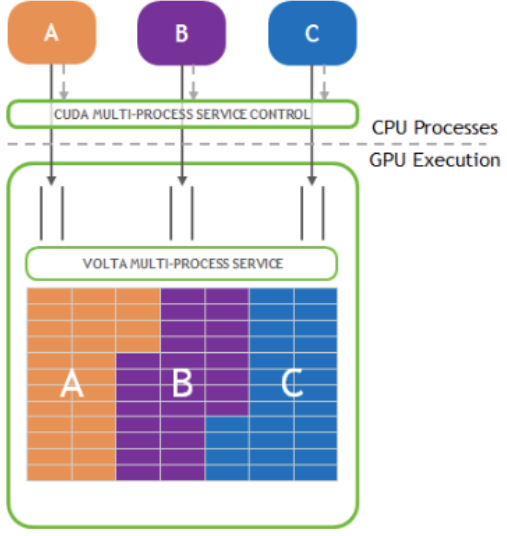
- ソフトウェアレベルでの分割:MPS [11]
- 論理的な空間分割を行い、複数のプロセスで単一の物理 GPU リソースを共有します。隔離性は MIG に劣りますが、リソースの動的な割り当てが可能であり、空いている SM を即座に他のプロセスが利用できるため、全体のスループット最大化に向いています。
MIG と MPS はそれぞれ異なる目的と設計思想を持っています。両者の主な違いを以下の表にまとめました。
| 特徴 | MIG | MPS |
|---|---|---|
| 分割レイヤー | ハードウェアレベル(物理分割) | ソフトウェアレベル(論理分割) |
| リソース割り当て | 固定的(パーティションサイズは事前に決定) | 動的(空いている SM を自動的に融通) |
| メリット | メモリやキャッシュも物理的に分離させるため障害隔離性が高く、他のプロセスの干渉を受けないため QoS が保証される | アイドル状態の SM を即座に他のプロセスが利用できるため、GPU 全体の稼働率とスループットを限界まで最大化できる |
| デメリット | 自区画がアイドル状態でもリソースを他へ融通できないため、GPU 全体での無駄が生じやすく、最大スループットは劣る場合がある | 1つの CUDA コンテキストを共有するため障害が波及するリスクがあり、他プロセスの負荷状況によって性能が変動する可能性がある |
| 主なユースケース | 複数のユーザが混在するクラウド環境など | 信頼できる単一ユーザ下でのバッチ処理や推論サーバ |
MPS の内部実装
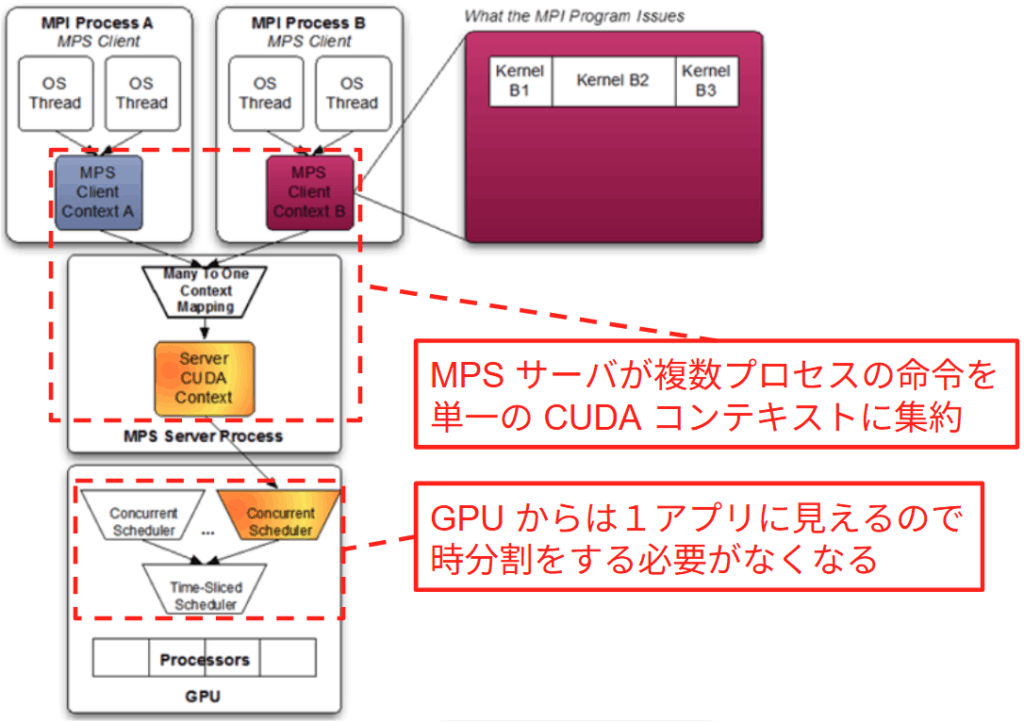
MPS はクライアント・サーバ型のアーキテクチャによる単一 CUDA コンテキストへの集約によって、複数プロセスの並列実行を実現します。常駐プロセスである nvidia-cuda-mps-server が各クライアントからの CUDA 命令を仲介し、それらを単一のコンテキスト内で実行される1つの巨大なアプリケーションとして GPU に提示します。 この仕組みにより、従来のプロセスごとのコンテキストスイッチが排除されるほか、GPU 内部のハードウェアスケジューラが空いている SM リソースに対して各クライアントのカーネルを動的に割り当てることが可能となり、プロセス A は SM 0〜10、プロセス B は SM 11〜20 といった形で、異なるプロセスのカーネルが物理的に同時に計算を行う空間分割が達成されます。
MPS の利用方法
MPS の利用に際して、アプリケーション側のコード変更は不要です。前節でも説明した通り、MPS はクライアント・サーバ型のアーキテクチャをとるため、アプリケーションを実行する前に MPS デーモンを起動するだけで、CUDA API 呼び出しが自動的に仲介されるようになります。基本的な利用手順は以下の3ステップです。
1. MPS デーモンの起動
対象とする GPU を CUDA_VISIBLE_DEVICES で指定し、MPS デーモンをバックグラウンドモード(-d)で起動します。これ以降、この GPU に対する操作は MPS デーモンによって管理されます。
export CUDA_VISIBLE_DEVICES=<使用する GPU の番号>
nvidia-cuda-mps-control -d
2. アプリケーションの実行
通常通りアプリケーションを実行します。複数のプロセスを同時に投入することで、MPS が自動的にカーネルをスケジューリングし、空間分割実行を行います。
python3 train.py --id 1 &
python3 train.py --id 2 &
...
3. MPS デーモンの停止
すべてのタスクが終了したら、制御コマンドに quit を渡してデーモンを停止します。
echo "quit" | nvidia-cuda-mps-control
実験:MPS による性能改善効果の検証
MPS は強力ですが、どのようなワークロードでも効果があるわけではありません。そこで、特性の異なる4つのワークロードを用意し、MPS の有効性と限界を調査しました。実験のセットアップは予備実験と同様です。ワークロードには以下の4種類を選定しました。ディスク I/O やデータ転送によるボトルネックを排除し、純粋な GPU スケジューリング性能を評価するため、torch.randn 等を用いてメモリ上でランダムな入力データを生成する合成データを採用しました。
実験条件
- 比較対象
- MPS なし (時分割) vs MPS あり (空間分割)
- ワークロード (学習タスク)
- 並列プロセス数
- 1, 4, 8, 24, 48
実験結果および考察
(1) MNIST
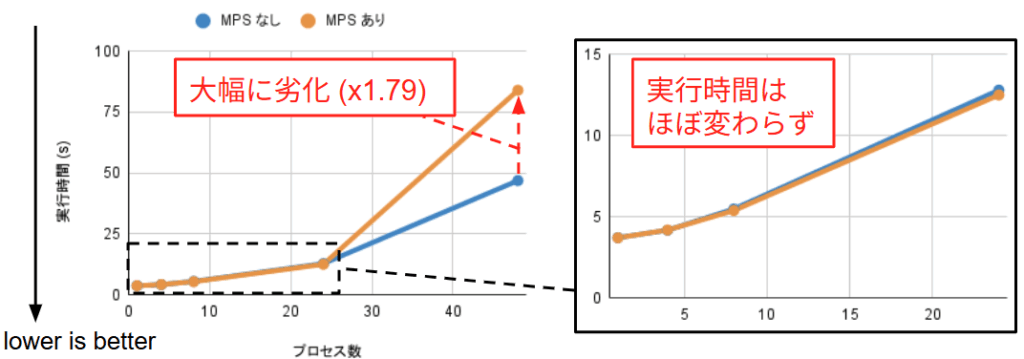
24 プロセス実行時においても実行時間が 2% 程度しか変わらなかった要因として、MNIST 学習ワークロードの特性が挙げられます。このタスクは計算負荷が極めて軽量であり、実行時間の支配的要因は GPU 上での演算処理ではなく、CPU 側でのカーネル発行オーバーヘッドやデータ転送レイテンシにあります。MPS はあくまで SM のアイドル時間を埋めることでスループットを高める技術であるため、そもそも GPU 演算性能がボトルネックとなっていない本ケースでは、空間分割による恩恵が得られなかったと考えられます。
一方、特筆すべき点として、24プロセスに比べ48プロセス並列実行時において4倍以上という大幅な性能劣化を招いた現象が確認されました。当初は MPS デーモン (nvidia-cuda-mps-server) へのリクエスト集中による CPU リソースの飽和を疑いましたが、pidstat による計測では MPS デーモンの CPU 利用率は 1〜5% 程度に留まっており、MPS デーモンの処理能力自体はボトルネックではありませんでした。そこで nvitop を用いてシステム全体のリソース状況を詳細に調査したところ、ホストメモリの枯渇が主因であることが判明しました。
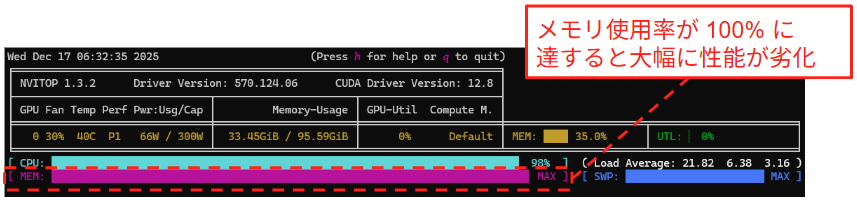
48個の Python プロセスが PyTorch ランタイムやデータセット生成用バッファを一斉に展開したことで物理メモリ容量を圧迫し、OS レベルでの激しいスワップ処理(スラッシング)が発生していることが分かりました。ここで、48 プロセス実行時において MPS ありの場合は MPS なしの場合に比べて実行時間が 1.79 倍程度増大していました。詳しく調査を行ったところ、原因は MPS デーモン自体が利用するメモリ領域のスワップアウトにあることが判明しました。具体的な調査として、以下のコマンドを用いて MPS デーモン(nvidia-cuda-mps-server)のメモリ状態を監視しました。
# MPS デーモンのページフォールトを1秒間隔で監視する
pidstat -r -p $(pgrep -f nvidia-cuda-mps-server) 1
取得されたログの一部が以下です。
08:02:43 AM UID PID minflt/s majflt/s VSZ RSS %MEM Command
...
08:04:25 AM 0 140706 190.00 22.00 13857656 50288 0.15 nvidia-cuda-mps
08:04:26 AM 0 140706 153.00 12.00 13857656 50416 0.15 nvidia-cuda-mps
08:04:27 AM 0 140706 188.00 14.00 13857656 50416 0.15 nvidia-cuda-mps
08:04:28 AM 0 140706 137.00 76.00 13857656 50544 0.15 nvidia-cuda-mps
ここで、1秒当たりの Major Page Fault 回数を表す majflt/s に注目すると、ディスク I/O を伴うページフォールトが継続的に発生しており、ピーク時には秒間 76 回に達していることがわかります。これは MPS デーモンが実行のたびにディスクアクセス待ちで停止していることを意味します。非 MPS 環境では個々のプロセスが独立して GPU ドライバと通信するため、あるプロセスがスワップアウトされても他のプロセスは計算を継続できます。しかし、集中管理型である MPS 環境においては、GPU 制御を一手に担う MPS サーバ自体がスワップアウトの対象となると、サーバがディスクから復帰するまでの間、全てのクライアントプロセスからのリクエストが巻き込まれてブロックされてしまいます。この副作用により、実行時間が致命的に悪化したと考えられます。以上の結果は MPS の導入において、スワップアウトには特に注意が必要であることを示すものとなりました。本番環境においては cgroup などを用いることで、MPS デーモン自体がスワップアウトされないような設定をする必要があるかもしれません。
(2) BERT
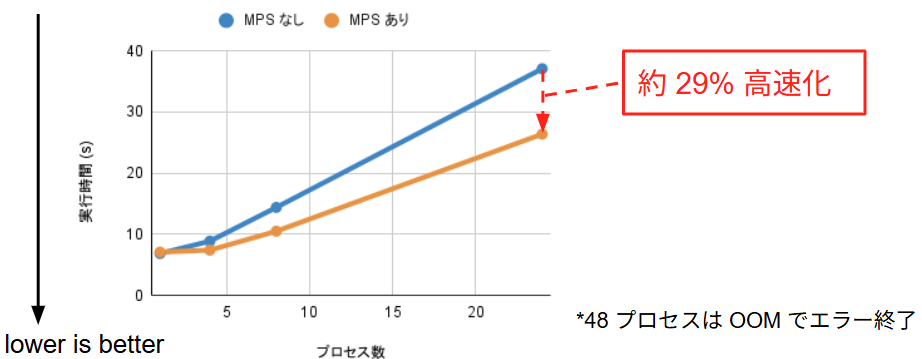
BERT の学習タスクにおいては MPS の導入効果が最も顕著に現れ、24プロセス時で 29% 実行時間が削減されました。BERT のような Transformer モデルは、Attention 機構などの計算において GPU リソースを多用しますが、プロセス単体で見るとメモリアクセス待ちなどによる SM のアイドル時間が頻繁に発生します。MPS はこの隙間を効果的に活用できています。実際に nsys を用いて、24プロセス実行時の SM 稼働状況を可視化した結果が下図です。
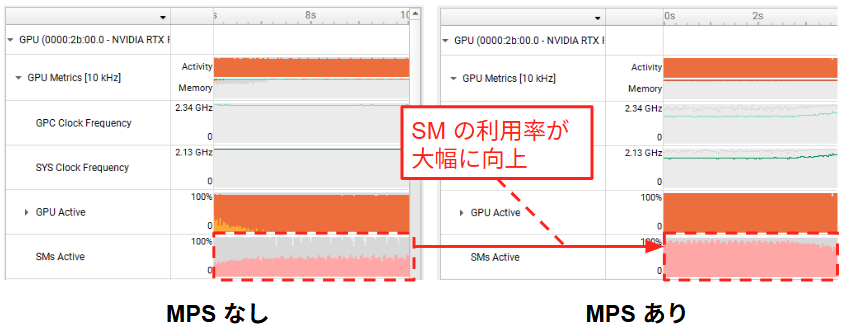
左側の「MPS なし」の場合、時分割制御によるアイドル SM 発生の影響で、SM Active 率は 40~50% 程度になっています。対して右側の「MPS あり」では、複数のコンテキストが単一の CUDA コンテキストに集約された結果、常にいずれかのカーネルが実行されている状態が維持されており、SM Active 率が 90% 程度で平準化されていることが確認できます。以上の結果より、MPS の導入によって GPU の空間利用率を向上させることができることが確認できました。
なお、48プロセス時はホストメモリ枯渇による低速化以前に、VRAM の容量不足により Out of Memory Error が発生し、プロセス自体がクラッシュしました。
(3) ResNet-50
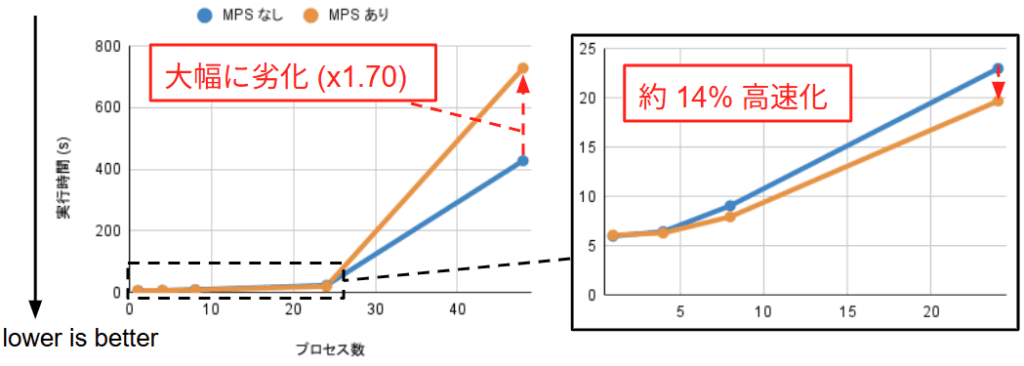
ResNet-50 は、計算負荷とメモリアクセスのバランスが取れた標準的な画像認識モデルです。結果を見ると、プロセス数の増加に伴い MPS の効果が徐々に顕在化しており、24プロセス時には 14% の実行時間削減を達成しました。48プロセス時には MNIST 同様、実行時間が18倍以上増大する大幅な性能劣化が観測されました。特に ResNet-50 は MNIST に比べてモデルサイズおよび入力データサイズが大きいため、メモリ圧迫によるスラッシングによる影響が大きく性能が大幅に劣化したと考えられます。48 プロセスの場合、MPS ありの場合、MPS なしの場合に比べて実行時間が 1.70 倍程度増大しています。これも MNIST の場合と同様に、MPS デーモン自体がスワップアウトされることによるクライアントプロセスのブロックが理由と考えられます。
(4) GEMM
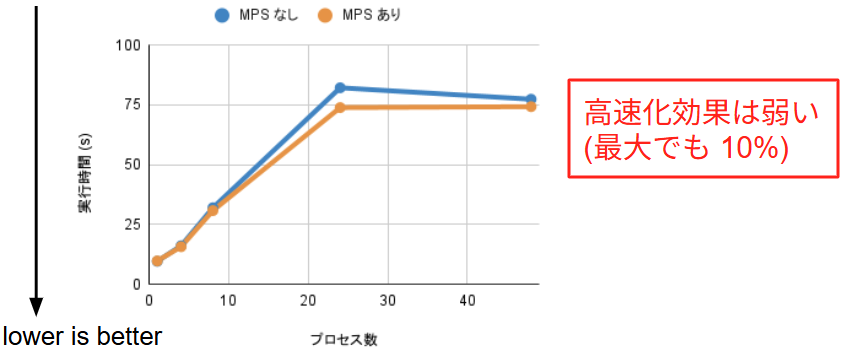
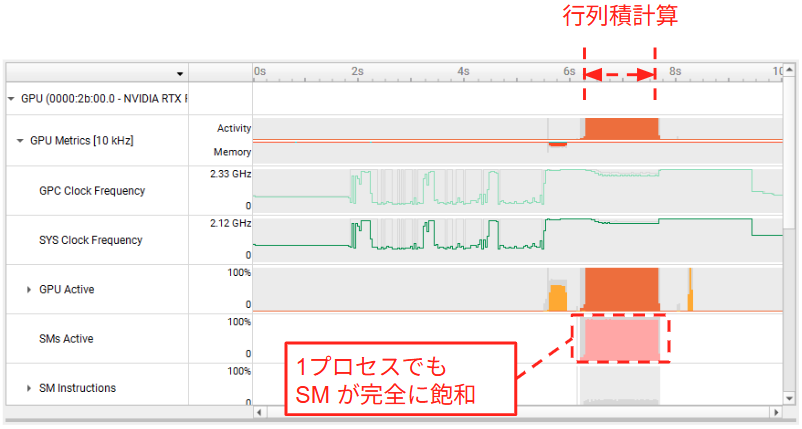
GEMM(行列積)は純粋な Compute Bound なワークロードです。実験結果を見ると、MPS の有無による実行時間の差は最大でも 10% 程度に留まり、他のワークロードのような大幅な改善は見られませんでした。これは、単一プロセスであっても SM が飽和に近い状態まで稼働しているためです。下図は GEMM ワークロードを1プロセス・MPS なしで実行したときの nsys によるプロファイリング結果です。点線部のように、1プロセスの時点で SM がほぼ飽和していることが確認できました。このようにアイドルな SM がほとんど存在しない状況では、スケジューリング方式を時分割から空間分割に変更しても、詰め込む余地がないために性能改善はありません。この結果は、MPS はあくまでアイドルな SM を埋める技術であることを示しています。
結論:MPS が効果を発揮する条件
- 軽量〜中規模モデルの学習:ResNet や BERT のようなモデルで 20%〜40% のスループット向上が確認できました。使用する総メモリ量が物理メモリを超えないことが絶対条件です。集約によってメモリ量が増えすぎると、スラッシングによって大幅に性能が劣化します。特に MPS デーモン自体がスワップアウトされると MPS なしの場合に比べて大幅に性能が劣化してしまうため、
cgroupなどによって MPS サーバがスワップアウトされないように保護するといった対応があると安心です。 - 小~中程度のバッチサイズ:GEMM のようにバッチサイズが大きい場合、1プロセスによって計算リソースが完全に飽和するため、性能は変わりません。
- 並列してプロセスを実行する場合:並列数が少ない場合、空間分割によって得られる恩恵は限定的です。
- GPU 演算がボトルネックになっている場合:CPU による命令発行など別の箇所がボトルネックになっている場合、先にその部分の実行時間を削減する必要があります。
実践ガイド:GPU の空間利用率をモニタリングする方法について
予備実験における GPU の空間利用率のモニタリングには個人的にかなり苦労をしました。NVIDIA Nsight Systems (nsys) 以外にも、(1) DCGM Exporter、(2) Nsight Compute CLI (ncu) によるモニタリングを試したみたので適宜利用する環境に合わせて利用を検討してみてください。
1. DCGM Exporter によるモニタリング
Kubernetes クラスタや Docker 環境において標準的に利用される監視ツールが DCGM Exporter [14] です。こちらは Prometheus [15] および Grafana [16] と組み合わせることで、GPU の状態を時系列データとして長期的に可視化・保存できる点が大きな強みです。
プロファイリング方法
以下の監視スタックを構築しました。
- DCGM Exporter: GPU からメトリクス(利用率、電力、メモリ帯域、温度など)を収集
- Prometheus: Exporter から 10 秒間隔でデータをスクレイピング
- Grafana: データを可視化
以下のように 2 ファイルを配置し、docker compose up -d で起動します。
./
├─ compose.yaml
└─ prometheus.yaml
services:
dcgm-exporter:
image: nvcr.io/nvidia/k8s/dcgm-exporter:4.4.2-4.7.0-ubuntu22.04
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
cap_add:
- SYS_ADMIN
ports:
- "9400:9400"
restart: always
prometheus:
image: prom/prometheus:latest
volumes:
- ./prometheus.yaml:/etc/prometheus/prometheus.yaml
ports:
- "9090:9090"
depends_on:
- dcgm-exporter
restart: always
grafana:
image: grafana/grafana:latest
ports:
- "3000:3000"
depends_on:
- prometheus
restart: always
global:
scrape_interval: 10s
scrape_configs:
- job_name: 'gpu-metrics'
static_configs:
- targets: ['dcgm-exporter:9400']
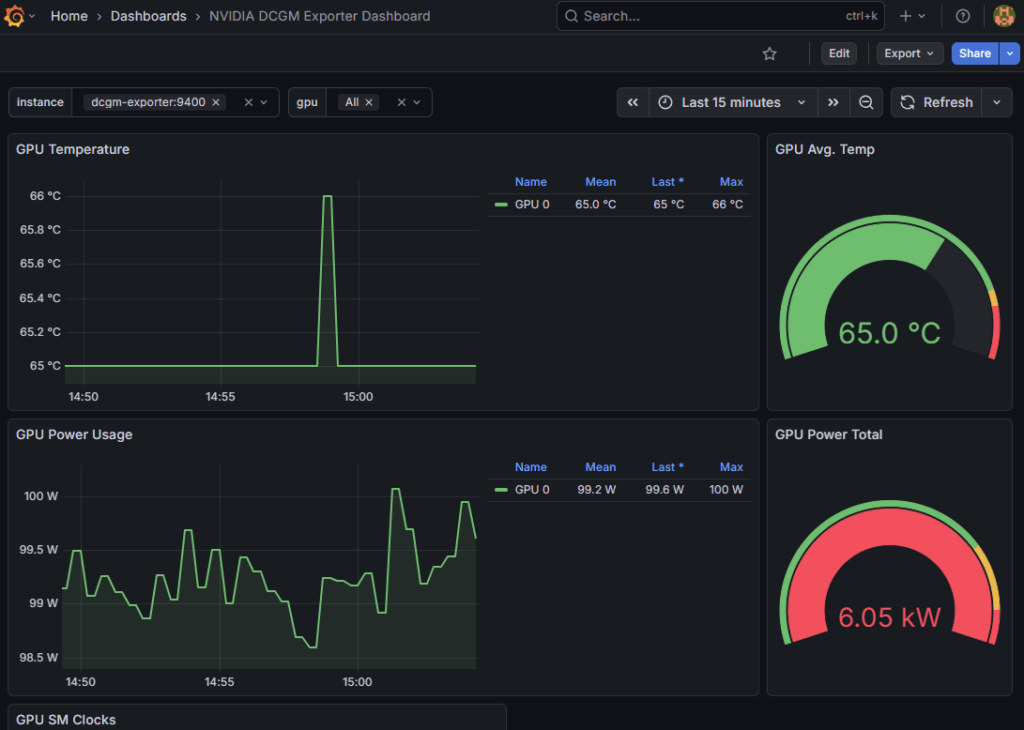
その後、手元のブラウザで http://<サーバの IP アドレス>:3000 を入力し Grafana にアクセスします。user: admin, password: admin でログインできます。その後、Grafana の Data Sources で “Prometheus” を追加し、server URL に http://prometheus:9090 を入力して保存します。緑色で Successfully queried... というメッセージが出れば OK です。その後、Dashboards から、Import を選択し、”Find and import dashboards for common application at grafana.com/dashboards” の欄 NVIDIA 公式ダッシュボード ID である “12239” を入力して Load します。その後、”prometheus” というプルダウンメニューから先程追加したものを選択し、Import することでダッシュボードが表示されます。以下に示すように、基本的なメトリクス(GPU Utilization, Memory Usage, Power Usage, Temperature 等)については、特別な設定なしに取得・可視化することができました。
問題点:RTX シリーズとの相性の悪さ
標準メトリクスは取得できましたが、予備実験で確認を行いたかった空間的な利用率の取得には課題が残りました。設定ファイル(dcgm-metrics.csv)をカスタマイズし、以下の高度なメトリクスの取得を試みました。
- Metric: DCGM_FI_PROF_SM_OCCUPANCY [17]
- 意味: SM 上のアクティブなワープ数の比率
しかし、設定を行ってもこのメトリクスはどうしても取得できませんでした。調査の結果、これらの高度な収集には DCP (Data Center Profiling) モジュールの有効化が必要ですが、DCP は Volta アーキテクチャ以降のデータセンタ向け GPU でのみサポートされており、今回使用している Workstation 向け (RTX シリーズ) では、ハードウェアまたはドライバレベルで機能が制限されていることが判明しました。以下は docker compose logs に出力されたメッセージです。以上の都合から利用を断念することとなりました。
Not collecting DCP metrics: This request is serviced by a module of DCGM that is not currently loaded
2. Nsight Compute CLI (ncu) によるモニタリング
予備実験では NVIDIA Nsight Systems を用いた GUI 上でモニタリングを行いましたが、同様のプロファイリングを CLI 上で行えるのが Nsight Compute CLI (ncu) [18] です。NVIDIA Nsight Systems に比べ、ローカル環境上に GUI アプリケーションを入れずにプロファイリングを行える点が強みです。しかし、DCGM Exporter と同様に今回の実験環境とはうまくマッチしなかったため利用を断念しました。
プロファイリング方法
以下のコマンドを実行することで、アプリケーション実行中における GPU メトリクスを簡単に取得することができます。
sudo ncu <options> <profiling_target>
特に、GPU の空間利用率に関する情報を取得したい場合、--metrics sm__warps_active.avg.pct_of_peak_sustained_active のオプションが有効です。名前が長いですが、以下のように分解すると意味が分かります。すなわち、「理論上の最大同時実行数に対して、実際にどれだけのワープ(スレッドの束)がアクティブだったかの割合」を意味します。このように、リファレンス を参照して様々なメトリクスを柔軟性の高い形で取り出すことができる点が他のプロファイリングツールに比べて便利です。
sm: Streaming Multiprocessorwarps_active: そのSM上に割り当てられ、実行可能な状態にあるワープの数pct_of_peak_sustained_active: その GPU のスペック上の限界値に対するパーセンテージ
問題点:Docker 環境との相性の悪さ
上記の通り CLI 上で高度なメトリクス情報を取得できる ncu コマンドですが、<profiling_target> として直接起動したプロセスしかモニタリングできないという弱点があります。これは特に Docker 環境上で実験用のアプリケーションを実行している場合に不便です。コンテナ管理ツール自体は GPU を一切使用しないため、<profiling_target> として docker compose コマンドを指定しても GPU カーネルが見つからず終了してしまいます。Docker 環境上で ncu を用いたモニタリングを行いたい場合、コンテナの中に ncu をインストールし実行する必要があるためかなり手間がかかります。以上のような都合から、今回の環境では利用を見送りました。
==WARNING== No kernels were profiled.
まとめ・感想
本記事では、NVIDIA Blackwell アーキテクチャにおいて MPS を導入し、そのスループット向上効果を検証しました。結果として、BERT 推論などの中規模タスクでは最大 29% の実行時間削減を達成し、従来の時分割制御ではアイドル状態となっていた SM リソースを、空間分割によって有効活用できることを実証しました。今回の検証を通して特に重要なのが、標準的な時分割制御における「見かけの飽和」の問題です。nvidia-smi などで表示される GPU 利用率(時間利用率)が 100% に張り付いていても、実際には SM の多くがアイドル状態にあるケースが多々確認されました。この隠蔽された余剰リソースこそが最適化の余地であり、MPS はそこにアプローチする強力な手段となります。一方で、プロセス数を極端に増やした実験では、GPU ではなくホストメモリが枯渇し性能劣化を招くという事態にも直面しました。単一のメトリクスだけに惑わされず、SM レベルの実質的な稼働状況といったシステム全体のリソースバランスを俯瞰することが、最新 GPU の性能を限界まで引き出す鍵となります。本記事の知見が、皆様の GPU 基盤最適化の一助となれば幸いです。
今回の作業の感想ですが、時間利用率と空間利用率のギャップという GPU 特有の問題点を検証できた点が特に楽しかったです。「利用率」のような一見分かりやすく見えるメトリクスでも、何を計測してどのように算出しているのかといった視点は今後も忘れないようにしていきたいと思います。また、前回の記事に引き続き様々な GPU モニタリングツールに触れることができた点も貴重な経験となりました。目的に応じて適当なモニタリングを行い必要な情報を取り出すことができるように、これからも様々なツールに触れていきたいと思いました。今回取り上げなかった MIG についても、機会があれば MPS と並べて比較を行い、どのような状況化で MIG/MPS が有用か調査してみたいです。最後に、本記事の執筆ならびに作業を進めるにあたってご指導いただいた二木さんにこの場を借りて心より感謝申し上げます。
最後に、Fixstars では、通年でインターンシップを募集しています。高専生、大学生、大学院生の皆さん、Fixstars で新しい技術に触れませんか? インターンシップの詳細は こちら をご覧ください。
参考
[3] https://www.nvidia.com/ja-jp/data-center/technologies/blackwell-architecture/
[4] https://docs.nvidia.com/cuda/ampere-tuning-guide/index.html
[6] https://arxiv.org/pdf/1810.04805
[7] https://github.com/XuehaiPan/nvitop
[8] https://developer.nvidia.com/management-library-nvml
[9] https://developer.nvidia.com/nsight-systems
[10] https://docs.nvidia.com/datacenter/tesla/mig-user-guide/
[11] https://docs.nvidia.com/deploy/mps/index.html
[12] https://www.tensorflow.org/datasets/catalog/mnist?hl=ja
[13] https://docs.pytorch.org/vision/main/models/generated/torchvision.models.resnet50.html
[14] https://github.com/NVIDIA/dcgm-exporter
[16] https://grafana.com/
[18] https://docs.nvidia.com/nsight-compute/NsightComputeCli/index.html

Tags
About Author
daiki.wakabayashi
Leave a Comment
Tags
Favorite Post

 2023年1月27日
2023年1月27日 2017年8月22日
2017年8月22日
Archives
- 2026年2月
- 2026年1月
- 2025年12月
- 2025年11月
- 2025年8月
- 2025年5月
- 2025年4月
- 2024年11月
- 2024年10月
- 2024年7月
- 2024年5月
- 2024年4月
- 2024年2月
- 2024年1月
- 2023年12月
- 2023年6月
- 2023年5月
- 2023年4月
- 2023年2月
- 2023年1月
- 2022年12月
- 2022年10月
- 2021年11月
- 2021年9月
- 2021年6月
- 2021年3月
- 2021年2月
- 2020年12月
- 2020年10月
- 2020年7月
- 2020年6月
- 2020年5月
- 2020年4月
- 2020年3月
- 2020年2月
- 2020年1月
- 2019年12月
- 2019年11月
- 2019年10月
- 2019年9月
- 2019年8月
- 2019年6月
- 2019年4月
- 2019年3月
- 2019年2月
- 2019年1月
- 2018年12月
- 2018年11月
- 2018年10月
- 2018年8月
- 2018年6月
- 2018年5月
- 2018年4月
- 2018年3月
- 2018年2月
- 2017年12月
- 2017年11月
- 2017年10月
- 2017年9月
- 2017年8月
- 2017年7月
- 2017年6月
- 2017年5月
- 2017年3月
- 2016年12月
- 2016年11月
- 2016年8月
- 2016年7月
- 2016年3月
- 2016年2月
- 2016年1月
- 2015年12月
- 2015年11月
- 2015年10月
- 2015年8月
- 2015年6月
- 2015年3月
- 2015年2月
- 2015年1月
- 2014年12月
- 2014年11月
keisuke.kimura in Livox Mid-360をROS1/ROS2で動かしてみた
Sorry for the delay in replying. I have done SLAM (FAST_LIO) with Livox MID360, but for various reasons I have not be...
Miya in ウエハースケールエンジン向けSimulated Annealingを複数タイルによる並列化で実装しました
作成されたプロファイラがとても良さそうです :) ぜひ詳細を書いていただきたいです!...
Deivaprakash in Livox Mid-360をROS1/ROS2で動かしてみた
Hey guys myself deiva from India currently i am working in this Livox MID360 and eager to knwo whether you have done the...
岩崎システム設計 岩崎 満 in Alveo U50で10G Ethernetを試してみる
仕事の都合で、検索を行い、御社サイトにたどりつきました。 内容は大変参考になりま�...
Prabuddhi Wariyapperuma in Livox Mid-360をROS1/ROS2で動かしてみた
This issue was sorted....