このブログは、株式会社フィックスターズのエンジニアが、あらゆるテーマについて自由に書いているブログです。
NVIDIA RTX PRO 6000 Blackwell Max-Q 上での LLM fine-tuning の実行速度・メモリ効率調査
投稿者より
本記事はインターンシップで勤務された前田 優希さんによる寄稿となります。
最新 GPU の NVIDIA RTX PRO 6000 Blackwell Max-Q を用いて、LLM の fine-tuning にかかる実行速度とメモリ量を調査していただきました。
記事の要約
本記事では、以下のことを示しています。
1. fine-tuning 手法とその速度・メモリ消費の実験的測定について
- 効率的な fine-tuning 手法である LoRA、QLoRA を用いて LLM を fine-tuning する方法を調査した。また、fine-tuning を高速・省メモリで行うことのできるライブラリである unsloth の使い方を調査した。
- NVIDIA RTX PRO 6000 Blackwell Max-Q での LLM の fine-tuning
における実行速度・メモリ効率について実験的に調査した。
- モデルとしては、qwen3-8b、qwen3-32b、gpt-oss-120b を対象とした。
- unsloth により、LoRA での fine-tuning に対して最大 3 倍程度の高速化と 最大 80% 程度の省メモリを実現できた。
- 特に長文シーケンスで unsloth の高速化効果が大きかった。
- QLoRA と unsloth により、gpt-oss-120b の fine-tuning を NVIDIA RTX PRO 6000 Blackwell Max-Q 1 枚を搭載したマシン上で実行できた。
2. NVIDIA RTX PRO 6000 Blackwell Max-Q という GPU の優位性について
- NVIDIA RTX PRO 6000 Blackwell Max-Q と H100 SXM5
について、fine-tuning に要する時間の比較を行った。
- 比較には qwen3-32b と gpt-oss-120b を用いた(qwen3-8b は学習にかかる時間が特に短く、かつ qwen3-32b と同じアーキテクチャであるため比較実験は省略した)。
- qwen3-32b では H100 SXM5 の方が高速であったが、gpt-oss-120b では NVIDIA RTX PRO 6000 Blackwell Max-Q の方が高速であった。
- NVIDIA RTX PRO 6000 Blackwell Max-Q の特徴であるコストパフォーマンスの良さ、メモリの大きさ、電力の低さは、ワークステーションの運用コストを抑えつつ fine-tuning を行う状況に特に適していることを明らかにした。
はじめに
こんにちは。インターン生の前田です。
LLM において、最新の情報や専門知識を踏まえた応答をさせる手法として、fine-tuning や RAG があります。 このうち、fine-tuning の強みとしては、
- RAG のように外部検索を挟む必要がないためレイテンシが短縮される可能性がある
- 知識の注入だけでなく、モデルの出力形式、トーン、および振る舞いをカスタマイズできる
といった点が挙げられます。 一方で、fine-tuning の弱みとしては、
- 学習するために時間を要し、また推論以上のメモリを必要とする
- LLM が最新の知識を持ち続けるためには頻繁に fine-tuning
する必要があり、時間面、電力面でコストがかかる
- 特に fine-tuning を毎日実施するシチュエーションを考えると、1 回の fine-tuning が十分高速に(夜間などの限られた時間内に)終わることが望ましい
という点が挙げられます。 したがって、推論用の GPU で fine-tuning も行いたいというような状況や、ローカル LLM に対して fine-tuning を行うことで最新の知識を反映させたいというような状況を考えると、省時間・省メモリで fine-tuning を行うことが必要不可欠です。 そこで、本記事でははじめに省時間化・省メモリ化に向けた一般的な LLM の fine-tuning の効率化手法を紹介し、具体的に fine-tuning を行う際のコード例を示します。
そのうえで、Fixstars では AIStation において NVIDIA RTX PRO 6000 Blackwell Max-Q(以降 6000 Blackwell Max-Q と略する)という GPU を採用しています(Fixstars AIStationについて)。 これは比較的新しい GPU であり、
- どれくらいのパラメータ数のモデルであれば、6000 Blackwell Max-Q の 1 台上で fine-tuning できるのか
- どれくらいの規模のデータセットであれば、指定された時間内に既存のモデルの fine-tuning が完了するのか
といった事実は自明なものではありません。 そこで、6000 Blackwell Max-Q 上で実際に LLM の fine-tuning を条件を変えながら行い、これらの問いに対する答えを実験的に確認することにします。 最後に、NVIDIA の別アーキテクチャである H100 との比較を通して、6000 Blackwell Max-Q の持つハードウェア的特徴(コストパフォーマンスの良さ、メモリの大きさ、電力の低さ)が LLM というアプリケーションに対してどう発揮されるかを考察します。
前提知識 1:fine-tuning の高速化技術
PEFT とは
一般に、fine-tuning の際にモデルのすべてのパラメータを更新する(full fine-tuning)のには莫大な時間・メモリを必要とします。 特に、モデルのパラメータ数が近年急激に増加している中では、full fine-tuning は現実的な方策とはいえません。
そこで用いられているアプローチが PEFT (Parameter-Efficient Fine-Tuning)です。 PEFT とは、モデルの総パラメータのうち一部のみを学習することで、full fine-tuning と同程度の性能を維持しつつ、計算量を削減する fine-tuning 手法の総称です。 ここでは詳細は割愛しますが、PEFT の中にも様々な手法があり、たとえば huggingface の PEFT ライブラリ [1] でも各種サポートされています。
LoRA とは
LoRA (Low Rank Adaptation) [2] とは、PEFT の一種であり、そのメモリ効率の良さと高いパフォーマンスの維持から広く使われている手法です。
LoRA は、全パラメータを更新するのではなく、重み行列 \(W\) に「低ランク行列の積」である小さなアダプター \(BA\) を追加し、このアダプターだけを学習します(\(W\) の重みは学習中は固定されます)。 fine-tuning 後の重みを \(W’\) とすれば、\(W’\) は \(W’=W+BA\) という式によって表されることになります。 すなわち、fine-tuning により更新される重み行列の差分を、もとの重み \(W\in \mathbb{R}^{d\times k}\) と同じサイズの行列ではなく、低ランク行列 \(A\in \mathbb{R}^{r\times k}\)、\(B\in \mathbb{R}^{d\times r}\) (ただし \(r\ll\min(k,\,d)\) とする)の積により表し、この \(A\)、\(B\) の重みのみを学習するのです。
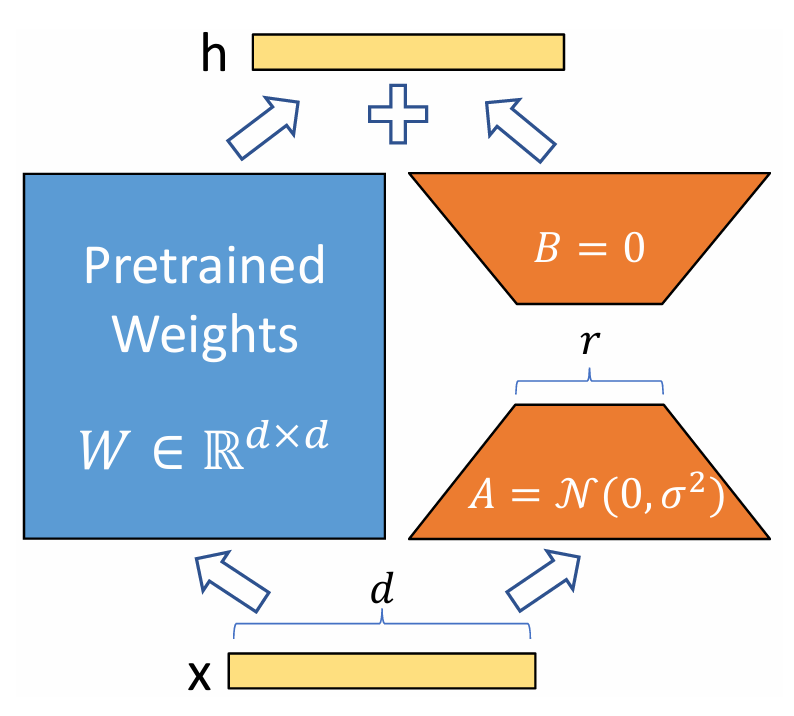
LoRA の大きなメリットの 1 つとして、学習すべきパラメータ数の大幅な削減があります。 仮に重み行列 \(W\) をそのまま更新するとすれば、更新すべきパラメータの数は \(dk\) となりますが、 \(A,\,B\) のみを学習する場合は \((d+k)r\ll dk\) にまで削減できます。 更新すべきパラメータ数が減少すれば学習に必要な時間も減少するため、LoRA は、学習時間・メモリ消費量の両面で効率的な手法といえます。
また、元のモデル全体のパラメータは凍結され、追加の小行列 \(A\) と \(B\) の重みのみを学習するため、タスクごとのモデルの切り替えも容易です。 すなわち、複数の異なるタスク(例:要約、質問応答、翻訳)を同じベースモデル \(W\) で実行する場合、タスクごとに学習した小さな \(A\) と \(B\) のペア(アダプターファイル)だけを保存しておき、推論時に動的に切り替えられるわけです。 もし LoRA を使わずに、ナイーブに元のモデルのパラメータを更新するのであれば、タスクごとにモデル全体を保存する必要があり、当然莫大なメモリを消費してしまいます。
QLoRA とは
QLoRA (Quantized LoRA) [3] とは、簡単にいえば、LoRA に量子化を組み合わせることでさらなるメモリ使用量の削減を実現する fine-tuning の手法です。 QLoRA では、元のモデルの重みを 4bit という低精度で量子化して GPU メモリに保持します。 これにより、モデルの重みを FP16 や BF16 といった 16bit 精度で読み込む場合に比べて、モデルの重みによるメモリ消費を約 \(1/4\) に抑えることができます。
なお、これらの 4bit のモデルの重みは、推論時および勾配計算時に必要に応じて逆量子化されます(4bit で計算されるわけではありません)。 この逆量子化処理などにより、LoRA に比べて fine-tuning に要する時間はわずかに長いとの報告もあります。
その他にも、QLoRA では、二重量子化やページドオプティマイザという技術により効率的なメモリ管理を実現しています。 QLoRA の実装に関するより詳細な説明は Appendix に回します。
注
ただし、QLoRA を用いたとしても fine-tuning に要するメモリが \(1/4\) になるわけではない点には注意が必要です。 fine-tuning に要するメモリの内訳としては
- モデルの重み
- 勾配
- オプティマイザーの状態
- アクティベーション(順伝播の途中結果)
などが存在します。 モデルの重みを量子化した場合でも、計算は基本的にモデルの重みを元の精度に逆量子化したうえで行われ、勾配やオプティマイザーの状態、アクティベーションなどは元の精度で保持されるため、その分のメモリ使用量は変わりません。 ただし、前述した LoRA の性質上、学習可能なパラメータ数は元のモデルサイズに比べて大幅に少数です。 そのため、勾配やオプティマイザーの状態のメモリ消費が全体のメモリ消費の大半を占めるかと言われれば、そういうわけでもありません(勾配やオプティマイザーの状態は、学習可能なパラメータに対してのみ保持されることに注意してください)。 実際に QLoRA が LoRA と比べてどれくらいのメモリ消費の削減を実現するかについては、後の章で実験的に示します。
unsloth について
unsloth [4] とは、LLM の fine-tuning の高速化・メモリ削減のために設計された Python ライブラリです。 sloth は英語で「ナマケモノ」という意味で、un-sloth で「ナマケモノのように遅くない」という意味合いのようです。
公式のドキュメント [4] によると、Triton 言語(OpenAI が開発した言語で、複雑な GPU カーネルを Python ライクな簡単な構文で書けるようにする言語)を用いて独自のカスタムカーネルを実装しているほか、独自実装で効率的な勾配や LoRA の計算を行うことにより、unsloth を使わない実装と比較して2 倍の学習速度の向上と 70% のメモリ消費量の削減を実現しています。 LoRA や QLoRA もサポートしており、これによりさらに高速・省メモリの fine-tuning を実現することができます。 unsloth の最適化に関するもう少し詳細な説明は Appendix に回します。
注
なお、2025 年 11 月現在、筆者の環境で 6000 Blackwell Max-Q において unsloth ライブラリを用いようとすると、以下のようなエラーが表示されました。 この場合、示されている通りに Xformers をソースからビルドすれば、筆者の環境では問題が解決しました。 また、unsloth の公式ドキュメントにも blackwell における unsloth の環境構築を解説したページ があるので、そちらも参考にしてください。
Unsloth: Will patch your computer to enable 2x faster free finetuning.
========
Switching to PyTorch attention since your Xformers is broken.
========
Unsloth: Xformers does not work in RTX 50X, Blackwell GPUs as of yet. Please build from source via
pip install ninja
pip install -v --no-build-isolation -U git+https://github.com/facebookresearch/xformers.git@main#egg=xformers前提知識 2:6000 Blackwell Max-Q はどのような GPU か?
前述のとおり、Fixstars では、 AIStation の GPU として 6000 Blackwell Max-Q を採用しています(Fixstars AIStationについて)。 詳細な性能調査はこちらの記事「NVIDIA RTX PRO 6000 Blackwell Max-Q はどのような GPU なのか?」で紹介しましたが、ここでも LLM の fine-tuning と関連性が高い点についていくつか取り上げます。 また、上の記事では H100 PCIe との比較を行いましたが、今回の実験では H100 SXM5 という GPU(H100 PCIe より高性能な GPU)で比較したため、この記事では改めて H100 SXM5 と性能を比較します。
まず、6000 Blackwell Max-Q を一言で表すならば、コストパフォーマンスに優れた GPU であるといえます。 H100 SXM5 はサーバー向けの GPU であり価格が公開されることは稀であるため、前述の記事の H100 PCIe との比較を引用すると、H100 PCIe が約 470 万円 [5] であるのに対して、6000 Blackwell Max-Q は 160 万円 [6] となっています。
理論演算性能の一部とメモリ帯域幅をまとめると以下のようになります。
| 6000 Blackwell Max-Q | H100 SXM5 | |
|---|---|---|
| アーキテクチャ | Blackwell (GB202) | Hopper (GH100) |
| FP64演算性能 (TFLOPS) | 1.71 | 33.5 |
| FP32演算性能 (TFLOPS) | 109.7 | 66.9 |
| INT32演算性能 (TOPS) | 109.7 | 33.5 |
| TF32演算性能 (TFLOPS) | 438.9 | 989.4 |
| FP16演算性能 (FP16 Accumulate) (TFLOPS) | 877.9 | 1978.9 |
| FP16演算性能 (FP32 Accumulate) (TFLOPS) | 877.9 | 1978.9 |
| BF16演算性能 (FP32 Accumulate) (TFLOPS) | 877.9 | 1978.9 |
| INT8演算性能 (TOPS) | 1755.7 | 3957.8 |
| FP8演算性能 (FP16 Accumulate) (TFLOPS) | 1755.7 | 3957.8 |
| FP8演算性能 (FP32 Accumulate) (TFLOPS) | 1755.7 | 3957.8 |
| FP4演算性能 (FP32 Accumulate) (TFLOPS) | 3511.4 | N/A |
| メモリ帯域幅 (GB/sec) | 1792 | 3352 |
この表から、FP32 と INT32 、および Blackwell アーキテクチャで初めてハードウェアサポートされた FP4 の演算能力を除いて H100 SXM5 の方が高性能であることがわかります。 一方で、単位価格あたりの性能という観点では 6000 Blackwell Max-Q が勝っているものも多いです( H100 SXM5 の詳細な価格が不明であるため単位価格あたりの性能を示すことはしませんが、H100 PCIe との比較は前述の記事からご覧になれます)。
また、6000 Blackwell Max-Q の特徴のうち LLM の fine-tuning に関連して特筆すべきは、そのメモリ容量の大きさです。 H100 SXM5 が 80GB であるのに対し、6000 Blackwell Max-Q は 96GB のメモリを備えています。 これにより、前述の効率的な fine-tuning 手法を用いれば、推論だけでなく fine-tuning も 1 台の GPU で行える可能性があります( fine-tuning は逆伝播を伴うため推論よりも大きなメモリを必要とする点に注意してください)。
また、電力消費の面でも 6000 Blackwell Max-Q は優れています。 H100 SXM5 が 700 W であるのに対して 6000 Blackwell Max-Q は 300 W であり、低く抑えられています。 これはワークステーションに適した特徴といえます。
測定方法
さて、前述のとおり、本記事では 6000 Blackwell Max-Q 上での fine-tuning の性能評価を行います。 まずは測定方法について取り上げておきます。
測定に使用した 6000 Blackwell Max-Q 搭載マシンのスペックは以下です。
- GPU: 6000 Blackwell Max-Q
- VRAM: 97887 MiB
- CPU max MHz: 4600.0000
- CPU min MHz: 800.0000
- Thread(s) per core: 2
- Core(s) per socket: 12
- Socket(s): 1
- CPU: Intel(R) Xeon(R) w5-2455X
- memory: 251 GiB
- PCIe Generation: 5
- OS: Ubuntu 22.04
- CUDA Version: 13.0
- Python Version: 3.10.12
- Docker Version: 28.4.0
また、使用したモデルは qwen3-8b 、qwen3-32b 、gpt-oss-120b の 3 つです。 データセットとしては、以下の 2 種を利用しました。 これらのデータセットの性質の違いにより生じた結果の差異については後ほど考察します。
- dataset 1:
japanese_alpaca_data(https://huggingface.co/datasets/fujiki/japanese_alpaca_data)alpacadataset (https://huggingface.co/datasets/tatsu-lab/alpaca) を日本語訳したもので、指示応答型のデータセットです。- (
max_seq_length=2048で切り捨て後の)入力の平均トークン数は 117
- dataset 2:
wikipedia_ja(https://huggingface.co/datasets/wikimedia/wikipedia)- 日本語 wikipedia 記事のデータセットです。
- 入力の平均トークン数が長いデータセットが欲しかったため、記事の本文を入力、記事のタイトルを出力として、本文からタイトルを当てさせるように学習させました。ただし、wikipedia の記事は一文目が「(タイトル)は、……」のフォーマットであることが多いため、単純さをなるべく除くため、一文目をあらかじめ機械的に取り除いた状態で学習させました。
- (
max_seq_length=2048で切り捨て後の)入力の平均トークン数は 861
- いずれも shuffle をかけたうえで、(時間の都合上)1000 件のみ抜粋して fine-tuning に利用し、各種測定を行いました。
注
wikipedia の本文を入力と見立てるのは実際想定される fine-tuning のユースケースと異なる可能性がありますが、本記事では fine-tuning の時間・メモリ効率の調査および fine-tuning によるモデルの応答スタイルの変化の定性的観察を目的としているため、データセットの質については本記事のスコープ外とします。
測定に使用した fine-tuning のコード
ここでは、実際に unsloth による gpt-oss-120b の fine-tuning に使用したコードを示しておきます。 fine-tuning の速度に大きく関係するハイパーパラメータの設定についてはコメントを加えます。 その他の詳細な設定についての説明は、unsloth による LoRA Hyperparameters Guide の記事が参考になります。
module の import
▶詳細
import torch
from unsloth import FastLanguageModel
from transformers import TrainingArguments
from datasets import load_dataset
from trl import SFTTrainer
from transformers.trainer_callback import TrainerCallback
import pandas as pd
import time
import oslogger の定義
▶詳細
- 学習の進捗・メモリ消費量を把握するために、以下の logger を定義しました。
class GpuMemoryLoggerCallback(TrainerCallback):
def __init__(self, log_file="gpu_memory_log.csv"):
self.log_file = log_file
self.log_data = []
self.start_time = None
def on_train_begin(self, args, state, control, **kwargs):
self.start_time = time.time()
os.makedirs(os.path.dirname(self.log_file), exist_ok=True)
if not os.path.exists(self.log_file):
df_header = pd.DataFrame(columns=[
"step", "epoch", "elapsed_time_sec",
"progress_ratio", "memory_allocated_gb",
"memory_reserved_gb", "peak_memory_gb"
])
df_header.to_csv(self.log_file, index=False)
def on_step_end(self, args, state, control, **kwargs):
if not torch.cuda.is_available():
return
log_interval = 10
if state.global_step % log_interval == 0 or state.global_step == state.max_steps:
elapsed_time = time.time() - self.start_time
memory_allocated = torch.cuda.memory_allocated(0) / (1024**3)
memory_reserved = torch.cuda.memory_reserved(0) / (1024**3)
peak_memory = torch.cuda.max_memory_allocated(0) / (1024**3)
log_entry = {
"step": state.global_step,
"epoch": state.epoch,
"elapsed_time_sec": elapsed_time,
"progress_ratio": state.global_step / state.max_steps,
"memory_allocated_gb": memory_allocated,
"memory_reserved_gb": memory_reserved,
"peak_memory_gb": peak_memory,
}
self.log_data.append(log_entry)
df = pd.DataFrame(self.log_data)
df.to_csv(self.log_file, mode='a', header=False, index=False)
self.log_data = []
def on_train_end(self, args, state, control, **kwargs):
if self.log_data:
df = pd.DataFrame(self.log_data)
df.to_csv(self.log_file, mode='a', header=False, index=False)モデルの読み込み・LoRA の設定
▶詳細
unsloth/gpt-oss-120b-unsloth-bnb-4bitは、4-bit 量子化によりモデルのサイズを抑えた unsloth によるモデルです。max_seq_length = 2048は、モデルが処理できる入力テキストの最大長を 2048 トークンに制限しています。この値は、fine-tuning の速度・メモリ消費量に影響します。FastLanguageModel.get_peft_model()を呼び出し、LoRA をモデルに適用します。r = 8は、上の LoRA の説明における \(r\) に対応する値で、fine-tuning の速度・メモリ消費量、および fine-tuning 後のモデルの性能に直接影響します。target_modulesには、モデル内の Attention 層(q_proj,k_proj,v_proj,o_proj)と MLP 層(gate_proj,up_proj,down_proj)のすべてを含めています。use_gradient_checkpointing = "unsloth"は、unsloth により実装された勾配チェックポインティングを用いることで、勾配計算時のメモリ使用量を削減するための設定です(詳細は Appendix 参照)。
model_id = "unsloth/gpt-oss-120b-unsloth-bnb-4bit"
output_dir = "./results_gpt-oss-120b_unsloth"
unsloth_log_file = f"{output_dir}/gpu_memory_gpt-oss-120b_log.csv"
max_seq_length = 2048
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = model_id,
max_seq_length = max_seq_length,
dtype = None,
load_in_4bit = True,
)
model = FastLanguageModel.get_peft_model(
model,
r = 8,
target_modules = [
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",
],
lora_alpha = 16,
lora_dropout = 0,
bias = "none",
use_gradient_checkpointing = "unsloth",
random_state = 3407,
)dataset の設定
▶詳細
formatting_function_alpacaによって、ロードした Alpaca 形式のデータ(instruction, input, output)を、LLM が理解できるチャット形式の単一テキストに変換しています。この関数の内部実装は使用するデータセットによって適宜変更を加える必要があります。
def formatting_function_alpaca(example, tokenizer):
instruction = example["instruction"]
input_text = example.get("input", "")
output_text = example["output"]
if input_text:
user_content = f"{instruction}\n{input_text}"
else:
user_content = instruction
messages = [
{"role": "user", "content": user_content},
{"role": "assistant", "content": output_text}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=False
)
return {"text": text}
dataset = load_dataset("fujiki/japanese_alpaca_data", split="train")
dataset = dataset.shuffle(seed=42)
subset_size = 1000
dataset = dataset.select(range(subset_size))
dataset = dataset.map(
formatting_function_alpaca,
remove_columns=dataset.column_names
)trainer の設定
▶詳細
num_train_epochsにより学習の epoch 数を指定します。per_device_train_batch_sizeによりバッチサイズを指定します。バッチサイズを大きくすると GPU メモリ消費が増加しますが、学習速度も向上します。gradient_accumulation_stepsにより勾配蓄積ステップ数を指定します。この値を増やすと実質的なバッチサイズを大きくできますが、学習速度は低下します。
training_args = TrainingArguments(
output_dir=output_dir,
num_train_epochs=1,
per_device_train_batch_size=16,
gradient_accumulation_steps=1,
optim="adamw_torch",
logging_steps=10,
learning_rate=2e-4,
fp16=False,
bf16=True,
max_grad_norm=0.3,
save_strategy="epoch",
)
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
args=training_args,
callbacks=[GpuMemoryLoggerCallback(log_file=unsloth_log_file)]
)training の実行
▶詳細
trainer.train()
trainer.model.save_pretrained("./result/gpt-oss-120b_unsloth_adapter")fine-tuning 後のモデルで推論を行う方法
▶詳細
import torch
from unsloth import FastLanguageModel
from peft import PeftModel
DATASET_NAME = "ALPACA"
def generate_response(model_to_use, instruction, input_text=""):
if input_text:
user_content = f"{instruction}\n{input_text}"
else:
user_content = instruction
messages = [
{"role": "user", "content": user_content},
]
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
inputs = tokenizer(
prompt,
return_tensors="pt"
).to(DEVICE)
outputs = model_to_use.generate(
**inputs,
max_new_tokens=1024,
do_sample=True,
temperature=0.7,
top_k=50,
top_p=0.95
)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
return response
test_cases = [
{
"instruction": "なぜ空は青く見えるのですか?小学生にもわかるように説明してください。",
"input": "",
"name": "知識と平易な説明能力"
},
{
"instruction": "以下の文を受動態に直してください。",
"input": "彼女は毎日、新しい詩を書いています。",
"name": "文法処理能力"
},
{
"instruction": "私は熱いものは冷やし、冷たいものは温めます。常に息をしていますが、肺はありません。私は一体何でしょう?",
"input": "",
"name": "論理的推論と情報統合能力"
}
]
BASE_MODEL_ID = "unsloth/gpt-oss-120b-unsloth-bnb-4bit"
ADAPTER_PATH = "./result/gpt-oss-120b_unsloth_adapter_alpaca"
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
OUTPUT_FILE = "unsloth_output.txt"
with open(OUTPUT_FILE, "w", encoding="utf-8") as f:
# evaluate base model
base_model, tokenizer = FastLanguageModel.from_pretrained(
model_name = BASE_MODEL_ID,
max_seq_length = 2048,
dtype = torch.bfloat16,
load_in_4bit = True,
)
base_model = FastLanguageModel.for_inference(base_model)
base_model.eval()
print("start base model evaluation...")
f.write("\n" + "="*60 + "\n")
f.write(" RESULTS: Base Model (GPT-OSS-120B) \n")
f.write("="*60 + "\n\n")
for case in test_cases:
response_base = generate_response(base_model, case["instruction"], case["input"])
f.write(f"--- Test Case: {case['name']} ---\n")
f.write(f"Instruction: {case['instruction']}\n")
if case['input']:
f.write(f"Input: {case['input']}\n")
f.write(f"Base Response:\n{response_base}\n\n")
# evaluate LoRA fine-tuned model
lora_model = PeftModel.from_pretrained(base_model, ADAPTER_PATH)
lora_model = FastLanguageModel.for_inference(lora_model)
lora_model.eval()
print("start LoRA evaluation...")
f.write("="*60 + "\n")
f.write(" RESULTS: Fine-Tuned Model (LoRA) \n")
f.write("="*60 + "\n\n")
for case in test_cases:
response_lora = generate_response(lora_model, case["instruction"], case["input"])
f.write(f"--- Test Case: {case['name']} ---\n")
f.write(f"Instruction: {case['instruction']}\n")
if case['input']:
f.write(f"Input: {case['input']}\n")
f.write(f"LoRA Response:\n{response_lora}\n\n")測定結果
本章 3 節までの実験はすべて前述の 6000 Blackwell Max-Q 搭載マシン 1 台上で行われたものです。
1. qwen3-8b に対する各種 fine-tuning 手法の比較
まず、qwen3-8b に対して、以下の 3 つの方法で fine-tuning を行いました。
- LoRA
- QLoRA
- QLoRA with unsloth(以下単に unsloth と略する)
そして、上記の各手法に対して、メモリ消費量および学習時間の比較を行いました。
ただし、本節では全手法において共通して batch_size=4
としました(次節以降では異なる)。 結果を以下に示します。
ただし、allocated memory
とはその時点で実際に使用されているメモリ、reserved memory とは PyTorch
のメモリ管理システムが今後の使用のために確保しているメモリのことを指します。
これらの値は、それぞれ前の章で示した logger の
torch.cuda.memory_allocated(0)、torch.cuda.memory_reserved(0)
によって取得しました。
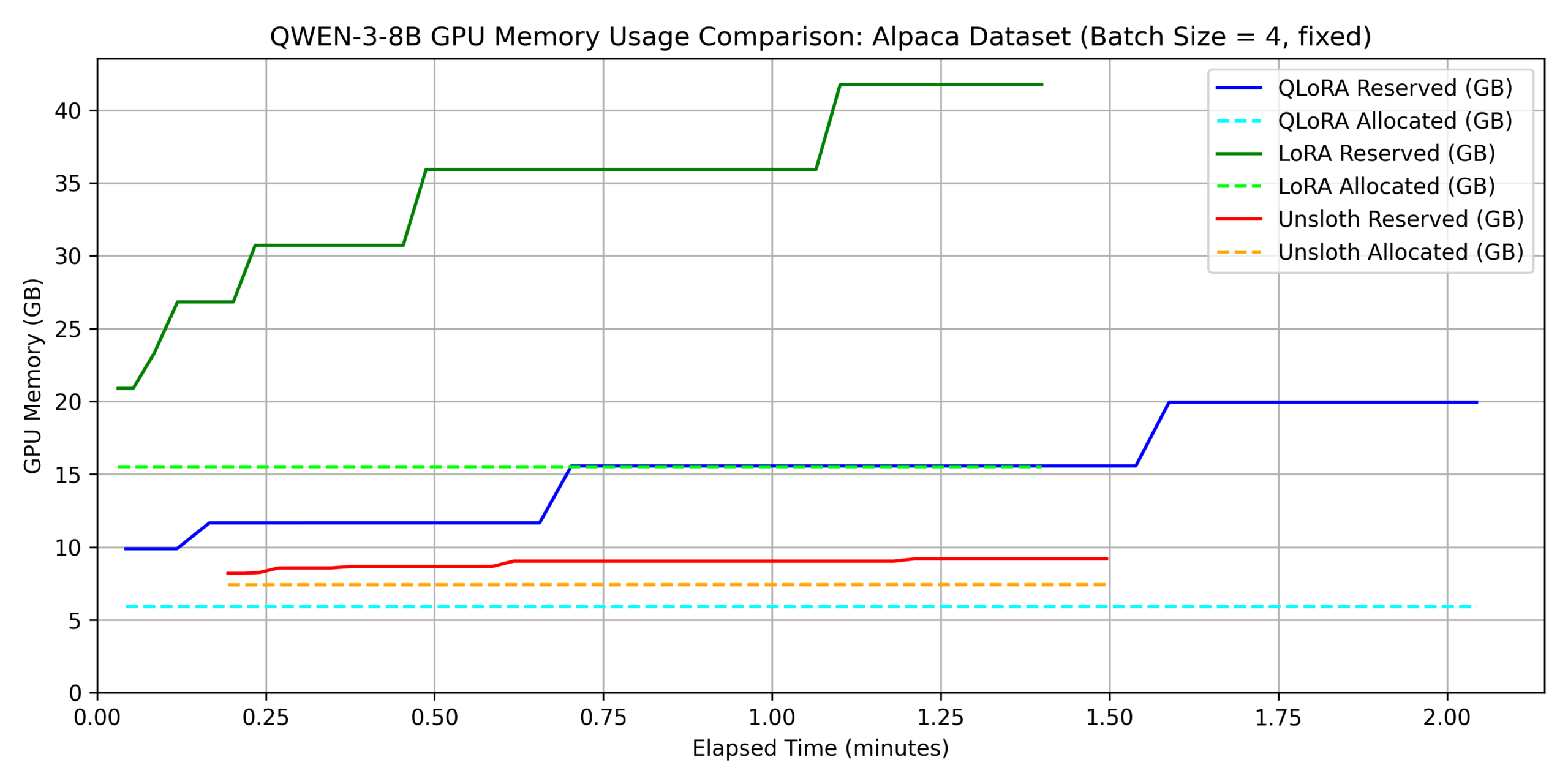
dataset 1:
japanese_alpaca_data
dataset 2:
wikipedia_ja
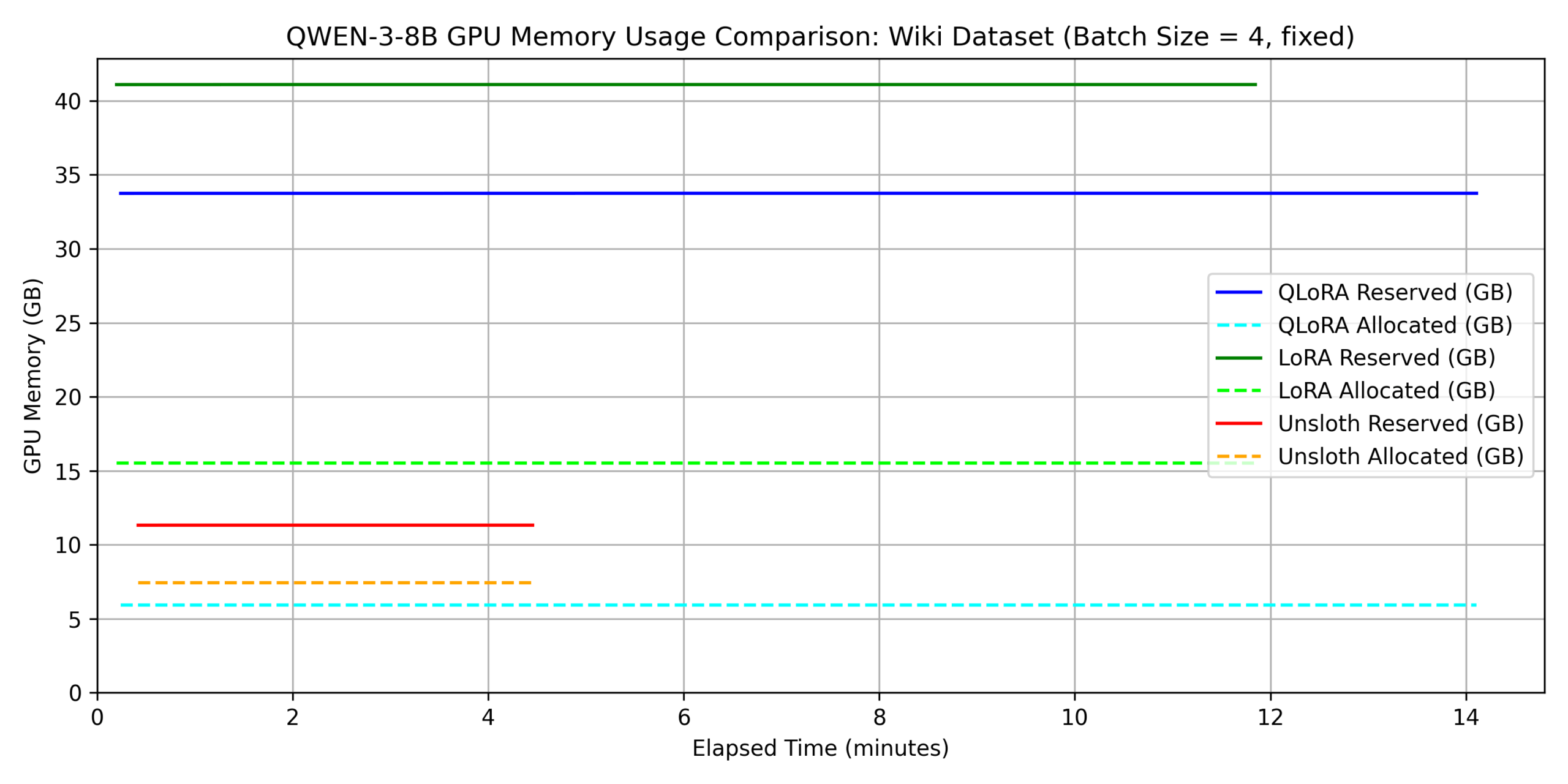
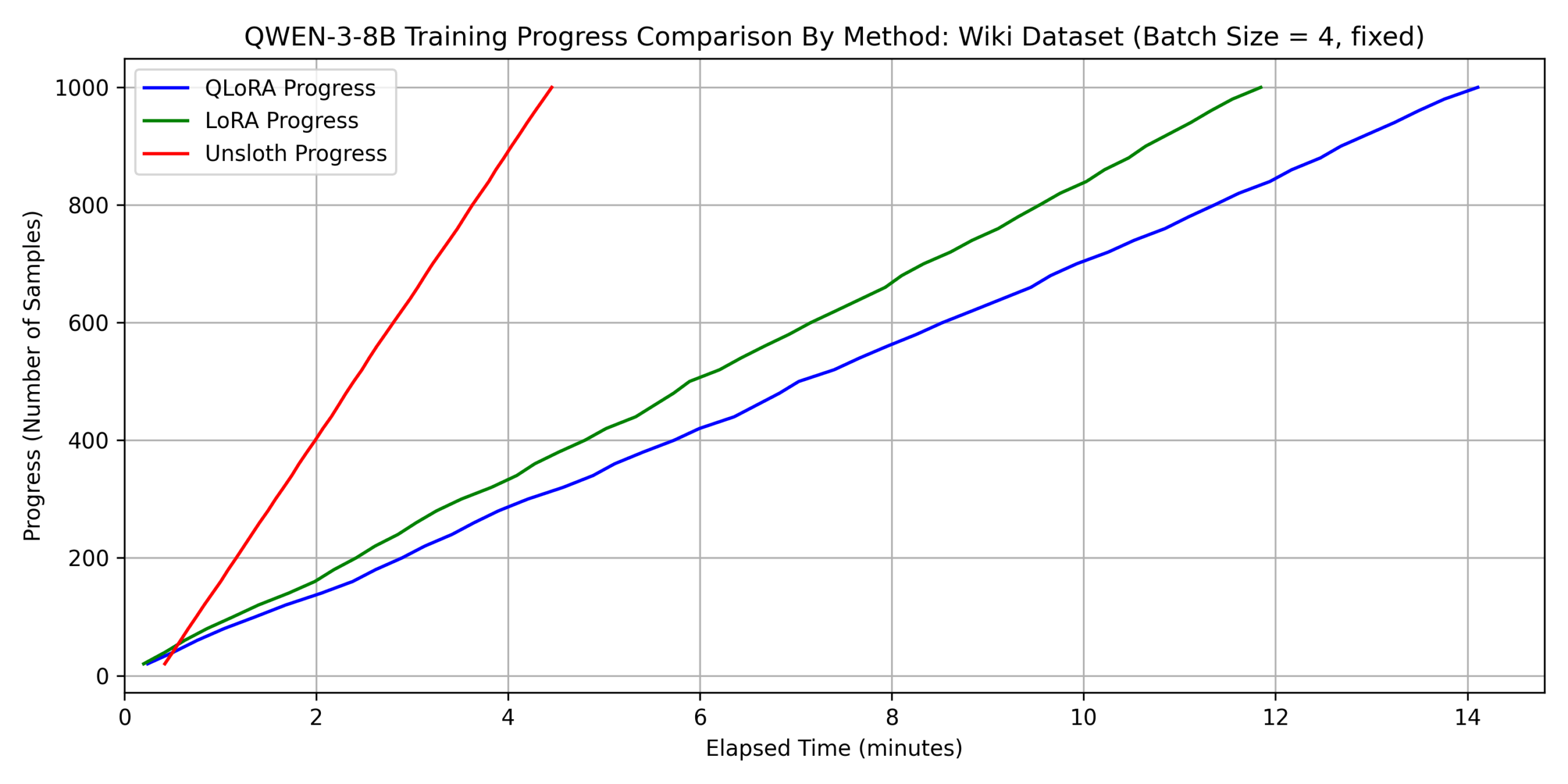
上の結果から、学習時間に関して以下のことがわかります。
- どちらのデータでも unsloth を用いない QLoRA が最も遅い。
- dataset 2 については、unsloth が他の手法に 3 倍程度以上の差をつけて速い。
- QLoRA の fine-tuning 時間は dataset 1 の場合に比べて dataset 2 では
約 7 倍遅くなっているが、unsloth では 約 3
倍の差にとどまっている。これは、平均シーケンス長の増加により attention
の計算が重くなったことで、unsloth の効率的な attention
実装がより効果的に働いたと考えられる。
- 補足として、self attention は入力シーケンス長さ \(L\) に対して \(\mathcal{O}(L^2)\) の計算量であるため、入力シーケンス長が伸びると支配的になりやすい。
注
上の図からわかるように、unsloth は fine-tuning の最初のサイクルに長い時間を要していることがわかります。これは、unsloth が triton 言語によるカスタムカーネルを用いた実装をしており、そのため初回関数呼び出しにおいては jit (just-in-time) コンパイルのオーバーヘッドが加わることが原因であろうと考えられます。
また、メモリ消費量に関して以下のことがわかります。
- unsloth を使わない LoRA/QLoRA を比較すると、QLoRA の方が allocated memory は \(1/3\) 程度となっている(\(1/4\) にならない理由に関しては QLoRA の説明部分を参照してください)。
- unsloth を使わない場合は allocated と reserved
の差分が非常に大きくなるが、unsloth
を使うことによりこの差分が小さくなっている。これは unsloth
がより効率的なメモリ管理を行っていることを示唆している。
- 特に、dataset 1 において unsloth を用いた場合の reserved memory は LoRA 使用時と比較して 80% 程削減されている。
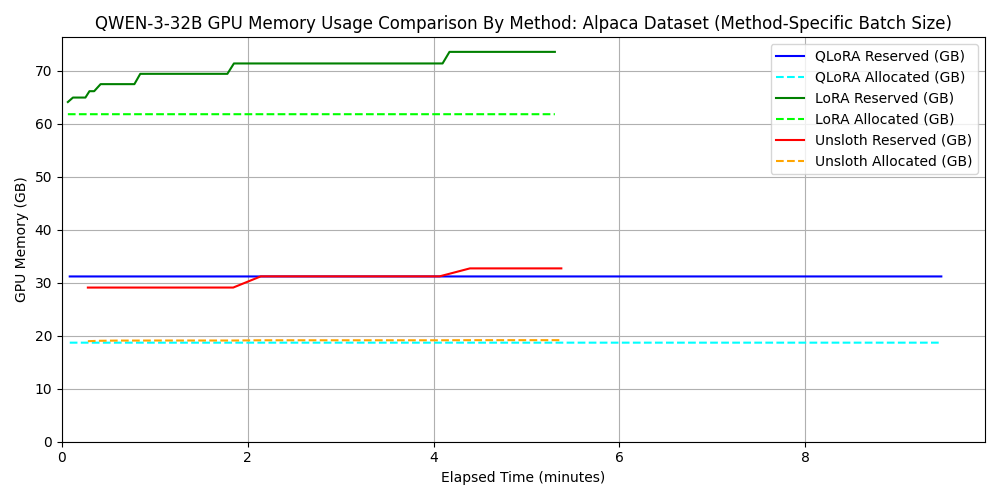
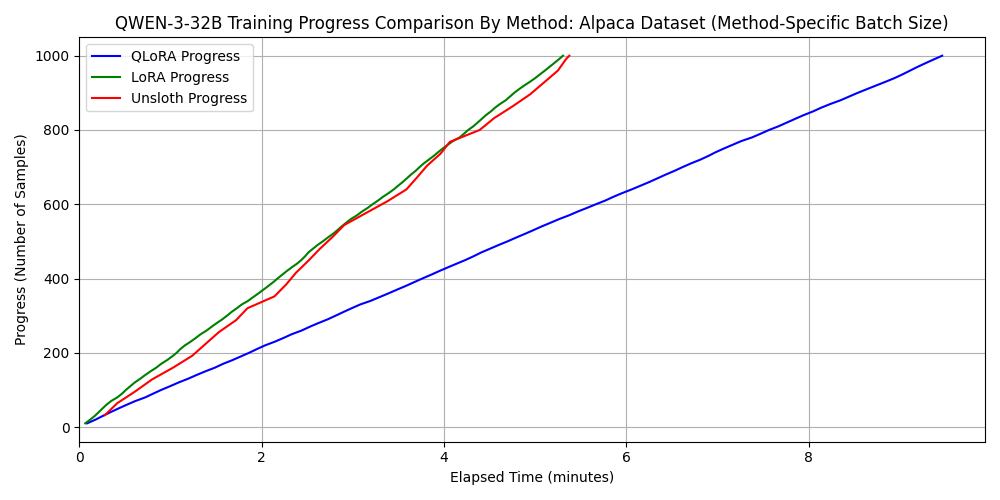
2. qwen3-32b に対する各種 fine-tuning 手法の比較
次に、よりパラメータ数の大きいモデルである qwen3-32b に対して、同様に
3 つの方法で fine-tuning を行いました。 ただし、unsloth を使わない LoRA
および QLoRA では batch_size=4 とすると 6000 Blackwell
Max-Q の VRAM 容量である 96 GB を超えてしまうため、
batch_size=2 としました。 一方で、unsloth による QLoRA
実装では、そのメモリ効率の良さがゆえに batch_size=32
でも問題なく実行できたため、 batch_size=32
で性能評価を行いました。 このように、メモリ効率に優れた fine-tuning
のフレームワークは、より大きなバッチサイズでの学習を可能にします。
バッチサイズの増加は計算の並列性を向上させるため、結果として学習時間の短縮にもつながります。
結果を以下に示します。 ただし、バッチサイズが異なるため、メモリ消費量のグラフが各手法のメモリ効率の良さを表さない点には注意してください。
dataset 1:
japanese_alpaca_data
dataset 2:
wikipedia_ja
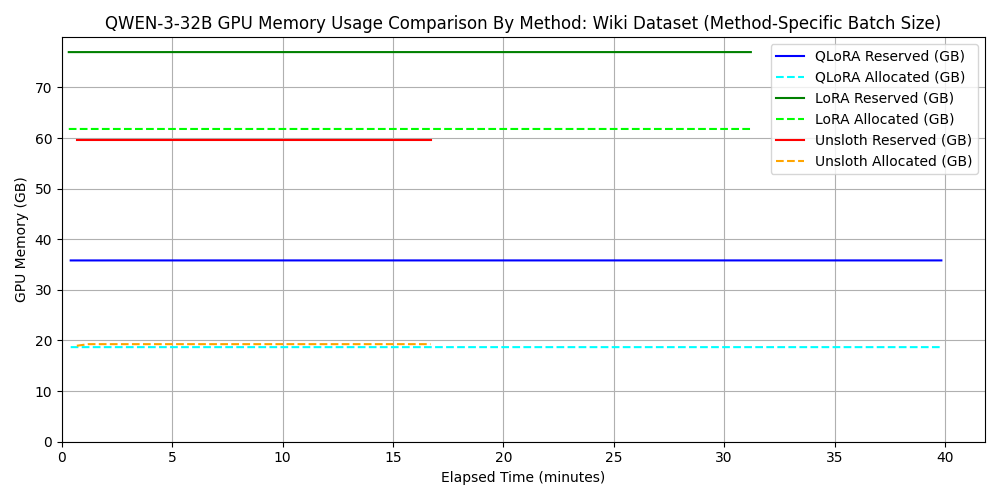
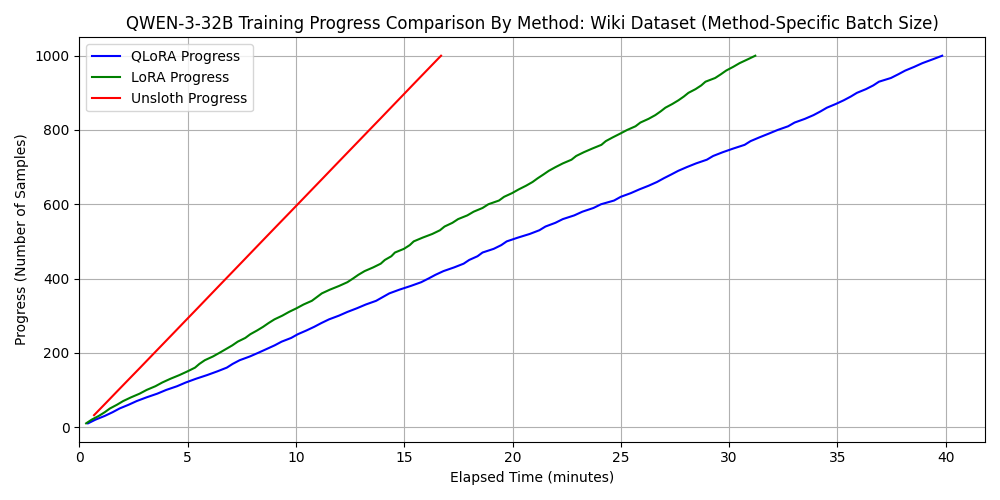
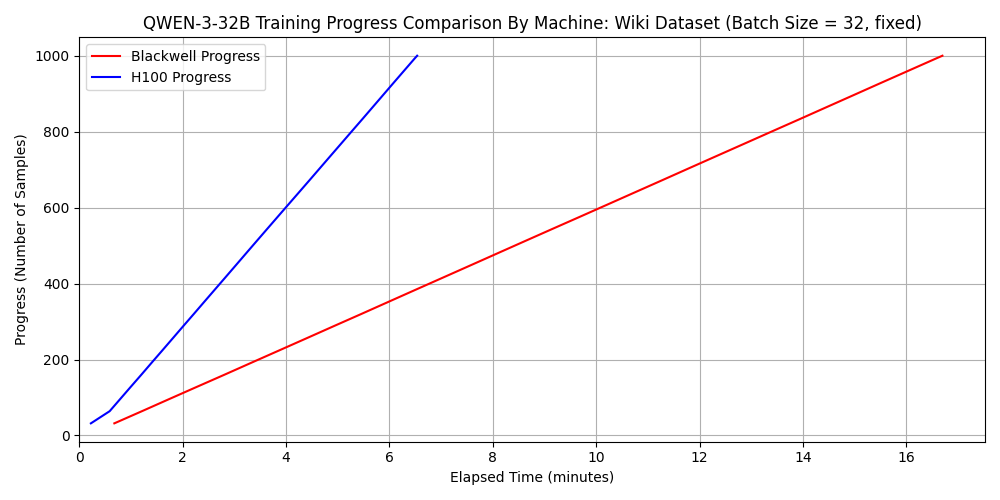
これもやはり、シーケンス長が長いと unsloth が速度面で有利になることがわかります。
3. gpt-oss-120b に対する unsloth による fine-tuning の性能評価
以上の実験により、unsloth
の効率的なメモリ管理、および高速化の効果が明らかになりました。
そこで、さらにパラメータ数の大きいモデルである gpt-oss-120b に対して
unsloth を用いた fine-tuning
を行い、性能を評価しました(これほど大規模なモデルだと、unsloth
を用いない実装では 6000 Blackwell Max-Q のメモリ容量である 96GB
を超えてしまい fine-tuning を行うことができません)。 batch size は
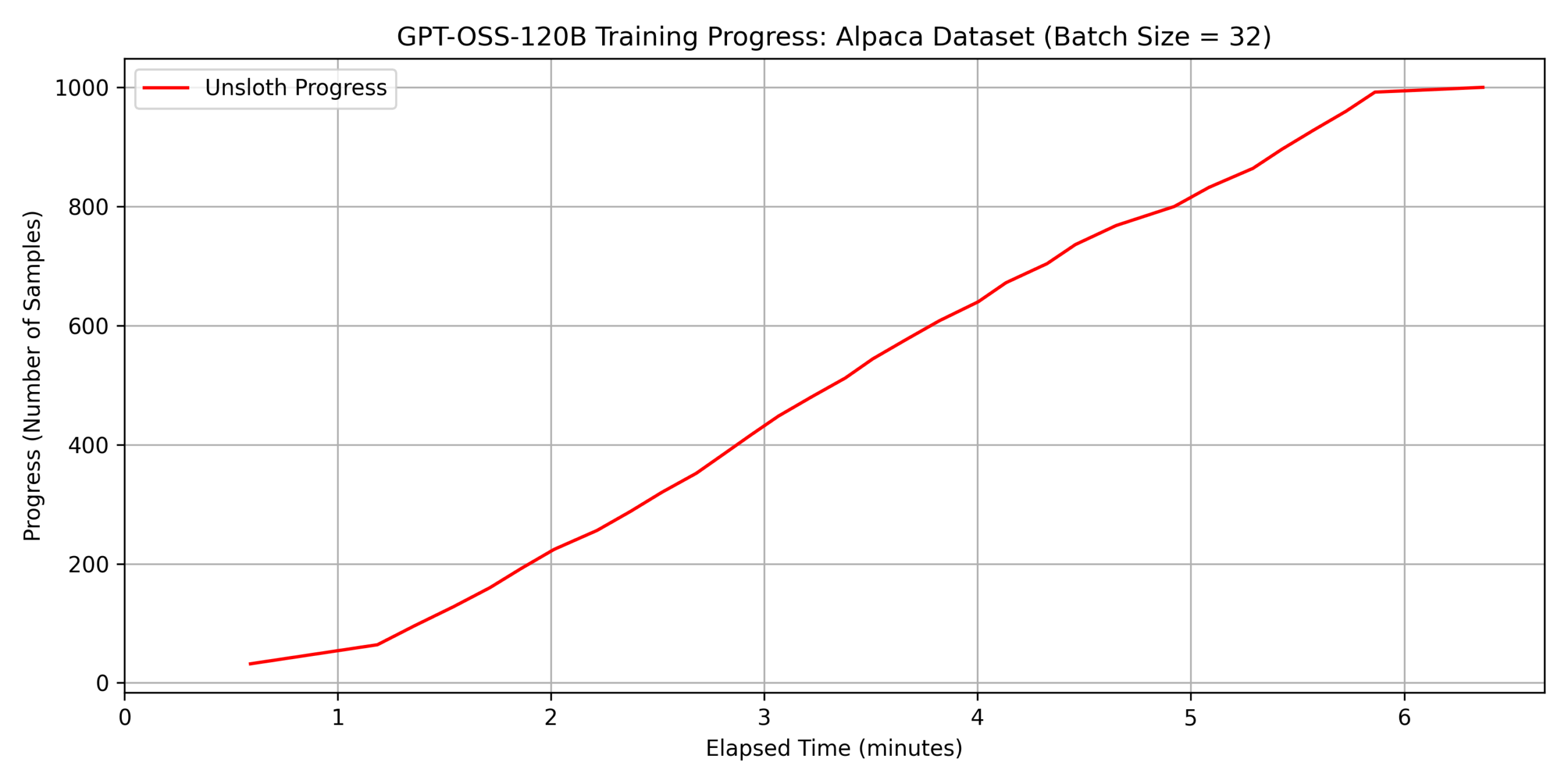
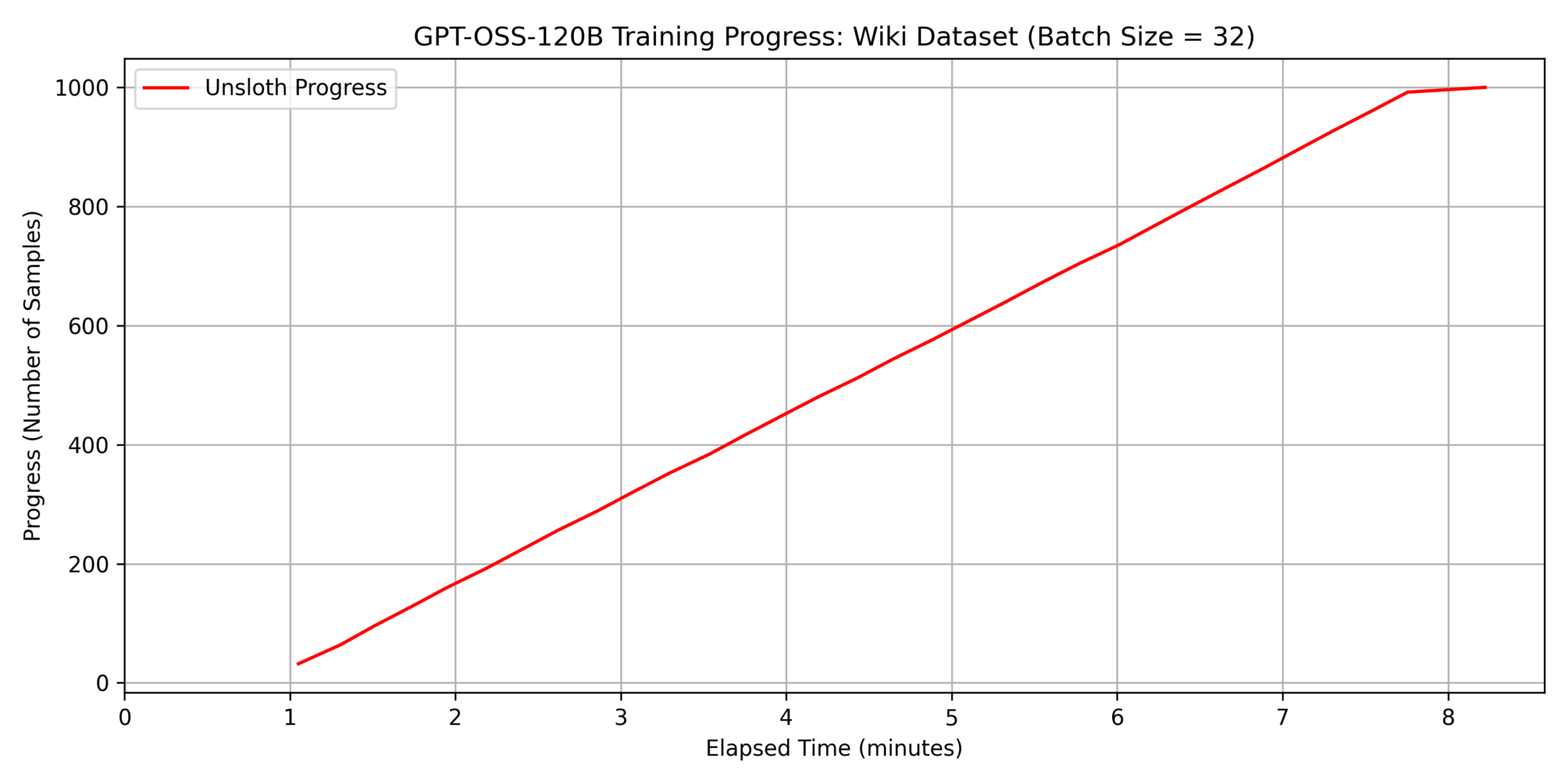
batch_size=32 としました。 結果を以下に示します。
dataset 1:
japanese_alpaca_data

dataset 2:
wikipedia_ja

注
最後にグラフの傾きが急激に小さくなっているのは、1000
件のデータセットに対して batch_size = 32
で学習しているため、最後のサイクルだけ学習されるデータが 8
件しかないことが原因です。
注
gpt-oss-120b と qwen3-32b の fine-tuning にかかった時間を比較してみると、qwen3-32b の方が(パラメータ数が少ないにもかかわらず)長くなっているのはなぜなのでしょうか。 unsloth による学習時に表示される「Trainable parameters」の値を確認したところ、以下のようになっていました。
- qwen3-32b: 67,108,864 of 32,829,232,128 (0.20% trained)
- gpt-oss-120b: 5,971,968 of 116,835,128,640 (0.01% trained)
"gate_proj", "up_proj", "down_proj"
を含めても、attention 層しか学習されないことが原因であるようです。
通常であればこれほど大規模なモデルに対して単一の GPU で fine-tuning を行うことは困難ですが、unsloth による効率的なメモリ管理によって、6000 Blackwell Max-Q の VRAM 容量である 96GB に収まり、fine-tuning が実行できるようになっています。 また、たとえば dataset 2 のようなトークン長の特徴を持つデータセットに対しては、1 時間で 5000 件程度のデータを学習可能であることがわかります。
あわせて、fine-tuning 前後でのモデルの応答の変化を確認しました。
ここでは、より応答形式の変化が確認しやすい wikipedia_ja
データセットを用い、fine-tuning に用いたデータセットの件数は \(2500\) としました。 前述のとおり、入力を「1
文目を除く wikipedia
の記事の本文」、出力を「その記事のタイトル」として学習させたため、fine-tuning
後のモデルにおいてはその記事が説明している単語を出力してくれることが期待されます。
結果の一例を以下に示します。
入力と応答の例
入力:
また、仲間意識をもって、みずからを他と区別する人々の集まり。社会の範囲は非常に幅広く、単一の組織や結社などの部分社会から国民を包括する全体社会まで様々である。社会は広範かつ複雑な現象であるが、継続的な意思疎通と相互行為が行われ、かつそれらがある程度の度合いで秩序化(この現象を社会統制と呼ぶ)、組織化された、ある一定の人間の集合があれば、それは社会であると考えることができる。社会を構成する人口の規模に注目した場合には国際社会や国民国家を想定する全体社会や都市や組織などの部分社会に区分できる。さらに意思疎通や相互作用、秩序性や限定性という社会の条件に欠落があれば全てを満たす社会と区別して準社会と呼ぶことができる。fine-tuning 前の応答:
ご提示いただいた文章は、**「社会」** の概念とその範囲・構成要素についての説明です。以下に要点を整理し、わかりやすくまとめます。 --- ## 1. 社会の基本的定義 - **仲間意識** を共有し、**自分たちを他者と区別** できる人々の集まり。 - 「社会」は **継続的な意思疎通** と **相互行為** が行われ、**一定の秩序化(社会統制)** がなされている集合体と定義される。 ## 2. 社会の範囲(スケール) (以下略)fine-tuning 後の応答:
社会
これにより、確かにモデルの応答形式がデータセットと同様の形式、すなわち wikipedia のタイトルのような短い単語に変化していることが確認できます。
4. 6000 Blackwell Max-Q と H100 SXM5 の比較
さて、次に視点を変えて、6000 Blackwell Max-Q と H100 SXM5 のそれぞれについて、fine-tuning の速度比較を行います。 比較対象とした H100 SXM5 搭載マシンのスペック等は以下です。
- GPU: NVIDIA H100 80GB HBM3
- VRAM: 81559 MiB
- CPU max MHz: 3800.0000
- CPU min MHz: 800.0000
- Thread(s) per core: 2
- Core(s) per socket: 56
- Socket(s): 2
- CPU: Intel(R) Xeon(R) Platinum 8480+
- memory: 2.0 TiB
- PCIe Generation: 5
- OS: Ubuntu 22.04
- CUDA Version: 12.8
- Python Version: 3.10.12
- Docker Version: 28.4.0
比較の条件としては以下のとおりです。
- 最も速度・メモリ効率に優れる手法である unsloth を用いた実装において比較
- モデルは qwen3-32b と gpt-oss-120b の 2 種(qwen3-8b は学習にかかる時間が特に短く、かつ qwen3-32b と同じアーキテクチャであるため除外)
- データセットは前述の dataset 1 と dataset 2 の 2 種
- 基本的には
batch_size=32で実行したが、H100 で gpt-oss-120b と dataset 2 の組み合わせの場合のみ VRAM が足りず、batch_size=16で実行した
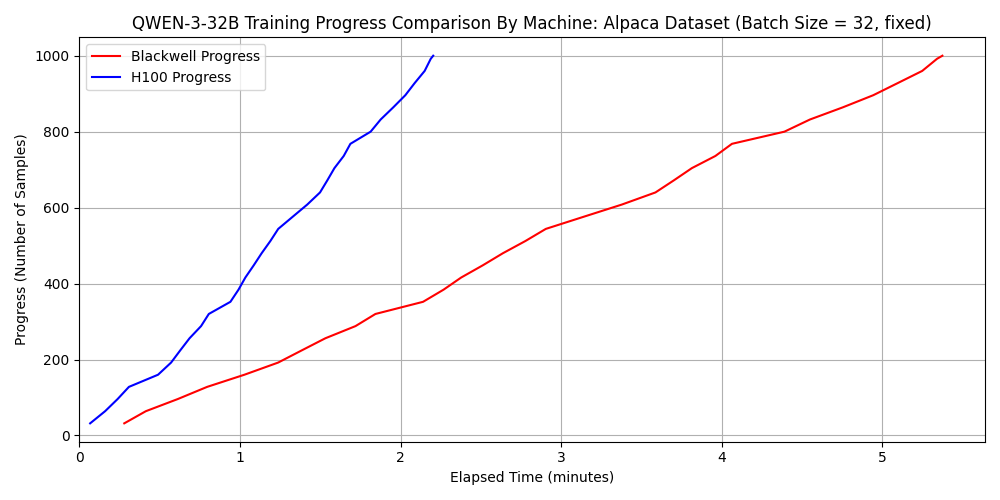
qwen3-32b における比較
※ 上図が dataset 1 に対する速度の比較、下図が dataset 2 に対する速度の比較
gpt-oss-120b における比較
※ 上図が dataset 1 に対する速度の比較、下図が dataset 2 に対する速度の比較
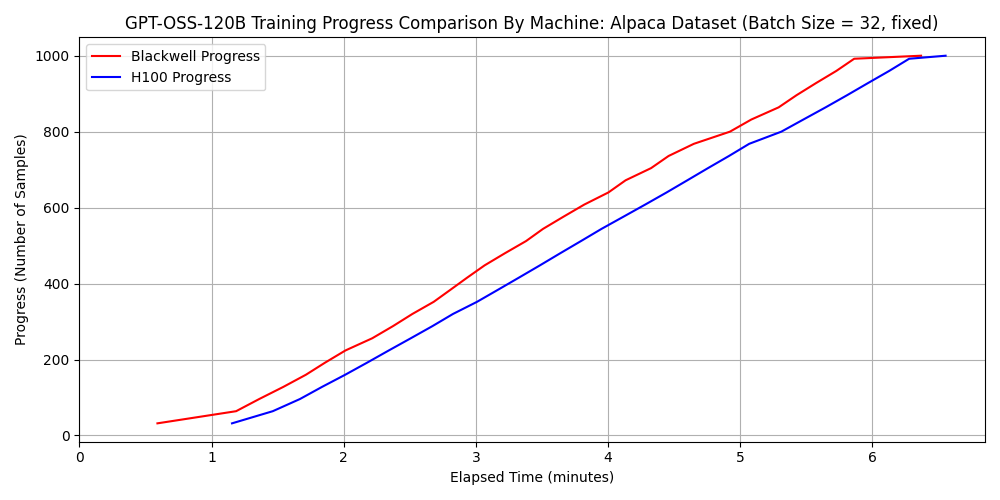
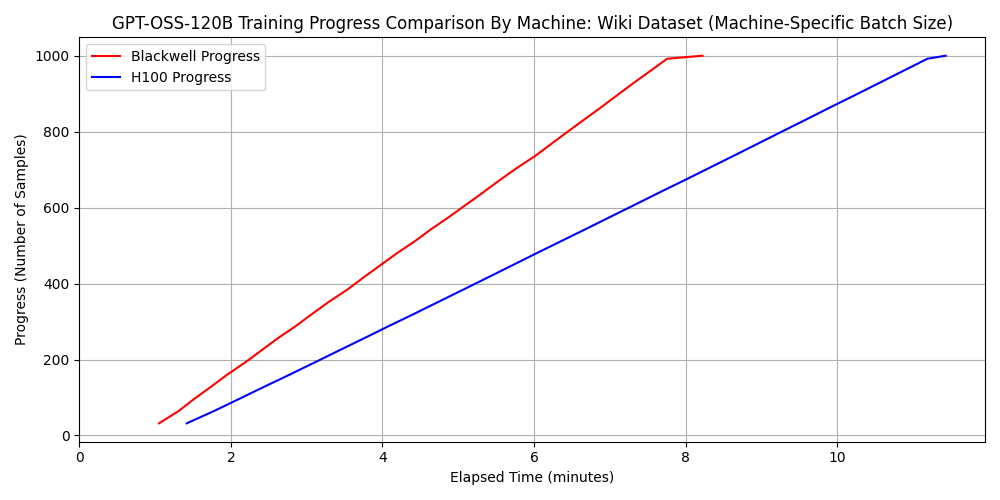
qwen3-32b ではどちらのデータセットについても H100 SXM5 の方が 2.5 倍以上速い一方で、gpt-oss-120b と dataset 2 の組み合わせにおいては 6000 Blackwell Max-Q の方が 1.3 倍程度速くなっています。 先ほど確認したように FP16 や BF16 の演算性能においては H100 SXM5 のほうが優れていたことを考慮すれば、この結果は不思議に思えるかもしれません。
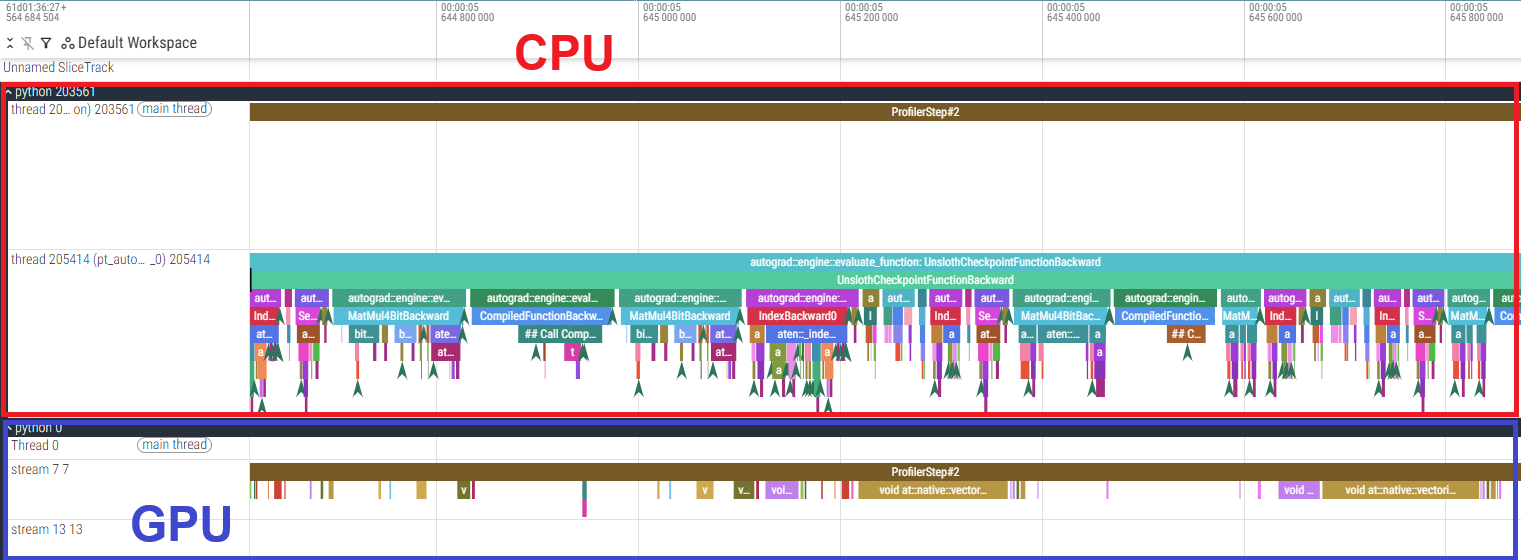
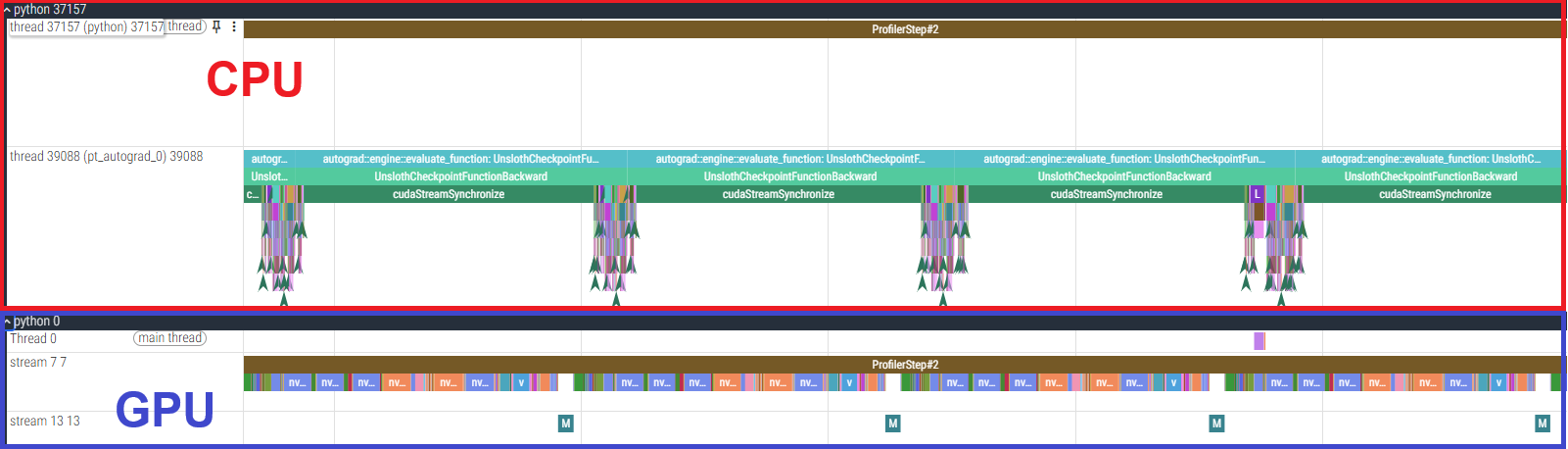
この原因を調査するため、gpt-oss-120b の fine-tuning に対して、PyTorch Profiler によりプロファイルを取得しました。 各カーネルの実行時間の表、およびタイムラインのうち backward 部分の一部を切り出したものを以下に示します。
- 6000 Blackwell Max-Q の結果

- H100 SXM5 の結果
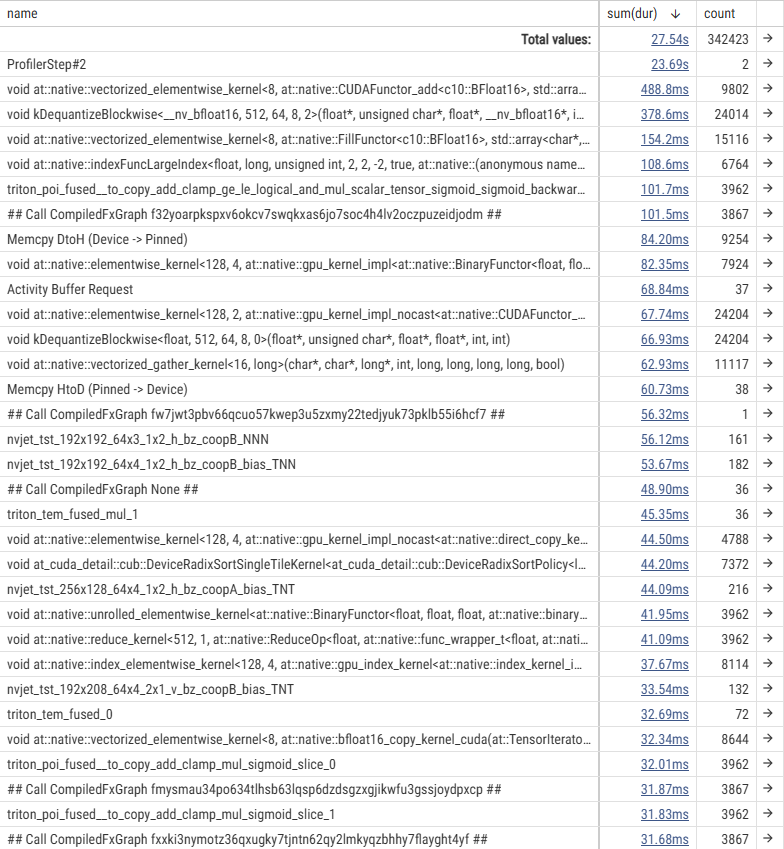

まず、実行時間の表から、単純な GPU 処理の実行時間は H100 SXM5 の方が短いことがわかります。 その一方で、GPU カーネル間に大きな空白ができており GPU が遊んでしまっていること、および CPU の処理が律速となっていることが確認できます。
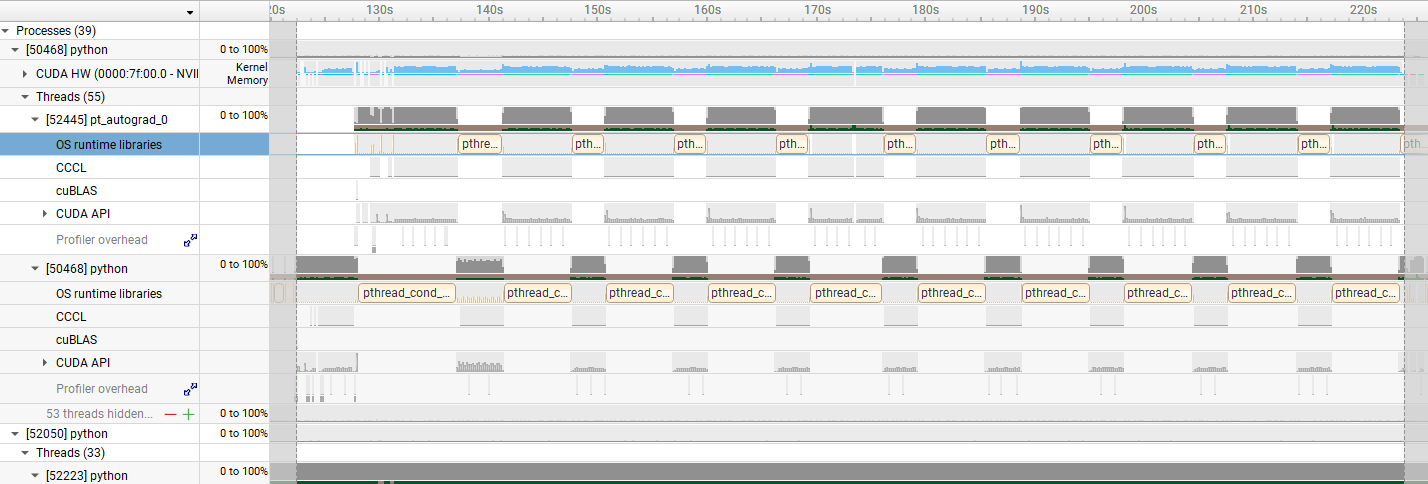
そこで、さらに Nsight Systems でカーネルの稼働時間を確認した結果を以下に示します。 水色で示されたデータがカーネルの稼働時間を表します。
- 6000 Blackwell Max-Q の結果
- H100 SXM5 の結果
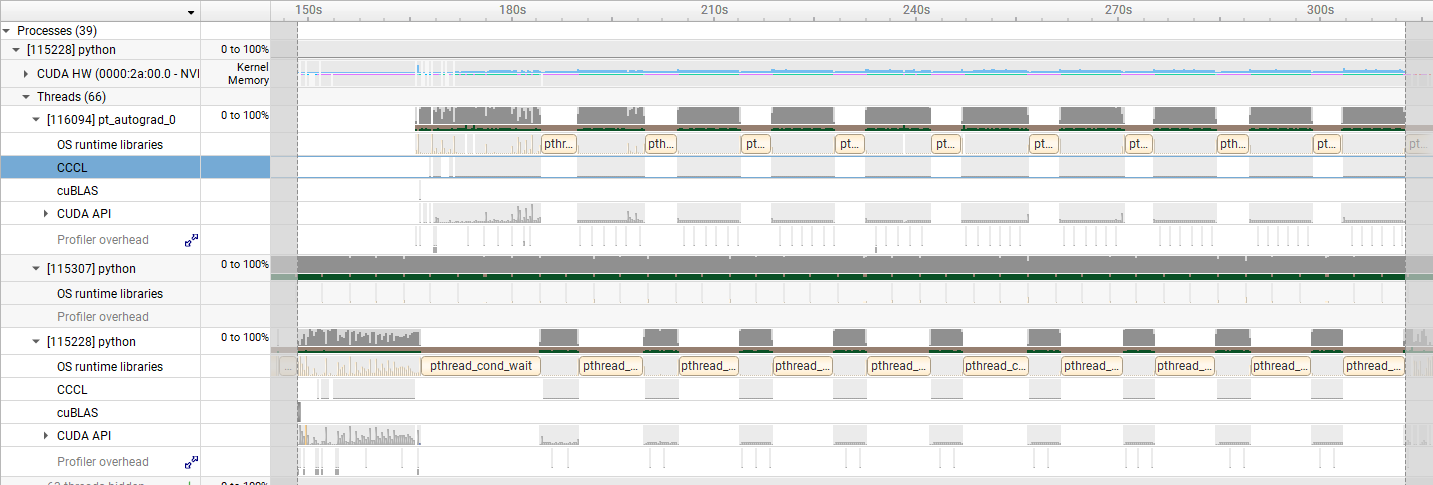
この図から、H100 SXM5 の方がより GPU が遊んでいる時間が長い、すなわち CPU の処理に要する時間が長いことが確認できます。 これが今回の gpt-oss-120b の実行時間の差の主な原因と考えられます。
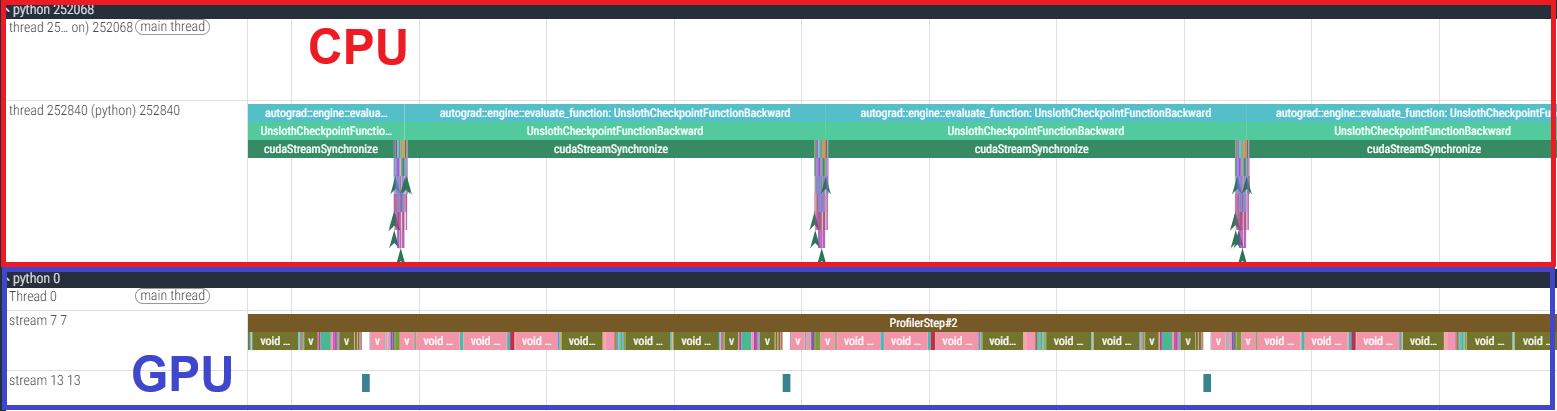
なお、qwen3-32b に対しても PyTorch Profiler によるプロファイルをとったところ、下図のように GPU はほぼ常に使用されていることがわかりました。 qwen3-32b は MoE を採用しない密なモデルであり、かつ学習されるパラメータ数が多いため、したがって GPU の処理時間が増え GPU 律速となり、それゆえ単純に GPU の演算性能で上回る H100 SXM5 の方が高速になったと考えられます。
- 6000 Blackwell Max-Q の結果
- H100 SXM5 の結果
LLM の fine-tuning における 6000 Blackwell Max-Q の優位性についての検討
さて、LLM の fine-tuning において 6000 Blackwell Max-Q はどのような優位性を持っているといえるでしょうか。
まず、6000 Blackwell Max-Q の最大の魅力はその安価さです。 6000 Blackwell Max-Q (ワークステーション向け)と H100 SXM5 (データステーション向け)では用途が違うため当然といえば当然ですが、前述のとおり、その価格には約 3 倍の違いがあります。 6000 Blackwell Max-Q で十分な状況であれば、そうすべきです。
そのうえで、fine-tuning に要する時間についての検討です。 まず、gpt-oss-120b のような比較的疎なモデルを fine-tuning させたい場合は、上に示したようにそもそも 6000 Blackwell Max-Q が高速である可能性があります。 このようなケースでは、6000 Blackwell Max-Q が速度・コストの両面で有利といえるでしょう。 一方で、qwen3-32b における単純な速度では H100 SXM5 の方が勝っていました。 そこで、1 時間あたりに fine-tuning 可能なデータセットの件数を算出してみると、以下のようになります。
| dataset 1 | dataset 2 | |
|---|---|---|
| 6000 Blackwell Max-Q | 11000 | 3600 |
| H100 SXM5 | 27000 | 9200 |
| dataset 1 | dataset 2 | |
|---|---|---|
| 6000 Blackwell Max-Q | 9400 | 7300 |
| H100 SXM5 | 9200 | 5200 |
ワークステーションにおける fine-tuning のユースケースとしては、たとえば「社内向け AI について、労働時間外である夜間にデータを更新する」といったケースが考えられます。 仮に学習に 8 時間使えるとして、上の表の 8 倍の件数を fine-tuning に利用できるわけです。 これを踏まえて実際に 6000 Blackwell Max-Q における fine-tuning で十分かは、実際のデータセットとの兼ね合わせになるでしょう。 仮に 6000 Blackwell Max-Q 搭載マシン 1 台で十分な規模感であれば、その安価さも踏まえて、6000 Blackwell Max-Q が有力な選択肢となりえます。
また、6000 Blackwell Max-Q の長所であるメモリサイズの大きさは LLM の fine-tuning に直接的に効いてきます。 当然ながら、メモリサイズの違いはロードできるモデルの違いに直結します。 たとえば gpt-oss-120b は 4-bit 量子化したとしてもメモリの重みだけで約 30 GB を必要とします。 したがって、6000 Blackwell Max-Q は既存のワークステーション向け GPU と比べても、GPU 1 台でより多様なモデルを fine-tuning 可能となります。 また、モデルを VRAM にロードできるかできないかという一元的な境目以外にも、メモリの大きさは学習速度にも直結します。 これは、メモリが大きいほど大きなバッチサイズでの学習が可能となるためです。 大きなバッチサイズは、一般に学習の並列度を高め、実効的な処理速度を向上させます。 上に示したように、6000 Blackwell Max-Q では、H100 SXM5 では学習不可能なバッチサイズで学習が可能となることがあり、これは高速化に寄与します。
最後に消費電力についてです。 前述のとおり、最大消費電力は H100 SXM5 が 700 W であるのに対して、ワークステーション向け GPU である 6000 Blackwell Max-Q は 300 W であり、低く抑えられています。 たとえば gpt-oss-120b の fine-tuning においては、電力だけではなくかかる時間も 6000 Blackwell Max-Q のほうが短いため、消費電力の観点でも 6000 Blackwell Max-Q は優れているといえます。 これはワークステーション向けの GPU として嬉しい点でしょう。
以上をまとめると、6000 Blackwell Max-Q は、ワークステーション等において運用にかかるコストを抑えつつ fine-tuning を行う状況に特に適しているといえます。
おわりに
再掲になりますが、この記事では以下のことを示しました。
1. fine-tuning 手法とその速度・メモリ消費の実験的測定について
- 効率的な fine-tuning 手法である LoRA、QLoRA を用いて LLM を fine-tuning する方法を調査した。また、fine-tuning を高速・省メモリで行うことのできるライブラリである unsloth の使い方を調査した。
- 6000 Blackwell Max-Q を用いた際の LLM の fine-tuning
にかかる実行速度・メモリ効率について実験的に調査した。
- モデルとしては、qwen3-8b、qwen3-32b、gpt-oss-120b を対象とした。
- unsloth により、LoRA での fine-tuning に対して最大 3 倍程度の高速化と最大 80% 程度の省メモリを実現できた。
- 特に長文シーケンスで unsloth の高速化効果が大きかった。
- QLoRA と unsloth により、gpt-oss-120b の fine-tuning を 6000 Blackwell Max-Q 1 枚を搭載したマシン上で実行できた。
2. 6000 Blackwell Max-Q という GPU の優位性について
- 6000 Blackwell Max-Q と H100 SXM5 について、fine-tuning
に要する時間の比較を行った。
- 比較には qwen3-32b と gpt-oss-120b を用いた(qwen3-8b は学習にかかる時間が特に短く、かつ qwen3-32b と同じアーキテクチャであるため比較実験は省略した)。
- qwen3-32b では H100 SXM5 の方が高速であったが、gpt-oss-120b では 6000 Blackwell Max-Q の方が高速であった。
- 6000 Blackwell Max-Q の特徴であるコストパフォーマンスの良さ、メモリの大きさ、電力の低さは、ワークステーションの運用コストを抑えつつ fine-tuning を行う状況に特に適していることを明らかにした。
Appendix
A. QLoRA の量子化手法の詳細
ここでは、論文[3]中で示されている QLoRA の量子化・逆量子化方法について解説します。
1. 背景:Block-wise Quantization
一般に、量子化はどのような計算によって行われるのでしょうか。 仮に FP32 で表された行列 \(X^{\mathrm{FP32}}\) を INT8 に量子化する場合、シンプルな実装では、以下のような式によって量子化後の行列 \(X^{\mathrm{INT8}}\) を得るでしょう。ただし、\(\mathrm{absmax}(X^{\mathrm{FP32}})\) は \(X^{\mathrm{FP32}}\) の要素の絶対値の最大値、round は丸め処理を行う関数をそれぞれ意味します。
\[X^{\mathrm{INT8}}=\mathrm{round}\left(\frac{127}{\mathrm{absmax}(X^{\mathrm{FP32}})}X^{\mathrm{FP32}}\right)\]
一般に、モデルの重みは量子化して保存しても、計算時には元の精度に戻してから行う(逆量子化)ことで精度を保とうとすることが多いです。 量子化後の値から元の値を復元するには、\(\dfrac{127}{\mathrm{absmax}(X^{\mathrm{FP32}})}\) という値を \(X^{\mathrm{INT8}}\) とは別に保持しておく必要があり、この \(c^{\mathrm{FP32}}:=\dfrac{127}{\mathrm{absmax}(X^{\mathrm{FP32}})}\) という値を量子化定数といいます。 逆量子化を行う際には、以下の計算を行います。
\[X^{\mathrm{FP32}}_{\mathrm{dequantized}}=\frac{X^{\mathrm{INT8}}}{c^{\mathrm{FP32}}}\]
たとえば、\(X=[2.50, -0.70, 0.12, 0.48]\) を量子化した場合、量子化後の値 \(X_{\mathrm{quantized}}\)、量子化定数 \(c\)、逆量子化後の値 \(X_{\mathrm{dequantized}}\) はそれぞれ以下のようになります。
\[ X_{\mathrm{quantized}} = [127, -36, 6, 24] \] \[ c = 127/2.50 = 50.8 \] \[ X_{\mathrm{dequantized}} = X_{\mathrm{quantized}}/c = [2.5000, -0.7087, 0.1181, 0.4724] \]
しかし、このような量子化方法にはいくつか問題点があります。 まず挙げられるのが、行列内に絶対値が異常に大きい外れ値があると、その値が \(\mathrm{absmax}\) を支配し、量子化定数 \(c\) が小さくなってしまうという点です。 すると、\(cX^{\mathrm{FP32}}\) の値はほとんどが \(0\) に近い小さな値になってしまい、量子化後の値がほとんど \(0\) に近い値になってしまいます。
この問題に対処する方法が Block-wise Quantization です。 この方法では、重み行列をより小さいブロックに分割し、ブロックごとに \(\mathrm{absmax}\) と量子化定数 \(c\) を計算します。 これにより、外れ値の影響をそのブロック内に収めることができ、精度を向上させることができます。 一方で、ブロック数を \(n\) とした場合、量子化定数 \(c\) も \(n\) 個保持しておく必要があるため、メモリ使用量は増加します。
2. 新しいデータ型 NF4 の提唱
もう 1 つ量子化において問題になるのが、当然ながら量子化そのものによる精度の劣化(量子化誤差)です。 この問題に対処するため、論文 [3] 中では、NF4 (NormalFloat4) というデータ型を提唱しています。 通常、事前学習済みの LLM の重みは、1. で示したような \(\mathrm{absmax}\) による正規化を行えば、中心が \(0\) の正規分布に従います。 標準的な均一量子化では、量子化の幅をデータ範囲全体に均等に割り当てますが、これにより重みの大部分を占める \(0\) 付近の情報が相対的に粗くなる可能性があります。 これに対し、NF4 では、この「重みの正規分布」という性質を利用し、量子化レベル(ビン)を情報理論的に最適になるように非均等に割り当てます。 具体的には、正規分布の分位点に基づいて量子化の境界を決定することで、情報量の多い \(0\) 付近の重みに対してより多くの量子化レベルを割り当て、精度低下を最小限に抑えつつ 4bit への圧縮を実現しています。
3. 二重量子化
さて、1. で示したように、ブロックごとの量子化を行うと、その分保持すべき量子化定数の数も増え、メモリ使用量の増大という問題が生じます。 そこで、QLoRA では Double Quantization(二重量子化) という手法によりこの問題に対処しています。 二重量子化とは、量子化定数 \(c\) をさらに量子化するというものです。 一般に、精度の維持のため量子化定数 \(c\) は FP32 等の比較的高精度で保持されます。 たとえば \(c\) を FP32 で保持し、Block-wise Quantization のブロックサイズを \(64\) とした場合、1 パラメータあたり量子化定数は
\[ 32/64 = 0.5\,\mathrm{bits} \]
を必要としますが、この \(c\) をさらに 256 ブロック単位で量子化し、1 ブロックに 1 つの \(c_2^{\mathrm{FP8}}\) と 256 ブロックに 1 つの \(c_1^{\mathrm{FP32}}\) を保持することで、1 パラメータあたりの量子化定数は
\[ 8/64+32/(64\cdot256)=0.127\,\mathrm{bits} \]
にまで削減できます。
B. unsloth の内部実装について
前述のとおり unsloth では高速・省メモリの fine-tuning を実現していますが、もう少し具体的にはどのような最適化が施されているのでしょうか。 その一例は以下の公式ブログ記事にも掲載されていますが、興味深い内容ですのでここでもいくつか簡単に紹介させていただきます。
- Introducing Unsloth: 30x faster LLM training
- Unsloth Gradient Checkpointing – 4x longer context windows
1. Triton 言語による独自カスタムカーネルの実装
unsloth では、Triton 言語を用いて独自のカスタムカーネルを実装しており、RoPE (Rotary Positional Embeddings) や cross entropy などの計算を最適化しています。 これらの例はブログ記事「Introducing Unsloth: 30x faster LLM training」でも紹介されています。より詳細な実装は github を参照してください[10][11]。
2. 勾配計算の手動実装
unsloth では勾配計算を PyTorch の自動微分に頼らず手動で実装することで効率化を実現しています。 この際に使われているテクニックが以下です。
- 行列積の順序の最適化
- inplace 演算によるメモリの節約
1 について補足します。 まず一般に、連続行列積 \(ABC\) がある場合、その計算順序、つまり \((AB)C\) と \(A(BC)\) のどちらで計算するかによって、必要な算術演算の回数は変わります。 2 つの行列 \(A\in\mathbb{R}^{m\times n},\,B\in\mathbb{R}^{n\times l}\) があるとき、少なくともナイーブな実装では \(mnl\) 回の乗算が必要です。 したがって、3 つの行列 \(A\in\mathbb{R}^{m\times n},\,B\in\mathbb{R}^{n\times l},\,C\in\mathbb{R}^{l\times k}\) に対しては、
- \((AB)C\) : \(mnl+mlk\) 回の乗算
- \(A(BC)\) : \(nlk+mnk\) 回の乗算
が必要となります。 特に LoRA を用いる際には大きい次元を持つ元のモデルの重み行列と小さい次元を持つ LoRA アダプター行列が混在するため、unsloth では行列積の計算順序を手動実装によりうまく調整することで FLOPs を削減することに成功しているようです。
3. 勾配チェックポインティングの独自実装
勾配チェックポインティング(Gradient Checkpointing)とは、学習時のメモリ消費を削減するための技術です。 モデルの順伝播中に計算される中間結果(アクティベーション)をすべてメモリに保存する代わりに、特定の中間層のアクティベーションのみを保存し、逆伝播時に必要となった中間結果をその場で再計算することで、VRAM 使用量を削減します。 トレードオフとして、再計算の分だけ学習速度はわずかに低下します。
ブログ記事「Unsloth Gradient Checkpointing – 4x longer context windows」では、この勾配チェックポインティングを独自に実装することによって、1.9% の実行時間増加を代償に 30% の VRAM 削減を実現したと記述されています。 具体的には、アクティベーションを非同期に GPU の VRAM から CPU のメモリにオフロードするというものです。 このデータ転送にノンブロッキング呼び出しを利用して順伝播と逆伝播の計算処理の裏に隠蔽することにより、オーバーヘッドを最小限に抑えているようです。
この最適化によって、より長いコンテキストウィンドウを持つモデルをより少ない VRAM で動作させられます。
参考文献
- [1] https://github.com/huggingface/peft
- [2] Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen, “LoRA: Low-Rank Adaptation of Large Language Models”
- [3] Tim Dettmers and Artidoro Pagnoni and Ari Holtzman and Luke Zettlemoyer, “QLoRA: Efficient Finetuning of Quantized LLMs”
- [4] https://docs.unsloth.ai/
- [5] AKIBA PC Hotline!編集部 オリオスペックが「NVIDIA H100 Tensor Core GPU」の受注開始、約471万円
- [6] AKIBA PC Hotline!編集部 VRAM 96GB搭載の「NVIDIA RTX PRO 6000 Blackwell Max-Q Workstation Edition」が登場、約160万円
- [7] https://www.nvidia.com/content/dam/en-zz/Solutions/design-visualization/quadro-product-literature/NVIDIA-RTX-Blackwell-PRO-GPU-Architecture-v1.0.pdf
- [8] https://resources.nvidia.com/en-us-hopper-architecture/nvidia-h100-tensor-c
- [9] https://huggingface.co/blog/RakshitAralimatti/learn-ai-with-me
- [10] https://github.com/unslothai/unsloth
- [11] https://github.com/unslothai/unsloth-zoo

Tags
About Author
takanori.saiki
Leave a Comment
Tags
Favorite Post

 2023年1月27日
2023年1月27日 2017年8月22日
2017年8月22日
Archives
- 2026年2月
- 2026年1月
- 2025年12月
- 2025年11月
- 2025年8月
- 2025年5月
- 2025年4月
- 2024年11月
- 2024年10月
- 2024年7月
- 2024年5月
- 2024年4月
- 2024年2月
- 2024年1月
- 2023年12月
- 2023年6月
- 2023年5月
- 2023年4月
- 2023年2月
- 2023年1月
- 2022年12月
- 2022年10月
- 2021年11月
- 2021年9月
- 2021年6月
- 2021年3月
- 2021年2月
- 2020年12月
- 2020年10月
- 2020年7月
- 2020年6月
- 2020年5月
- 2020年4月
- 2020年3月
- 2020年2月
- 2020年1月
- 2019年12月
- 2019年11月
- 2019年10月
- 2019年9月
- 2019年8月
- 2019年6月
- 2019年4月
- 2019年3月
- 2019年2月
- 2019年1月
- 2018年12月
- 2018年11月
- 2018年10月
- 2018年8月
- 2018年6月
- 2018年5月
- 2018年4月
- 2018年3月
- 2018年2月
- 2017年12月
- 2017年11月
- 2017年10月
- 2017年9月
- 2017年8月
- 2017年7月
- 2017年6月
- 2017年5月
- 2017年3月
- 2016年12月
- 2016年11月
- 2016年8月
- 2016年7月
- 2016年3月
- 2016年2月
- 2016年1月
- 2015年12月
- 2015年11月
- 2015年10月
- 2015年8月
- 2015年6月
- 2015年3月
- 2015年2月
- 2015年1月
- 2014年12月
- 2014年11月
keisuke.kimura in Livox Mid-360をROS1/ROS2で動かしてみた
Sorry for the delay in replying. I have done SLAM (FAST_LIO) with Livox MID360, but for various reasons I have not be...
Miya in ウエハースケールエンジン向けSimulated Annealingを複数タイルによる並列化で実装しました
作成されたプロファイラがとても良さそうです :) ぜひ詳細を書いていただきたいです!...
Deivaprakash in Livox Mid-360をROS1/ROS2で動かしてみた
Hey guys myself deiva from India currently i am working in this Livox MID360 and eager to knwo whether you have done the...
岩崎システム設計 岩崎 満 in Alveo U50で10G Ethernetを試してみる
仕事の都合で、検索を行い、御社サイトにたどりつきました。 内容は大変参考になりま�...
Prabuddhi Wariyapperuma in Livox Mid-360をROS1/ROS2で動かしてみた
This issue was sorted....