このブログは、株式会社フィックスターズのエンジニアが、あらゆるテーマについて自由に書いているブログです。
NVIDIA Blackwell 上での LoRA チューニングに向けたプロファイリングと最適化
はじめに
Fixstars でアルバイトをしています若林大起です。
近年 AI モデルを個人の好みや特定の用途に合わせて改変する「パーソナライゼーション」の需要が高まってきています。このため、クラウドの潤沢な計算資源だけでなく、ハードウェア資源が限られているローカル環境で部分的に学習を行う機会が増えてきました。しかし、ローカル環境で追加学習のコードをそのまま動かすだけでは、マシンの性能を十分に引き出せず非効率な学習を行っている場合が少なくありません。この問題を解決し、限られた GPU リソースを最大限に活用するためには、プロファイリングによって性能のボトルネックを特定し、的確なチューニングを行うことが不可欠です。本記事では、その一例として、Stable Diffusion v1.5 を対象とした Hugging Face の標準的な LoRA 学習スクリプトを題材に、プロファイリングから性能改善までの一連の流れを解説します。また、今回は最新アーキテクチャである NVIDIA Blackwell を使用したため、そこで遭遇した特有の注意点についても共有します。
背景:ローカル環境における追加学習の需要増加
近年、汎用的な AI 学習モデルを個人の好みや特定の用途に合わせてパーソナライズする取り組みは、すでに多くのサービスで実用化されています。例えば、画像生成 AI の分野では Civitai [^1] のようなプラットフォームで、特定のアニメキャラクターや画風を再現するための追加学習モデルが数多く共有されており、AI による表現の幅を大きく広げています。
このような AI 学習モデルのパーソナライズを支えている技術が LoRA (Low-Rank Adaptation) [^2] です。LoRA は、事前学習済みモデルの重み W はそのままに、その差分 dW のみを学習するアプローチです。フルファインチューニングでは W(サイズ d x d)を直接学習するため、d^2 個のパラメータ更新が必要でした。LoRA では、この差分行列 dW を下図に示すような2つの細長い行列 A(サイズ d x r)と B(サイズ r x d)の積で近似する点にあります(dW = BA)。
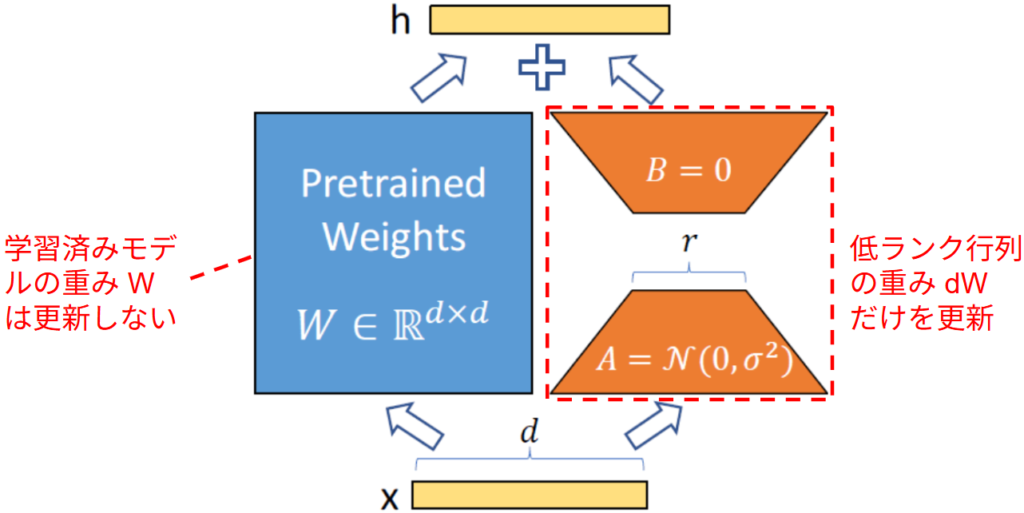
ここで r は d より遥かに小さいランクである(r << d)ため、学習対象は A と B の 2 * d * r 個のパラメータのみとなり、更新量が劇的に削減されます。例えば、d=4096, r=8 の場合、学習すべきパラメータ数を約 1670 万個から約 6.5 万個にまで減らすことができます。
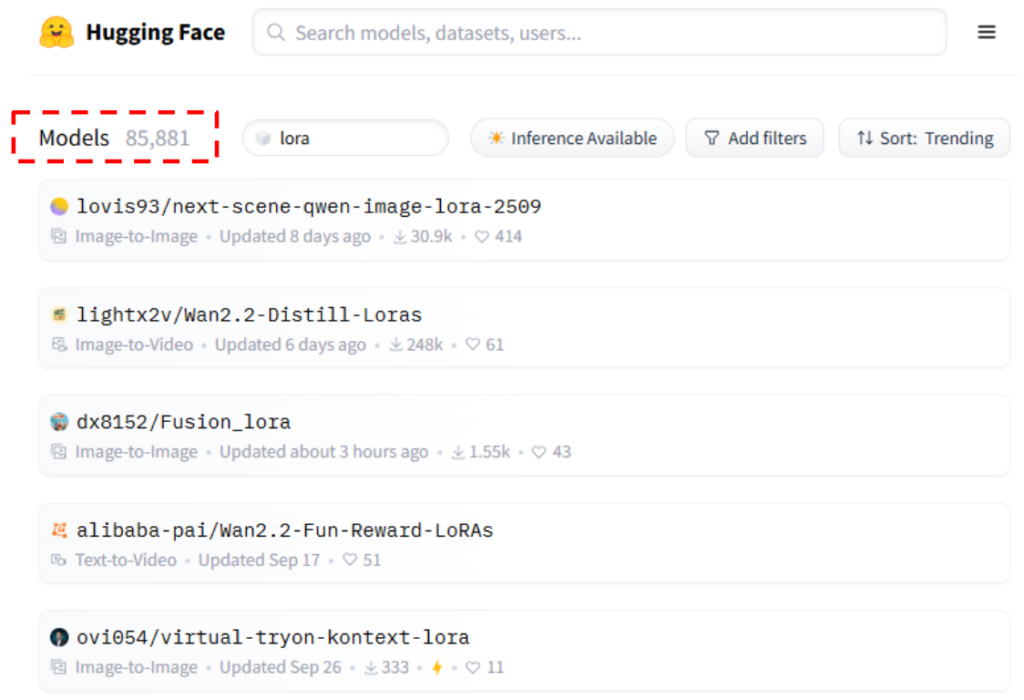
この圧倒的な追加学習効率の良さから、LoRA は広く普及しました。下図に示す通り、Hugging Face [^3] では LoRA の検索結果は 85000 件を超えます(2025年10月時点)。そのほかにも Stable Diffusion Web UI [^4] や kohya_ss [^5] のようなツールを使い、多くのユーザが自身のローカル PC で LoRA の作成・利用を行っています。このように、LoRA は企業だけでなく、一般のユーザにとっても、AI 学習モデルをパーソナライズするための身近な手段となりました。この背景から、ローカル環境での LoRA 学習の効率化は重要な課題と言えます。
問題点:ただ動かすだけでは GPU が使い切れていない
ローカル環境での資源利用状況を確認するために、まずは Hugging Face diffusers で提供されている未改変の LoRA 学習コードを実行し、GPU の使用率推移を nvitop コマンド [^6] で測定しました。NVIDIA GPU のデフォルトコマンドとしては nvidia-smi コマンドが一般的ですが、時系列で状態をモニタリングするためには利用しづらいためこちらのコマンドを使用しています。学習のセットアップは以下の通りで、汎用的な画像生成モデルである Stable Diffusion v1.5 を、特定のアニメ NARUTO の画風に特化させる、という追加学習タスクを実行しました。なお、一般ユーザがローカル環境で追加学習を行うことを想定しているため、GPU は GPU 0 のみを利用します。
実行環境
- マシンセットアップ
- CPU: Intel(R) Xeon(R) w5-2455X 24 core (Hyper-Threading enabled)
- GPU: NVIDIA RTX PRO 6000 Blackwell Max-Q Workstation Edition
- OS: Ubuntu 22.04
- Kernel: Linux 6.8.0
- Docker 28.3.3
- PyTorch: 2.8.0
- LoRA セットアップ
- ソースコード: Hugging Face
diffusersのtrain_text_to_image_lora.py[^7] - ベースモデル:
runwayml/stable-diffusion-v1-5[^8] - データセット:
lambdalabs/naruto-blip-captions[^9] - 使用 GPU: GPU 0
- 解像度 (
--resolution): 512×512ピクセル - バッチサイズ (
--train_batch_size): 1 - 勾配累積ステップ (
--gradient_accumulation_steps): 4 - 最大学習ステップ数 (
--max_train_steps): 1500 - 学習率 (
--learning_rate): 0.0001 (1e-4) - 混合精度 (
--mixed_precision): fp16
- ソースコード: Hugging Face
下図における nvitop で観測された GPU の稼働状況を確認すると、LoRA 学習ステップ時の平均的な GPU 使用率はわずか 44% 程度であることが分かりました。
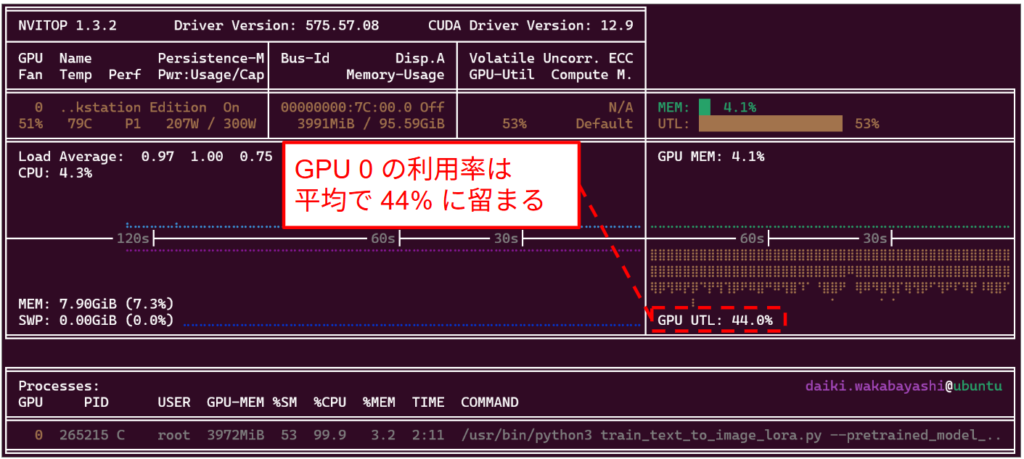
以上の結果より、ダウンロードしたままのコードをただ動かすだけでは、限られた GPU リソースを無駄にしてしまう可能性があることが示唆されました。このアイドル時間の原因を分析し、GPU を限界まで使い切るための最適化が必要になります。
PyTorch Profiler を用いたボトルネックの特定
アプリケーションにおけるパフォーマンスのボトルネックを特定するには、一般に perf のような汎用ツールが使われます。このようなツールは Linux のカーネルレベル・アセンブリレベルでトレーシングが可能になる一方で、ログの容量が非常に大きくなってしまうために実行時間が長い機械学習のワークロードには不向きです。PyTorch Profiler [^10] は、学習ループのわずか数ステップを計測するだけで、どの Python コードが、どの CUDA カーネルを、どれくらいの時間実行したかをミリ秒単位で可視化することができます。本記事では、この PyTorch Profiler を利用して LoRA 追加学習におけるボトルネックを分析しました。
PyTorch Profiler の使い方は簡単で、分析したいコードブロック(通常は学習ループ全体)を torch.profiler.profile コンテキストで囲み、各イテレーションの終わりに prof.step() を呼び出すだけです。計測結果は TensorBoard [^11] で出力し、後で詳細に分析できるようにします。
以下は、今回の学習スクリプトに Profiler を組み込むための具体的なコード変更例です。計測は最初の数ステップだけで十分なため、schedule オプションを使ってウォーミングアップ後に 5 ステップだけを記録するように設定しています。schedule オプションを用いることで、ある程度イテレーションが進んでから profile を開始することや、特定のインターバルの epoch のみを取り出すことができる点は汎用的なプロファイリングツールと異なる PyTorch Profiler ならではのメリットであると感じました。また、TensorBoard と連携して必要な情報を GUI 形式で手軽に閲覧できる点も使いやすくてよかったです。
コード:train_text_to_image_lora.py の main() 関数
# PyTorch Profiler を初期化
prof = torch.profiler.profile(
# wait=1: 最初の1ステップは無視 (初期化処理を除くため)
# warmup=1: 次の1ステップでGPUをウォームアップ
# active=5: その後の5ステップを実際に記録
# repeat=1: 上記のサイクルを1回だけ繰り返す
schedule=torch.profiler.schedule(wait=1, warmup=1, active=5, repeat=1),
on_trace_ready=torch.profiler.tensorboard_trace_handler(os.path.join(args.output_dir, "profiler_logs")),
...
)
# Profiler を開始
prof.start()
# メインの学習ループ
for epoch in range(first_epoch, args.num_train_epochs):
# ... (学習ステップの処理) ...
# 学習ステップが完了したタイミングで prof.step() を呼ぶ
prof.step()
# Profiler を停止
prof.stop()
この変更を加えたスクリプトを実行すると、profiler_logs ディレクトリ以下に *.pt.trace.json という拡張子でログが生成されます。このファイルを chrome://tracing で開くか、TensorBoard の PROFILEタブ(別途プラグインが必要な場合があります)で表示することで、学習ステップ内の各処理にかかった時間を詳細に分析することができます。ただし、ブラウザで開く場合にはデバッグ設定を有効にする必要があります。
以下が今回得られた実行時のプロファイル結果です。横軸が時間で、左から右に時系列順で実行されている関数が表示されます。perf と併用して利用されることが多い FlameGraph [^12] とは異なり、横軸が時系列順となっている点が嬉しいポイントです(FlameGraph ではアルファベット順などで関数がソートされるため、横軸が重要な意味を持ちません)。このため、関数の実行過程や待ち状態に入るタイミングなどを一目で理解することができます。縦軸は関数のコールスタックを表しており、下の関数ほどコールスタックが深くなっています。perf は CPU プロファイリングに利用されますが、PyTorch Profiler では GPU の稼働状況も合わせたプロファイル結果を表示してくれる点がとても便利です。

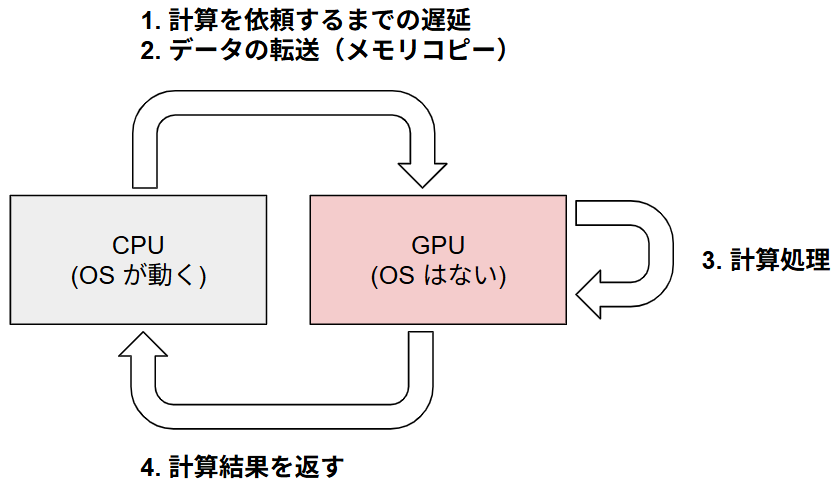
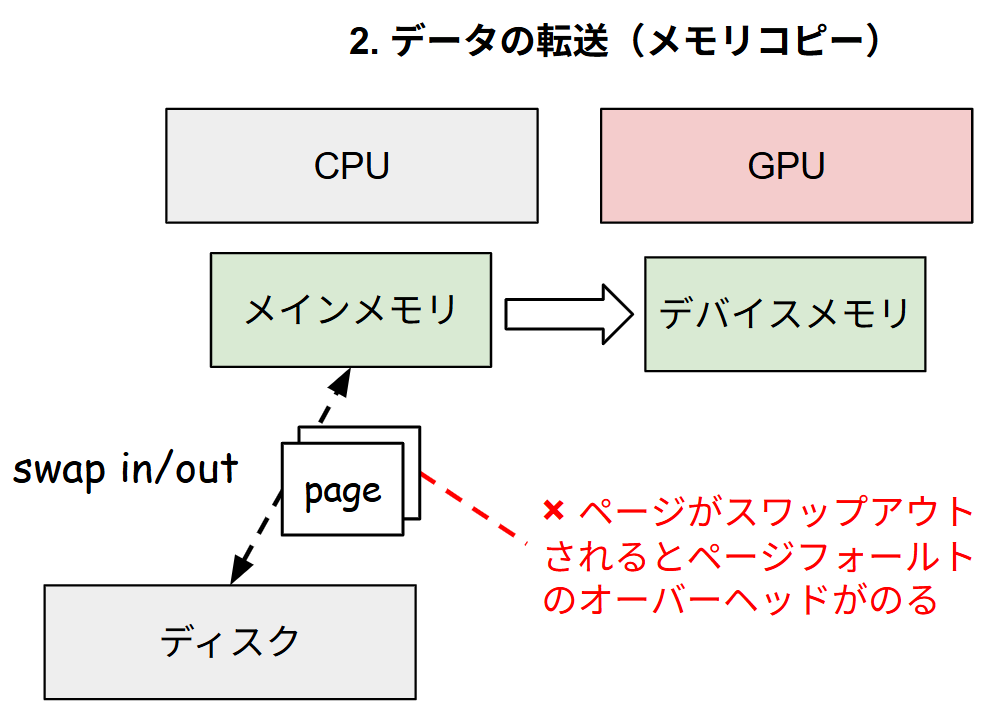
今回指摘する 2 つのボトルネックは、CPU 処理に時間を要してしまうことによる律速作用によって、GPU は次の計算を開始できずに待機してしまうことが GPU をアイドルにさせてしまう最大の原因であることが分かりました。それぞれの具体的なボトルネックについて紹介する前に、GPU 計算で発生し得るオーバーヘッドについて簡単に解説します。GPU 計算で発生するオーバーヘッドはおおまかに以下の4種類に分類されます。計算処理は OS が動作する CPU から始まり、CPU から計算処理を依頼される形で GPU の計算が開始されます。CPU と GPU は独立に動作するため、GPU を常に利用するためには CPU から継続的に計算処理が依頼される必要があります。もし、学習時の各イテレーションにおいて CPU 処理に時間がかかってしまうと、処理依頼待ちで GPU のアイドル時間が増大してしまいます。そのほか、計算処理以外にも、CPU と GPU のメモリは物理的に独立であることに起因するメモリコピーのオーバーヘッドや、計算処理を返すための遅延などが発生します。
ボトルネック1. データ供給の遅延
タイムラインの順伝播が始まる前の部分に注目すると、DataLoader 関連の CPU 処理に多くの時間が費やされていることが分かります。ディスクからの画像読み込み、デコード、そしてリサイズや反転といったデータ拡張処理が CPU で行われている間、GPU は次の処理を待機してしまっていることが利用率低下につながっています。これは先程の図中における『1. CPUでの処理』が律速しているケースに該当します。

ボトルネック2. Python の逐次実行によるオーバーヘッド
タイムラインの forward ブロックに注目すると、UNet2DConditionModel パスが、nn.Module:CrossAttnDownBlock2D_… や nn.Module:ResnetBlock2D_…といった、非常に小さな処理ブロックに細分化されていることが分かります。forward メソッド内の各サブモジュールを呼び出すたびに、Pythonインタープリタが介在し、命令を出すために CPU-GPU 間での通信が幾多にも発生してしまうことで GPU の待機時間が増大してしまいます。これもボトルネック1と同様に、先程の図中における『1. CPUでの処理』が律速しているケースに該当します。
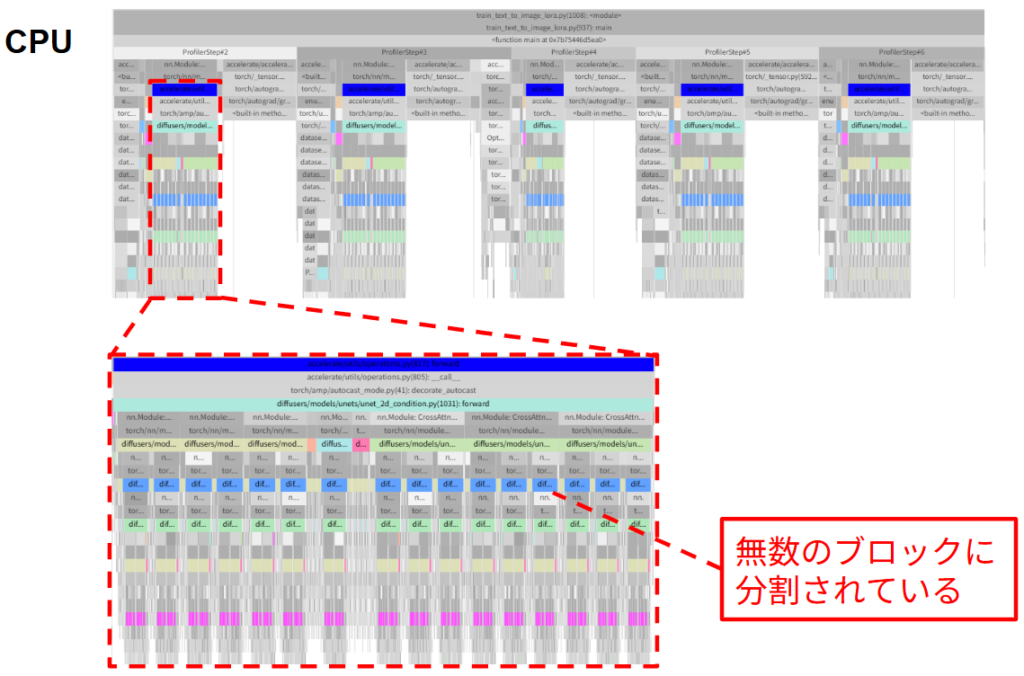
性能改善のアプローチおよび評価
データ供給遅延の改善
データ供給の遅延を解消するため、DataLoader の dataloader_num_workers を増やし、データ前処理をマルチプロセス化する実験を行いました。データ前処理を複数プロセスで短時間に実行することで、GPU の命令待ち時間が軽減されることが期待できます。ワーカー数を 0, 1, 2, 3, 4, 8, 12 と変化させ、学習 1 ステップあたりの平均の実行時間を計測しました。デフォルトのワーカー数は 0 であり、これは DataLoader 処理を main スレッドがそのまま処理することを意味します。
TRAIN_COMMAND = accelerate launch train_text_to_image_lora.py \
--pretrained_model_name_or_path="runwayml/stable-diffusion-v1-5" \
--dataset_name="lambdalabs/naruto-blip-captions" \
+++ --dataloader_num_workers=$(NUM_WORKERS)
実験結果は以下の通りです。
num_workers | 実行時間 (ms) |
|---|---|
| 0 | 290 |
| 1 | 156 |
| 2 | 144 |
| 3 | 141 |
| 4 | 148 |
| 8 | 178 |
| 12 | エラー |
この結果から、ワーカー数は多ければ多いほど良いわけではなく、num_workers=3 が最適値であることが分かりました。ワーカー数を増やしすぎると、CPU やメモリなどのリソース競合、あるいはプロセス間通信のオーバーヘッドが大きくなり、かえって性能が低下することが分かりました。また、num_workers=12 ではコンテナの共有メモリ不足でエラーが発生しました。これは Docker コンテナのデフォルトの共有メモリ(/dev/shm)が 64MB など非常に小さく設定されていることが原因です。今回の実験では、実行時間が増加傾向にあったため、num_workers=12 の場合の実行時間については深く追求しませんでしたが、実行時に docker run --shm-size=1g のようにオプションを指定することでエラーを回避することができます。この最適化により、平均の GPU 使用率は 44% から最大で 65% 程度まで向上しました。下図に示すとおり、num_workers の設定によって DataLoader 関連の処理にかかる時間 90% 程度削減されることが確認されました。
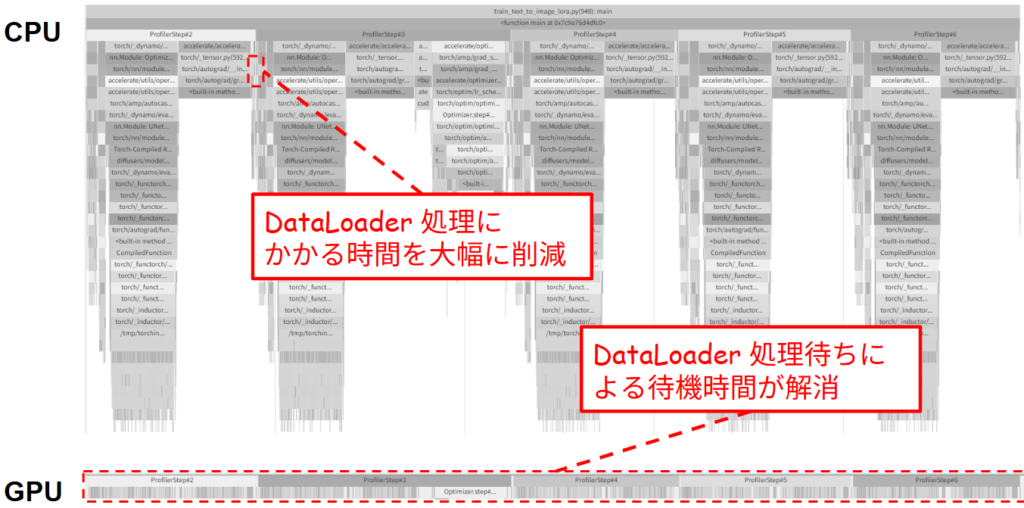
Python の逐次実行によるオーバーヘッドの改善
Python の逐次実行によるオーバーヘッドを改善するため、PyTorch 2.x の機能である torch.compile を導入しました。unet = torch.compile(unet) の一行をコードに追加し、dataloader_num_workers=3 の最適な設定で再度実験しました。torch.compile におけるモードには、デフォルト値 mode="default" を採用しています
通常 torch.compile のオプションとしては mode="reduce-overhead" や mode="max-autotune" なども利用されますが、今回の実行条件の場合 gradient_accumulation_steps > 1 であり静的なグラフを前提としている一方で、accelerator.accumulate ブロックが内部で分岐を発生させ、勾配を累積するだけのステップと optimizer.step() を実行するステップで計算グラフの構造が動的に変化することで RuntimeError が発生したため、今回これらのオプションは利用しないこととしています。
unet = UNet2DConditionModel.from_pretrained(
args.pretrained_model_name_or_path, subfolder="unet", revision=args.revision, variant=args.variant
)
+++ unet = torch.compile(unet)
その結果、実行時間は 141ms から 102ms へ と大幅に削減されました。これは、torch.compile が計算グラフを JIT コンパイルし、複数の小さなカーネルを一つの大きな最適化されたカーネルに自動で統合してくれたためです。プロファイル結果でも、forward ブロックが Torch-Compiled Region という一つの大きなブロックに変化していることが確認できました。
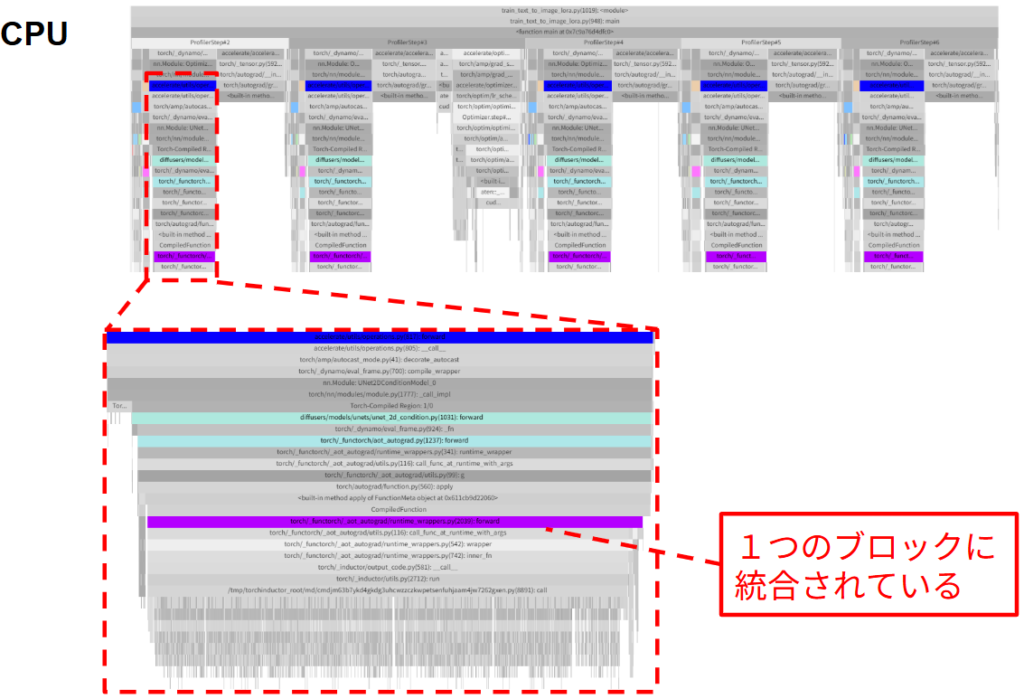
データ転送に関するその他の最適化
以上のほかにも、データ転送に関する部分について細かな最適化を加えました。それが、これから紹介する DataLoader が利用するメモリ領域の pinning とメモリコピーの非同期化です。変更としては、まず DataLoader の宣言時に pin_memory オプションを True にします(DataLoader では pin_memory=False がデフォルトです)。
train_dataloader = torch.utils.data.DataLoader(
train_dataset,
shuffle=True,
collate_fn=collate_fn,
batch_size=args.train_batch_size,
num_workers=args.dataloader_num_workers,
+++ pin_memory=True,
)
前の節で、GPU 計算で発生するオーバーヘッドの種類について軽く言及しましたが、今回の変更は「2. データの転送(メモリコピー)」部分の高速化に相当します。CPU と GPU は独立したメモリを有しているため、計算処理を実行する前にメインメモリから GPU のデバイスメモリ上にデータをコピーする必要がありますが、この学習に使用しているページが OS によってスワップアウトされないように pinning するのがこのオプションの役割です。
この pin_memory=True の設定と組み合わせて、CPU メモリにおけるデータを GPU のデバイスメモリ上に転送する際に利用する to() メソッドの引数に non_blocking=True という引数を追加することで初めて、非同期に処理が実行可能になります。あらかじめ学習に必要なページをメモリ上に固定しておくことで、ページがスワップアウトされる可能性を排除し、GPU がメモリの転送作業を行っている最中に CPU が先の命令を実行できます。実装としては、以下のような変更を加えました。
for epoch in range(first_epoch, args.num_train_epochs):
unet.train()
train_loss = 0.0
for step, batch in enumerate(train_dataloader):
+++ pixel_values = batch["pixel_values"].to(accelerator.device, non_blocking=True, dtype=weight_dtype)
+++ input_ids = batch["input_ids"].to(accelerator.device, non_blocking=True)
with accelerator.accumulate(unet):
# Convert images to latent space
--- latents = vae.encode(batch["pixel_values"].to(dtype=weight_dtype)).latent_dist.sample()
+++ latents = vae.encode(pixel_values).latent_dist.sample()
...
# Get the text embedding for conditioning
--- encoder_hidden_states = text_encoder(batch["input_ids"], return_dict=False)[0]
+++ encoder_hidden_states = text_encoder(input_ids, return_dict=False)[0]
上記の最適化を加えたところ、各学習ステップにおける実行時間は 102ms から 98ms まで削減されました。今までの最適化に比べると効果が薄いですが、4% 程度の高速化が達成できました。
最終的な最適化結果
以上の最適化を適用した結果、最終的に性能は以下のように改善しました。体系的なボトルネックの特定と、それぞれの原因に合わせた最適化によって、学習のステップ時間が約 2.96 倍高速化・GPU 使用率が約 1.93 倍向上したことが確認できました。
| 指標 | 初期状態 | 最適化後 | 改善率 |
|---|---|---|---|
| ステップ時間 | 290 ms | 98 ms | 約 2.96 倍改善 |
| GPU 使用率 | 44 % | 85 % | 約 1.93 倍改善 |
さらなる最適化の余地について
使い切れていない残り 15% の GPU 使用率についても、最適化の余地がある箇所を何点か紹介します。
まず1つ目が、勾配情報の同期的な処理です。backward 処理と optimizer による処理の間に GPU が短くアイドルになっている個所が見つかりました。ここでは、CPU で accelerate/accelerator.py: clip_grad_norm_ という処理が実行されています。ここでは勾配の大きさが一定の大きさを超えている場合にスケーリングを行う処理が実行されますが、こちらは CPU が勾配の大きさを計算するまでの間、GPU がスケーリング処理を行えず律速してしまう同期的な処理であるためにアイドルとなってしまうことが原因です。
2つ目は TensorBoard へのログ書き込みです。CPU で tensorboard/summary/writer.py: flush が実行されている間、GPU がアイドル状態になっていることが分かりました。accelerate は report_to="tensorboard" の設定に基づいて、TensorBoard の Writer にバッファ内のデータをディスクに書き込むことを依頼します。flushではデータが確実に保存されることを保証するために I/O 処理が完了するまで待機する同期的な処理するため、ここでも GPU 処理が律速されてしまいます。対策としては、TensorBoard へのログ書き込み頻度を減らすことなどが考えられます。
Blackwell アーキテクチャ特有の問題について
本節では、今回実験に用いた NVIDIA Blackwell [^13] アーキテクチャを利用するうえで直面した諸問題について共有します。Blackwell は NVIDIA が 2024 年に発表した最新の GPU アーキテクチャで、前世代の Hopper [^14] アーキテクチャなどの後継です。今回の実験環境では、このような最新アーキテクチャに対するソフトウェア側の対応という課題に直面することになりました。
PyTorch バージョンとの非互換性
当初、PyTorch の安定版ビルド(PyTorch 2.3.x)を使用したところ、以下のエラーが発生しました。
/opt/conda/lib/python3.10/site-packages/torch/cuda/__init__.py:209: UserWarning:
NVIDIA RTX PRO 6000 Blackwell Max-Q Workstation Edition with CUDA capability sm_120 is not compatible with the current PyTorch installation.
The current PyTorch install supports CUDA capabilities sm_50 sm_60 ... sm_90.
これは、安定版 PyTorch が、Blackwell の Compute Capability 12.0 (sm_120) にまだ対応していなかったことが原因です。Compute Capability とは、NVIDIA の CUDA プラットフォームにおいて GPU の機能やアーキテクチャのバージョンを指します。この問題を解決するため、より新しい開発版を使用する必要がありました。最終的に、Dockerfile でナイトリービルド用のインデックスを指定することで、ハードウェアを認識させることに成功しました。
RUN pip install --no-cache-dir --pre \
torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/nightly/cu121 \
xformers との非互換性
xformers [^15] は Meta (旧 Facebook) が開発した Transformer を効率的に実行するために最適化されたライブラリです。今回、一般的な高速化の手法である --enable_xformers_memory_efficient_attention [^16] を有効にすると、以下のエラーが発生することが分かりました。
NotImplementedError: No operator found for `memory_efficient_attention_forward` with inputs:
...
requires device with capability < (8, 0) but your GPU has capability (12, 0) (too new)
このエラーは xformers ライブラリが提供する最適化カーネルがまだ Blackwell アーキテクチャ (capability (12, 0)) に対応していなかったことを示します。最新環境では、xformers のような専用ライブラリが提供するメモリ効率の最大化や特定条件下での更なる高速化の恩恵は受けられないハードルがある場合があることが分かりました。
まとめ・感想
本記事では、最新 GPU である NVIDIA Blackwell 上で LoRA ファインチューニングを実行するというタスクを通じて、体系的なパフォーマンス分析と最適化のプロセスを詳解しました。単にコードを動かすだけでなく、PyTorch Profiler のようなツールを用いてボトルネックを特定し、num_workers の調整や torch.compile といった最適化を適用することで、GPU リソースを最大限に引き出し、学習速度を大幅に向上できることを示しました。また、最新ハードウェアを扱う上で避けられないライブラリの非互換性といった問題とその解決策も共有しました。この記録が、同じような環境を利用する開発者の一助となれば幸いです。
今回の作業の感想ですが、CPU に律速されてしまう点など GPU 特有の現象を踏まえた高速化が経験できた点がとても新鮮で楽しかったです。これまでの業務や研究活動では主に CPU に関連する部分のプロファイリングを行うことが多かったので、GPU という CPU とはまた異なる特徴を有したハードウェアを実作業を通じて勉強できた点はとても貴重な経験だったと思います。オペレーティングシステムだとシングルコアからマルチコアになることでタスクのスケジューリングが難しくなるように、大規模環境ではどのように大量の GPU を制御しているのかさらに興味がわきました。
なお本記事の執筆ならびに作業を進めるにあたり、ご指導いただいた二木さんにこの場を借りて心より感謝申し上げます。
最後に、Fixstars では、通年でインターンシップを募集しています。高専生、大学生、大学院生の皆さん、Fixstars で新しい技術に触れませんか? インターンシップの詳細は こちら をご覧ください。
参考
[^1] https://civitai.com/
[^2] https://arxiv.org/abs/2106.09685
[^3] https://huggingface.co/
[^4] https://github.com/AUTOMATIC1111/stable-diffusion-webui
[^5] https://github.com/bmaltais/kohya_ss
[^6] https://github.com/XuehaiPan/nvitop
[^7] https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image_lora.py
[^8] https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5
[^9] https://huggingface.co/datasets/lambdalabs/naruto-blip-captions
[^10] https://pytorch.org/tutorials/intermediate/tensorboard_profiler_tutorial.html
[^11] https://www.tensorflow.org/tensorboard?hl=ja
[^12] https://github.com/brendangregg/FlameGraph
[^13] https://www.nvidia.com/ja-jp/data-center/technologies/blackwell-architecture/
[^14] https://www.nvidia.com/ja-jp/data-center/technologies/hopper-architecture/
[^15] https://github.com/facebookresearch/xformers
[^16] https://huggingface.co/docs/diffusers/v0.35.1/en/api/models/overview#diffusers.ModelMixin.enable_xformers_memory_efficient_attention

Tags
About Author
daiki.wakabayashi
Leave a Comment
Tags
Favorite Post

 2023年1月27日
2023年1月27日 2017年8月22日
2017年8月22日
Archives
- 2026年2月
- 2026年1月
- 2025年12月
- 2025年11月
- 2025年8月
- 2025年5月
- 2025年4月
- 2024年11月
- 2024年10月
- 2024年7月
- 2024年5月
- 2024年4月
- 2024年2月
- 2024年1月
- 2023年12月
- 2023年6月
- 2023年5月
- 2023年4月
- 2023年2月
- 2023年1月
- 2022年12月
- 2022年10月
- 2021年11月
- 2021年9月
- 2021年6月
- 2021年3月
- 2021年2月
- 2020年12月
- 2020年10月
- 2020年7月
- 2020年6月
- 2020年5月
- 2020年4月
- 2020年3月
- 2020年2月
- 2020年1月
- 2019年12月
- 2019年11月
- 2019年10月
- 2019年9月
- 2019年8月
- 2019年6月
- 2019年4月
- 2019年3月
- 2019年2月
- 2019年1月
- 2018年12月
- 2018年11月
- 2018年10月
- 2018年8月
- 2018年6月
- 2018年5月
- 2018年4月
- 2018年3月
- 2018年2月
- 2017年12月
- 2017年11月
- 2017年10月
- 2017年9月
- 2017年8月
- 2017年7月
- 2017年6月
- 2017年5月
- 2017年3月
- 2016年12月
- 2016年11月
- 2016年8月
- 2016年7月
- 2016年3月
- 2016年2月
- 2016年1月
- 2015年12月
- 2015年11月
- 2015年10月
- 2015年8月
- 2015年6月
- 2015年3月
- 2015年2月
- 2015年1月
- 2014年12月
- 2014年11月
keisuke.kimura in Livox Mid-360をROS1/ROS2で動かしてみた
Sorry for the delay in replying. I have done SLAM (FAST_LIO) with Livox MID360, but for various reasons I have not be...
Miya in ウエハースケールエンジン向けSimulated Annealingを複数タイルによる並列化で実装しました
作成されたプロファイラがとても良さそうです :) ぜひ詳細を書いていただきたいです!...
Deivaprakash in Livox Mid-360をROS1/ROS2で動かしてみた
Hey guys myself deiva from India currently i am working in this Livox MID360 and eager to knwo whether you have done the...
岩崎システム設計 岩崎 満 in Alveo U50で10G Ethernetを試してみる
仕事の都合で、検索を行い、御社サイトにたどりつきました。 内容は大変参考になりま�...
Prabuddhi Wariyapperuma in Livox Mid-360をROS1/ROS2で動かしてみた
This issue was sorted....