このブログは、株式会社フィックスターズのエンジニアが、あらゆるテーマについて自由に書いているブログです。
NVIDIA RTX PRO 6000 Blackwell Max-Q はどのようなGPUなのか?
はじめに
こんにちは。 エンジニアの廣岡です。
「NVIDIA RTX PRO 6000 Blackwell Max-Q Workstation Edition」(以降、6000 Blackwell Max-Q)が発売され、入手できました。

今回から数回に分けて、6000 Blackwell Max-Qの性能について解説していきます。 初回は、NVIDIAのデータシートをもとに、その特徴と性能を、ハイエンドGPUであるNVIDIA H100 PCIe(以下、H100 PCIe)と比較しながらご紹介します。
なお、記事の末尾には、今回主に比較するH100 PCIeに加え、参考としてNVIDIA GeForce RTX 5090、NVIDIA RTX 6000 Adaのスペックもまとめた総合比較表を掲載しています。
要約
6000 Blackwell Max-Qは、2025年3月のGTCで発表された、Blackwellアーキテクチャを採用した最新のワークステーション向けGPUです。 BlackwellアーキテクチャのGPUには以下の種類があります:
- GeForce RTX 50 シリーズ
- Blackwell RTX PROシリーズ
- HPC向けのシリーズ:GB200、B200、B100
本機は、Blackwell RTX PROシリーズのうち、消費電力を抑えたワークステーション向けのモデルであり、兄弟機種である6000 Blackwell Workstation Edition (600 W) に対し、300Wの消費電力を実現しています。
以降はその性能について、以下の順で確認します:
- 理論演算性能
- GPUの演算ユニットの中核である「Streaming Multiprocessor (SM)」の違い
- チップ全体での違い
- GPUメモリ
- 電力効率
理論演算性能比較
6000 Blackwell Max-Qの立ち位置を理解するため、その理論演算性能をH100 PCIeと比較します。
| 6000 Blackwell Max-Q | H100 PCIe | |
|---|---|---|
| アーキテクチャ | Blackwell (GB202) | Hopper (GH100) |
| FP64演算性能 (TFLOPS) | 1.71 | 25.6 |
| FP32演算性能 (TFLOPS) | 109.7 | 51.2 |
| INT32演算性能 (TOPS) | 109.7 | 25.6 |
| TF32演算性能 (TFLOPS) | 438.9 | 756 |
| INT8演算性能 (TOPS) | 1755.7 | 3026 |
| FP8演算性能 (FP16 Accumulate) (TFLOPS) | 1755.7 | 3026 |
| FP8演算性能 (FP32 Accumulate) (TFLOPS) | 1755.7 | 3026 |
| FP4演算性能 (FP32 Accumulate) (TFLOPS) | 3511.4 | N/A |
| RTコア演算性能 (TFLOPS) | 332.6 | N/A |
まずアーキテクチャですが、冒頭でも書いた通り、6000 Blackwell Max-Q は新世代アーキテクチャ「Blackwell」を採用したGPUです。 一方、H100 PCIeはひとつ前のアーキテクチャ「Hopper」となっています。 Blackwell世代で、SM内の演算器の構成、演算器の世代の違い、メモリ性能に変化がありました。 後程、詳細を確認します。
次にFP64演算性能は、6000 Blackwell Max-Qに対しH100 PCIeは約15倍の性能です。 FP64を多用する科学技術計算において、H100 PCIeのほうが適しているでしょう。
FP64演算性能と一転して、6000 Blackwell Max-QのFP32演算性能はH100 PCIeに対し2倍の性能です。 このFP32演算性能は、アーキテクチャの世代差よりも、後述するCUDAコア数の違いが主な要因と考えられます。
機械学習モデルの学習・推論で主に用いられるINT8/FP8/TF32の演算性能は、H100 PCIeのほうが約1.7倍高いです。 機械学習用途で高い演算性能が必要ならば、H100 PCIeのほうが適していると考えられます。
FP4演算性能は、6000 Blackwell Max-Qのみ値を掲載しました。 これは、FP4演算がBlackwellアーキテクチャで初めてハードウェアサポートされたためです。 現状はFP4を用いた機械学習モデル等の処理は少ないですが、今後FP4が必要になる場面が増えると予想されます。 6000 Blackwell Max-Qはそのような際に性能を発揮できると考えられます。
また、映像出力機能がないH100 PCIeにRTコアは存在しません。 したがって、RTコア性能においても6000 Blackwell Max-Qでのみ表に記載しています。
コストパフォーマンスを比較するため、各GPUの理論演算性能を価格で割り、1万円あたりの性能を算出しました H100 PCIeは470万円(AKIBA PC Hotline!編集部 2023b)とし、6000 Blackwell Max-Qを160万円(AKIBA PC Hotline!編集部 2023a)と設定しました。
| 6000 Blackwell Max-Q | H100 PCIe | |
|---|---|---|
| アーキテクチャ | Blackwell (GB202) | Hopper (GH100) |
| FP64演算性能 (TFLOPS) | 0.0107 | 0.0545 |
| FP32演算性能 (TFLOPS) | 0.686 | 0.109 |
| INT32演算性能 (TOPS) | 0.686 | 0.0545 |
| TF32演算性能 (TFLOPS) | 2.74 | 1.61 |
| INT8演算性能 (TOPS) | 11.0 | 6.44 |
| FP8演算性能 (FP16 Accumulate) (TFLOPS) | 11.0 | 6.44 |
| FP8演算性能 (FP32 Accumulate) (TFLOPS) | 11.0 | 6.44 |
| FP4演算性能 (TFLOPS) | 21.9 | N/A |
| RTコア演算性能 (TFLOPS) | 2.08 | N/A |
6000 Blackwell Max-QのFP64演算性能は、H100 PCIeに対して1万円当たり約5分の1の性能です。 この違いは、2つのGPUのFP64の演算器数が異なることに起因します。 この価格当たりの性能やハードウェアの演算器数を見ると、FP64を多用する処理、高い精度が必要な科学技術計算ではH100 PCIeがコストパフォーマンスの面でも適しているでしょう。
FP32演算性能については、6000 Blackwell Max-QはH100 PCIeに対して1万円あたり6倍の性能です。 FP32演算性能は6000 Blackwell Max-Qのコスパが良く、また理論性能が高くなっています。
機械学習モデルの学習・推論で用いられるTF32/INT8/FP8は、6000 Blackwell Max-QはH100 PCIeに対して1万円当たり1.5倍以上の性能です。 絶対的な演算性能ではH100 PCIeが優れていますが、6000 Blackwell Max-Qはコストパフォーマンスで勝ります。 したがって、コストを重視する場合は6000 Blackwell Max-Q、最高の演算能力を求める場合はH100 PCIeが適していると言えるでしょう。
ハードウェアの比較
ここからは、理論演算性能の差が、どのようなハードウェア仕様の違いから生じるのかを比較します。 比較するポイントは次の点です:
- SM単体での性能
- チップ全体での変化
- メモリ性能
- 電力効率
新設計のStreaming Multiprocessor
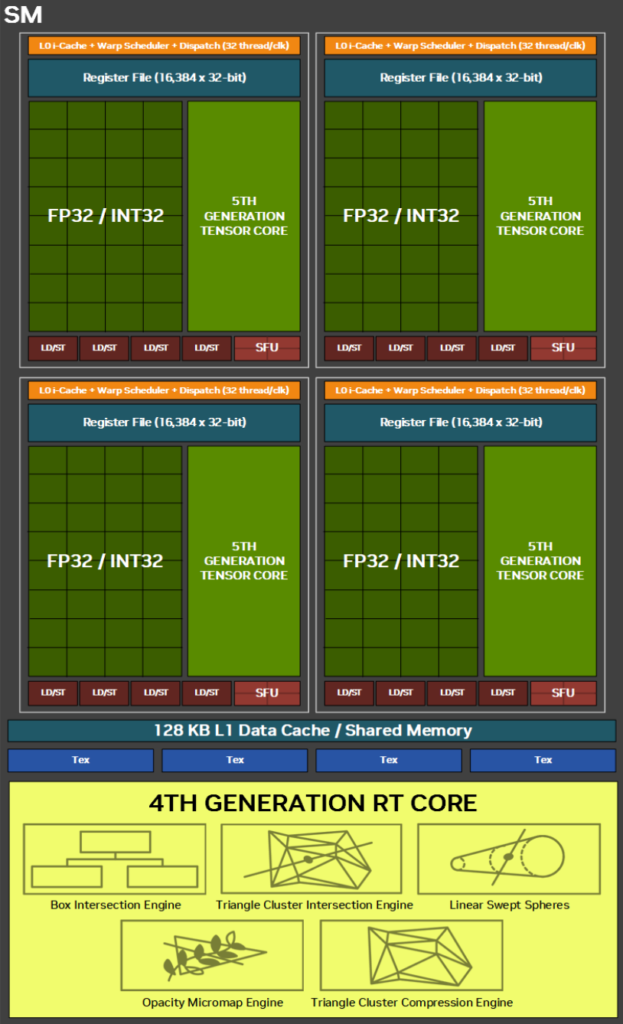
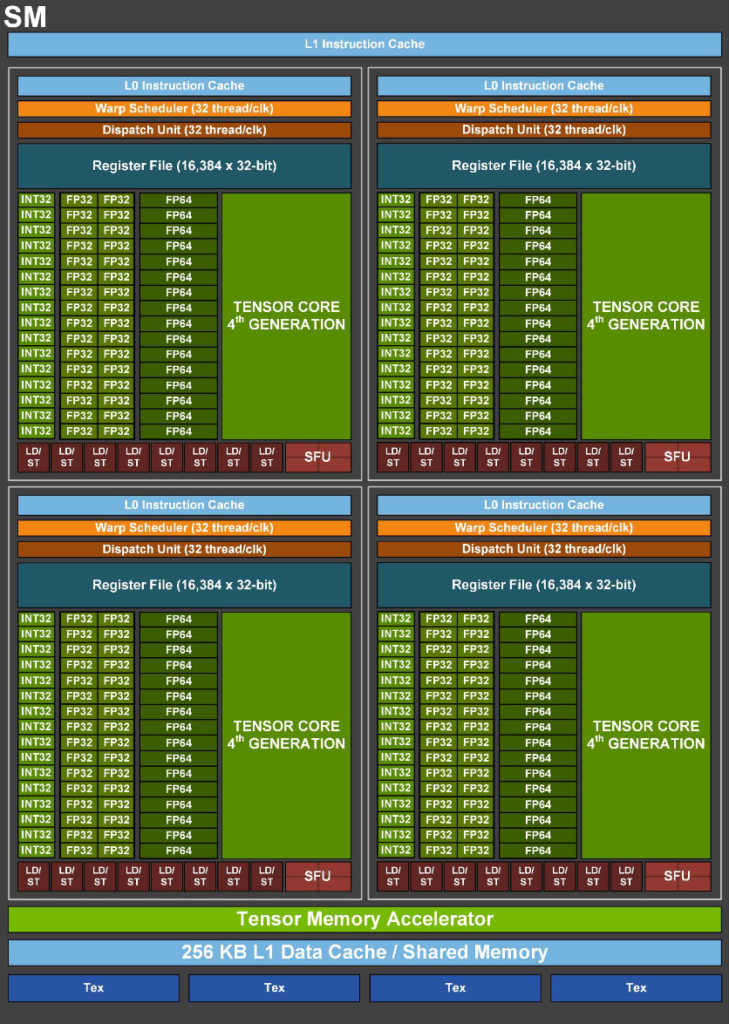
| 6000 Blackwell Max-Q | H100 PCIe | |
|---|---|---|
| CUDAコア数 / SM | 128 | 128 |
| FP32コア数 / SM | 128 | 128 |
| FP64コア数 / SM | 2 | 64 |
| INT32コア数 / SM | 128 | 64 |
アーキテクチャがBlackwellとなり、6000 Blackwell Max-QはSMの内部構造も刷新されました。
INT32/FP32コアの統一
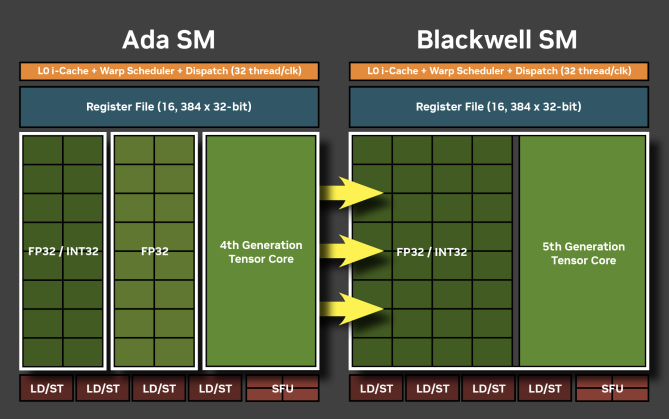
大きなポイントの一つは、INT32演算を行うコアの変化です。 Ada LovelaceやHopperの世代までは、INT32演算は一部のコアで処理されていました。 一方Blackwellでは、すべてのコアがFP32とINT32の両方の演算を実行できます。 これにより、6000 Blackwell Max-QはINT32の性能が大幅に向上し、INT32を多用する処理はもちろん、INT32とFP32が混在する処理に対して効果があると考えられます。 ただし、1つのコアがFP32とINT32の演算を同時に実行できるわけではありません。 したがって、FP32/INT32が複雑に混在する処理であっても、各コア内のパイプラインを埋められる程度にはINT32とFP32の命令がなければ最大性能を引き出すことができないと予想されます。
SM当たりの命令スループット
ここからは、NVIDIAが出している命令スループット表(NVIDIA 2025a)を参照しながら、SMの演算性能についてより掘り下げます。
| Compute Capability | 6000 Blackwell Max-Q | H100 PCIe |
|---|---|---|
| FP64 足し算/掛け算/積和命令 | 2 | 64 |
| FP32 足し算/掛け算/積和命令 | 128 | 128 |
| INT32 足し算/引き算/掛け算/積和 | 128 | 128 |
| INT32 比較/Min/Max命令 | 128 | 64 |
| INT64 足し算命令 | 64 | 32 |
| warp vote | 128 | 64 |
上記表は、CUDA 13.0.0の資料を参照し、表の各Compute Capability(CC)をもとに各GPUの命令スループットを出しています。 H100 PCIeはCC9.0、6000 Blackwell Max-QはCC12.0です。 なお、別バージョンのCUDAのドキュメントでは値が異なります。
先ほど述べた通り、6000 Blackwell Max-Qでは、INT32とFP32の演算器が共通化されました。 実際に命令スループットを参照すると、FP32、INT32の演算は同じスループットを示しています。 H100 PCIeと比較すると、6000 Blackwell Max-QはINT32の比較/Min/Max命令のスループットが高くなっています。 また、H100 PCIeと6000 Blackwell Max-QのINT32足し算のスループットは同じですが、CUDAのアセンブリ言語であるSASSレベルの改善により、実際には6000 Blackwell Max-QのほうがよりINT32のスループットが出しやすくなっています。(NVIDIA 2025b) このほかの引き算/掛け算/積和についてもBlackwell世代で改善が加えられ、実性能は大きく異なる可能性があります。
FP32命令のスループットはH100 PCIeと6000 Blackwell Max-Qは128で同じです。 これらGPUのFP32演算性能は異なりますが、この差はSMの差ではないことが分かります。
6000 Blackwell Max-QではINT64の足し算の命令スループットが上がっています。 これは、INT32演算器が増えた影響と考えられます。
ほかにスループットが向上している命令としては、warp vote命令があります。 この命令は、warp(32スレッドのグループ)内で、ある条件を満たすスレッドが一つでも存在するか(any)や、全てのスレッドが満たすか(all)などを高速に判定する命令群です。
一方で、科学技術計算で重要なFP64演算では、6000 Blackwell Max-QのSM当たりの命令のスループットは低くなっています。 H100 PCIeが64であるのに対して6000 Blackwell Max-Qは2となっていることから、この値はSM内にあるFP64演算器の個数を反映した値だと考えられます。
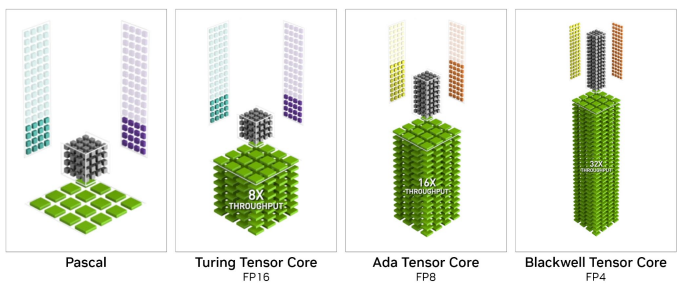
第5世代Tensorコア:AI推論を高速化
| 6000 Blackwell Max-Q | H100 PCIe | |
|---|---|---|
| Tensorコア数 / SM | 4 (5th Gen) | 4 (4th Gen) |
Blackwell世代の大きな特徴の1つは、第5世代へと進化したTensorコアにあります。 第4世代TensorコアではサポートされていなかったFP4とFP6が、ハードウェアレベルで新たにサポートされました。 また、Transformer Engineは、第2世代へと更新されています。
チップ全体での変化
次にSMではなくチップ全体での比較を行います。
| 6000 Blackwell Max-Q | H100 PCIe | |
|---|---|---|
| NVIDIA CUDAコア数 | 24,064 | 14,592 |
| GPC数 | 12 | 7 or 8 |
| TPC数 | 94 | 57 |
| SM数 | 188 | 114 |
| SM数 / GPCs | 15.7 | 16.3 |
| RTコア数 | 188 (4th Gen) | N/A |
| L1キャッシュ / SM (KB) | 128 | 256 |
| L2キャッシュ (MB) | 128 | 50 |
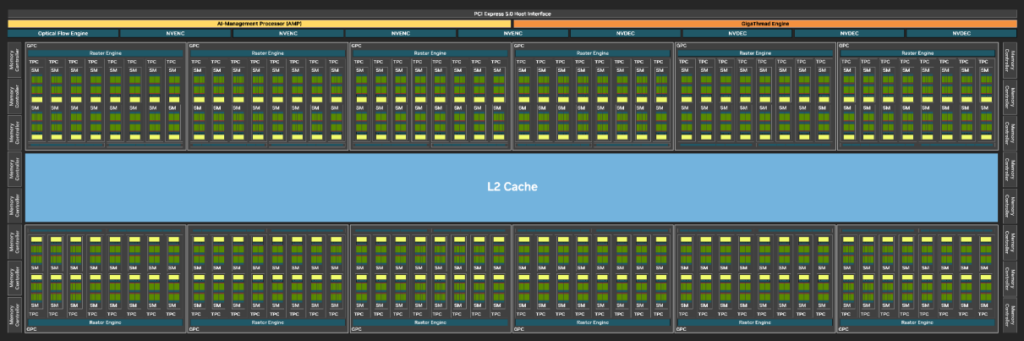
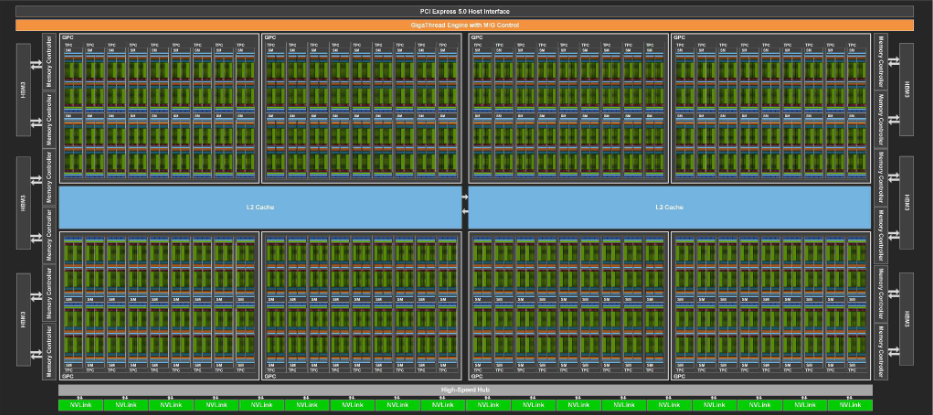
これらの図はそれぞれ6000 Blackwell Max-Q・H100 PCIeで使われているチップのフルサイズ (GB202、GH100) の模式図です。 実際の各GPU内のチップは、半導体製造での歩留まりにより、これらフルサイズのチップではなく一部のSMが無効化されている等の違いがあります。
まず、6000 Blackwell Max-Qのチップを見ると、H100 PCIeでは2分割されていたL2キャッシュが1つにまとめられています。 さらにL2キャッシュサイズはH100 PCIeの50 MBに対して、6000 Blackwell Max-Qは128 MBと大きくなっています。 L2キャッシュサイズの増加により、データがL2キャッシュ上に収まりやすくなります。 したがって、多くのメモリを使用する処理について有利だと考えられます。
また、SM数を見ると、6000 Blackwell Max-QはH100 PCIeと比べて数が多くなっています。 具体的に、H100 PCIeは114個となっているのに対して、6000 Blackwell Max-Qでは188個です。 SMの数が多いことは、細かい処理が多い際にスレッドブロックのスケジューリングで有利になると考えられます。
また、SMの数が多いと演算器の数が増えます。 2GPU間のFP32演算性能差は、このSM数の差によるものと考えられます。
96GBの大容量GDDR7メモリ
| 6000 Blackwell Max-Q | H100 PCIe | |
|---|---|---|
| GPUメモリ | 96 GB GDDR7 | 80 GB HBM2e |
| メモリインターフェース (bit) | 512 | 5120 |
| メモリデータレート (Gbps) | 28 | 3.19 |
| メモリ帯域幅 (GB/sec) | 1792 | 2039 |
| PCIe規格 | Gen 5 | Gen 5 |
Blackwellアーキテクチャへの進化における大きな変更点の1つとして、メモリが挙げられます
メモリ容量では、6000 Blackwell Max-Qはワークステーション向けGPUでありながら96GBある点が大きな特徴です。 これはH100 PCIeの80GBを上回ります。 メモリを大量に消費するタスクや、大規模な機械学習モデルを扱うタスクで大きな効果を発揮するでしょう。
6000 Blackwell Max-Qでは、新規格の「GDDR7」メモリを採用しています。 同じGDDRを使用した前世代のRTX 6000 Ada (960 GB/sec) と比較して、メモリ帯域が1792 GB/secへ大幅に増加しています。 一方で、H100 PCIeはHBM2eと呼ばれる規格を採用しています。 HBM2eはバス幅を大きくすることでメモリ帯域を確保しているメモリですが、GDDRに比べ製造が難しく高価です。 それと比較してもH100 PCIe (2039 GB/sec) に迫る1792 GB/secという広大な帯域幅を実現している点も特徴として挙げられます。
以上のことから、大量のメモリを多用する処理で6000 Blackwell Max-Qは適したハードウェアとなっていると考えられます。
電力効率
| 6000 Blackwell Max-Q | H100 PCIe | |
|---|---|---|
| 消費電力 | 300 W | 350 W |
6000 Blackwell Max-Qの特徴として、ワークステーション向けの優れた電力効率があげられます。 まずその消費電力は、H100 PCIeと比べて350 Wに対して300 Wであり、低く抑えられています。
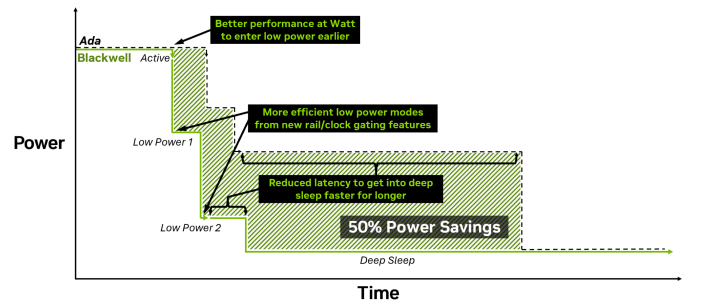
さらに、Max-Qという名前がついている通り、Max-Qテクノロジを用いています。 Max-Qテクノロジの特徴は、より細かい時間、チップ上の単位で消費電力を調整でき、より迅速に低消費電力の状態に移行できる点です。 また、新しいクロックゲーティングによってより細かい単位、時間でクロック数を調整できます。 特にBlackwellで採用されたGDDR7の高速起動・クロックアーキテクチャを用いて、メモリに関しても電力管理機能が向上しています。 電圧線も新しく引かれており、よりチップの細かい単位で電圧を調整することができます。 これらの点で、6000 Blackwell Max-Qはオンデマンド処理向けに電力効率が最適化されていると考えられます。
終わりに
今回は、データシートを基に6000 Blackwell Max-Qの性能をまとめました。 今後の記事では、実際に動かしてみてその性能を確かめますので、ぜひご期待ください。
性能比較表
| 6000 Blackwell Max-Q | H100 PCIe | RTX 5090 | RTX 6000 Ada | |
|---|---|---|---|---|
| アーキテクチャ | Blackwell (GB202) | Hopper (GH100) | Blackwell (GB202) | Ada Lovelace (AD102) |
| FP64演算性能 (TFLOPS) | 1.71 | 25.6 | 1.64 | 1.42 |
| FP32演算性能 (TFLOPS) | 109.7 | 51.2 | 104.8 | 91.1 |
| INT32演算性能 (TOPS) | 109.7 | 25.6 | 104.8 | 44.5 |
| TF32演算性能 (TFLOPS) | 438.9 | 756 | 209.5 | 364.2 |
| INT8演算性能 (TOPS) | 1755.7 | 3026 | 1676 | 1457 |
| FP8演算性能 (FP16 Accumulate) (TFLOPS) | 1755.7 | 3026 | 838 | 1457 |
| FP8演算性能 (FP32 Accumulate) (TFLOPS) | 1755.7 | 3026 | 838 | 1457 |
| FP4演算性能 (FP32 Accumulate) (TFLOPS) | 3511.4 | N/A | 3352 | N/A |
| RTコア演算性能 (TFLOPS) | 332.6 | N/A | 317.5 | 210.6 |
| NVIDIA CUDAコア数 | 24,064 | 14,592 | 21,760 | 18,176 |
| GPC数 | 12 | 7 or 8 | 11 | 12 |
| TPC数 | 94 | 57 | 85 | 71 |
| SM数 | 188 | 114 | 170 | 142 |
| RTコア数 | 188 (4th Gen) | N/A | 170 (4th Gen) | 142 (3rd Gen) |
| CUDAコア数 / SM | 128 | 128 | 128 | 128 |
| FP32コア数 / SM | 128 | 128 | 128 | 128 |
| FP64コア数 / SM | 2 | 64 | 2 | 2 |
| INT32コア数 / SM | 128 | 64 | 128 | 64 |
| Tensorコア数 / SM | 4 (5th Gen) | 4 (4th Gen) | 4 (5th Gen) | 4 (4th Gen) |
| GPUメモリ | 96 GB GDDR7 | 80 GB HBM2e | 32 GB GDDR7 | 48 GB GDDR6 |
| メモリインターフェース (bit) | 512 | 5120 | 512 | 384 |
| メモリデータレート (Gbps) | 28 | 3.19 | 28 | 20 |
| メモリ帯域幅 (GB/sec) | 1792 | 2039 | 1792 | 960 |
| L1キャッシュ / SM (KB) | 128 | 256 | 128 | 128 |
| L2キャッシュ (MB) | 128 | 50 | 96 | 96 |
| PCIe規格 | Gen 5 | Gen 5 | Gen 5 | Gen 4 |
| 消費電力 (W) | 300 | 350 | 575 | 300 |
参考資料

Tags
About Author
satoshi.hirooka
Leave a Comment
Tags
Favorite Post

 2023年1月27日
2023年1月27日 2017年8月22日
2017年8月22日
Archives
- 2026年2月
- 2026年1月
- 2025年12月
- 2025年11月
- 2025年8月
- 2025年5月
- 2025年4月
- 2024年11月
- 2024年10月
- 2024年7月
- 2024年5月
- 2024年4月
- 2024年2月
- 2024年1月
- 2023年12月
- 2023年6月
- 2023年5月
- 2023年4月
- 2023年2月
- 2023年1月
- 2022年12月
- 2022年10月
- 2021年11月
- 2021年9月
- 2021年6月
- 2021年3月
- 2021年2月
- 2020年12月
- 2020年10月
- 2020年7月
- 2020年6月
- 2020年5月
- 2020年4月
- 2020年3月
- 2020年2月
- 2020年1月
- 2019年12月
- 2019年11月
- 2019年10月
- 2019年9月
- 2019年8月
- 2019年6月
- 2019年4月
- 2019年3月
- 2019年2月
- 2019年1月
- 2018年12月
- 2018年11月
- 2018年10月
- 2018年8月
- 2018年6月
- 2018年5月
- 2018年4月
- 2018年3月
- 2018年2月
- 2017年12月
- 2017年11月
- 2017年10月
- 2017年9月
- 2017年8月
- 2017年7月
- 2017年6月
- 2017年5月
- 2017年3月
- 2016年12月
- 2016年11月
- 2016年8月
- 2016年7月
- 2016年3月
- 2016年2月
- 2016年1月
- 2015年12月
- 2015年11月
- 2015年10月
- 2015年8月
- 2015年6月
- 2015年3月
- 2015年2月
- 2015年1月
- 2014年12月
- 2014年11月
keisuke.kimura in Livox Mid-360をROS1/ROS2で動かしてみた
Sorry for the delay in replying. I have done SLAM (FAST_LIO) with Livox MID360, but for various reasons I have not be...
Miya in ウエハースケールエンジン向けSimulated Annealingを複数タイルによる並列化で実装しました
作成されたプロファイラがとても良さそうです :) ぜひ詳細を書いていただきたいです!...
Deivaprakash in Livox Mid-360をROS1/ROS2で動かしてみた
Hey guys myself deiva from India currently i am working in this Livox MID360 and eager to knwo whether you have done the...
岩崎システム設計 岩崎 満 in Alveo U50で10G Ethernetを試してみる
仕事の都合で、検索を行い、御社サイトにたどりつきました。 内容は大変参考になりま�...
Prabuddhi Wariyapperuma in Livox Mid-360をROS1/ROS2で動かしてみた
This issue was sorted....