このブログは、株式会社フィックスターズのエンジニアが、あらゆるテーマについて自由に書いているブログです。
3D Gaussian Splatting を用いた異常検知手法:Splat Pose & Detect の高速化
はじめに
アルバイトの星井です。
インターンシップの課題として、「3D Gaussian Splatting を用いた物体検出手法の調査と高速化」に取り組みました。 物体検出手法を調査したのち、3D Gaussian Splatting を用いた異常検知手法である Splat Pose & Detect: Pose-Agnostic 3D Anomaly Detection についての高速化を行い、約 6 倍の高速化に成功しました。
背景
3D Gaussian Splatting for Real-Time Radiance Field Rendering とは、2023 年に提案された手法です。Novel-view Synthesis(新規ビュー合成)のための訓練およびレンダリング(描画)を高速、高精細に行うことができます。 3D Gaussian Splatting の詳細については、別記事「3D Gaussian Splatting の紹介と高速化 」をご覧ください。
3D Gaussian Splatting は 2023 年に提案された手法ですが、今非常に盛んな研究分野で、数多くの関連研究がなされています。 数多くの関連研究のうち、物体検出手法について調査を行いました。
画像上で物体を分類・検出する手法としては AlexNet や、You Only Look Once をはじめとした数多くの研究がなされています。 3D Gaussian Splatting を用いた物体検出手法はこれらの手法を発展させて、3D モデル上で物体について検知を行います。 例えば、CLIP という画像とテキストを結びつける研究がありますが、これを利用して 3D モデル上の物体を言語により指定する手法 FastLGS が提案されています。
今回、インターンシップの課題として、物体検出手法の一種である異常検知手法である、Splat Pose & Detect: Pose-Agnostic 3D Anomaly Detection の高速化に取り組みました。 この手法についても、異常箇所を同定するために、画像上で物体を分類する手法である EfficientNet という画像分類ネットワークを利用しています。
Splat Pose & Detect
Splat Pose & Detect: Pose-Agnostic 3D Anomaly Detection とは、3D Gaussian Splatting を利用した異常検知を行う手法です。
問題設定
ある物体について、様々な方向から撮影された多くの画像(異常無)が存在します。
追加で、その物体を撮影した画像が 1 枚与えられます。 追加の画像に撮像されている物体は、異常を含んでいる可能性があります。
追加の画像について異常の有無、ある場合はその異常箇所について判定したいです。


手法解説:Gaussian Splatting を用いた3D異常検知の詳細な流れ
以下、ある物体に対して元々撮影した画像(異常無)を学習用画像、異常の有無と異常箇所を判定したい画像をクエリ画像と呼びます。 手法の流れについて説明します。
1. 3D Gaussian Splatting
まず、学習用画像を用いて、3D Gaussian Splatting により、下の図に示すような 3D モデルを作成します。

2. 位置姿勢推定
次に、3D モデルを用いてクエリ画像が撮影された位置姿勢を推定します。
初期位置姿勢推定
学習用画像とクエリ画像のマッチングを行い、クエリ画像と類似している学習用画像を探します。 最も類似している学習用画像の位置姿勢を、初期位置姿勢とします。 ここでは、類似度を計るために LoFTR という手法を用いています。
位置姿勢更新
初期位置姿勢から、クエリ画像が撮影された位置姿勢に近づくように、位置姿勢の更新を繰り返します。
3D Gaussian Splatting により作成した 3D モデルを用いることで、ある位置姿勢からモデルを見た場合の画像について得ることができます。 これを利用して、クエリ画像と類似度がより高くなるような画像が得られるような位置姿勢になるように更新を繰り返します。
類似度として、ここでは L1 ノルムと SSIM を組み合わせて用いています。 L1 ノルムと SSIM を組み合わせて損失を計算し、Adam により最適化を行っています。
3. 異常検知
最終的な位置姿勢から 3D モデルを見た画像をレンダリングします。 レンダリングした画像と、クエリ画像について比較を行います。 比較を行い、異なる場所があればその箇所を異常として見なします。
これらの比較のために、Pre-trained のネットワーク、EfficientNet を用います。

手法の問題点と改善策
以上の手続きで異常検知を行う手法、Splat Pose について、高速化を行いました。
実行環境は以下の通りです。
- CPU Intel Core i7-14700
- GPU NVIDIA GeForce RTX 4060
1. 初期位置姿勢推定
問題点
大きく、2つの問題点がありました。
誤マッチング
Splat Pose では、PAD というデータセットを用いています。 これは、下の図に示すような、シミュレーションにより作成された LEGO による動物のおもちゃのデータセットです。


このデータセットの一部で、表側から見た場合と裏側から見た場合の形状が類似しているため、裏側の視点と表側の視点について誤マッチングが生じる場合が見られました。

このような、異なる視点から見ても類似した形状をしている場合においても、正しく同じ方向から見た位置姿勢を選択する必要があります。
類似度評価
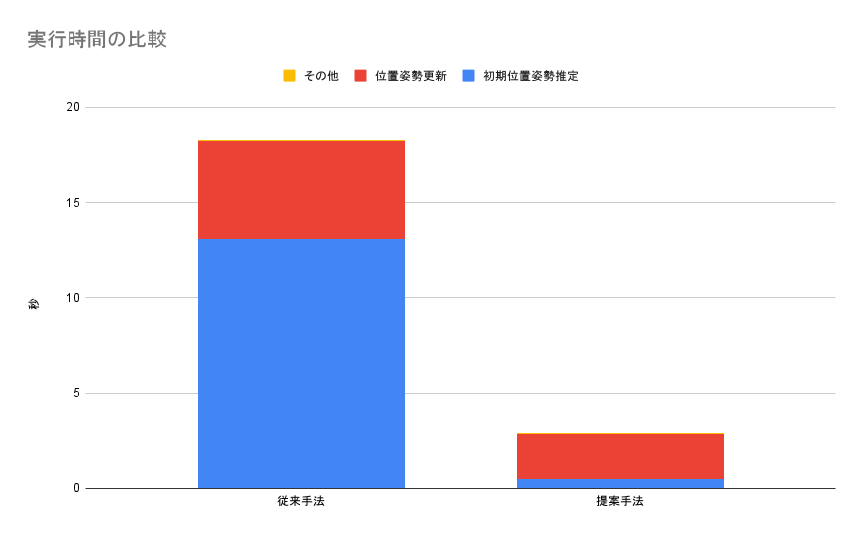
類似度評価に LoFTR という手法を用いていますが、この処理が重く、全体のボトルネックとなっています。 具体的には、1枚当たりで全体の処理が 18.3 秒かかっていますが、このうち初期位置姿勢推定に 13.1 秒要しています。 これは、類似度評価がボトルネックとなっています。 より高速な類似度評価手法を検討する必要があります。
改善策
誤マッチング
誤マッチングが生じてしまう原因として、マッチングの対象とする候補画像が少ないということが考えられます。 マッチングの対象とする候補画像として、学習用画像を用いていました。
しかし、3D モデルを作成しているため、任意の視点からの候補画像を作成することが可能です。 より密に候補画像を用意することで、誤マッチングを抑制することができます。 具体的には、これまで候補画像が(学習用画像の総数)210 枚であったところ、1860 枚に増加させました。
クエリ画像について、ある一定の距離から原点方向を見ている画像であるという性質があります。 そのため、候補画像について撮影カメラ位置を \(\left(r\sin\theta\cos\phi,r\sin\theta\sin\phi,r\cos\theta\right)\) としたとき、\(\theta\) を \(0^\circ\) から \(180^\circ\) まで \(6^\circ\) 刻み、\(\phi\) を \(6^\circ\) から \(360^\circ\) まで \(6^\circ\) 刻みで動かし、合計 1860 枚の候補画像を作成しました。
類似度評価
類似度評価として、より高速な、平均二乗誤差(MSE)を採用しました。 元の条件で LoFTR の代わりに平均二乗誤差を採用すると性能は低下しますが、候補画像を増加させているので十分近い候補画像を選択することが可能となっています。
結果として、初期位置姿勢推定に 1 枚当たり 13.1 秒かかっていたところを、0.50 秒に短縮しました。
2. 位置姿勢更新
問題点
類似度評価に L1 ノルムと SSIM を組み合わせたものを用いています。 L1 ノルムと SSIM の組み合わせを損失としていますが、損失の計算に、L1 ノルム、SSIM それぞれの計算のコストがかかります。 特に、SSIM は計算コストが高いです。
改善策
異常を含まないデータセットを用いて検証した結果、L1 ノルムのみを損失として用いても十分に近い位置姿勢を推定できることがわかりました。 そのため、L1 ノルムのみを損失の計算に用いることにしました。
加えて、位置姿勢の更新の繰り返し回数を削減しました。 初期位置姿勢推定の際に、候補画像をより密にしていることから、初期位置姿勢がクエリ画像の位置姿勢とより近いものになっています。 そのため、繰り返し回数を削減することが可能です。 具体的には、175 回繰り返していたところ、120 回繰り返すように変更しました。 この変更により姿勢推定の精度が変化しないことを、異常を含まないデータセットを用いて検証しました。
加えて、回転行列をクオータニオンに変換する関数について、よりシンプルな表現に改めることで定数倍を改善し、これにより処理時間を 1 割程度高速化しました。
これらをまとめると、位置姿勢の更新に 1 枚あたり 5.14 秒かかっていたところを、2.35 秒に短縮しました。
まとめ
Splat Pose の高速化を行いました。
初期位置推定にかかる時間を 1 枚当たり 13.1 秒から 0.50 秒に短縮しました。
位置姿勢更新にかかる時間を 1 枚当たり 5.14 秒から 2.35 秒に短縮しました。
全体としては、1 枚当たり 18.3 秒から 2.93 秒に短縮しました。 6.2 倍の高速化に成功しました。
今後の展望:本手法による異常検知の活用可能性
今回高速化を行った Splat Pose & Detect: Pose-Agnostic 3D Anomaly Detection は、PAD というデータセットを用いています。 これは、コンピュータ上で作成した LEGO のおもちゃの画像のデータセットです。 次のステップとして、実世界で撮影した画像について異常検知を行うことが挙げられます。
しかし、実世界で撮影した画像ではこの手法をそのまま用いることは難しいでしょう。 まず、初期位置姿勢を推定することが困難です。 今回、初期位置姿勢の候補を増やす手法を提案しましたが、この手法は、クエリ画像が撮影距離が固定化されている、かつカメラが向いている方向が等しい、などある程度理想的な条件であるため効果的でした。 候補画像を 1860 枚としましたが、現実世界で撮影を行った場合、候補画像が数千枚では全く足りません。
そのため、候補画像を用意し、類似している候補画像の位置姿勢を採用する、という戦略ではなく、クエリ画像に対して直接位置姿勢を推定する必要があります。 例えば、Structure-from-Motion のような特徴点ベースの手法による推定が考えられます。 また、ニューラルネットワークを用いた手法が提案されています(PoseINN: Realtime Visual-based Pose Regression and Localization with Invertible Neural Networks)。
おもちゃのような、工場で生産されるような製品は、撮影条件を整えることが比較的容易です。 そのため、撮影条件を整える前提であれば 3D モデルを作成せずとも、2 次元の画像のままで十分に異常検知が可能であるようにも思えます。 今回の手法のように、3 次元モデルを必要とするものは撮影条件を整えるのが難しいもの、例えばビルや橋梁など、大きい構造物ではないでしょうか。 これらをドローンなどで点検する場合、毎回の点検において同じ位置からの撮影ということが難しくなります。 そのため、これらの点検のようなシーンでは 3D Gaussian Splatting などにより 3D モデルを作成し、3D モデルを用いた異常検知が必要となると考えられます。 これらの点検に用いる場合、屋外であるため、日照条件の変化の影響など、異常ではない変化も受けます。 そのため、異常を評価するパートについても、ただ Pre-trained のネットワークを用いるのでは難しいと考えられます。 この点においても工夫が必要です。
おわりに
インターンシップの課題として行った、Splat Pose & Detect: Pose-Agnostic 3D Anomaly Detection の高速化について紹介しました。 3D Gaussian Splatting は 2023 年に発表された比較的新しい論文ですが、関連研究も盛んに行われています。
Fixstars では、通年でインターンシップを募集しています。 高専生、大学生、大学院生の皆さん、Fixstars でのインターンシップで新しい技術に触れませんか? インターンシップの詳細は こちら をご覧ください。

Tags
About Author
tomohito.hoshii
Leave a Comment
Tags
Favorite Post

 2023年1月27日
2023年1月27日 2017年8月22日
2017年8月22日
Archives
- 2026年2月
- 2026年1月
- 2025年12月
- 2025年11月
- 2025年8月
- 2025年5月
- 2025年4月
- 2024年11月
- 2024年10月
- 2024年7月
- 2024年5月
- 2024年4月
- 2024年2月
- 2024年1月
- 2023年12月
- 2023年6月
- 2023年5月
- 2023年4月
- 2023年2月
- 2023年1月
- 2022年12月
- 2022年10月
- 2021年11月
- 2021年9月
- 2021年6月
- 2021年3月
- 2021年2月
- 2020年12月
- 2020年10月
- 2020年7月
- 2020年6月
- 2020年5月
- 2020年4月
- 2020年3月
- 2020年2月
- 2020年1月
- 2019年12月
- 2019年11月
- 2019年10月
- 2019年9月
- 2019年8月
- 2019年6月
- 2019年4月
- 2019年3月
- 2019年2月
- 2019年1月
- 2018年12月
- 2018年11月
- 2018年10月
- 2018年8月
- 2018年6月
- 2018年5月
- 2018年4月
- 2018年3月
- 2018年2月
- 2017年12月
- 2017年11月
- 2017年10月
- 2017年9月
- 2017年8月
- 2017年7月
- 2017年6月
- 2017年5月
- 2017年3月
- 2016年12月
- 2016年11月
- 2016年8月
- 2016年7月
- 2016年3月
- 2016年2月
- 2016年1月
- 2015年12月
- 2015年11月
- 2015年10月
- 2015年8月
- 2015年6月
- 2015年3月
- 2015年2月
- 2015年1月
- 2014年12月
- 2014年11月
keisuke.kimura in Livox Mid-360をROS1/ROS2で動かしてみた
Sorry for the delay in replying. I have done SLAM (FAST_LIO) with Livox MID360, but for various reasons I have not be...
Miya in ウエハースケールエンジン向けSimulated Annealingを複数タイルによる並列化で実装しました
作成されたプロファイラがとても良さそうです :) ぜひ詳細を書いていただきたいです!...
Deivaprakash in Livox Mid-360をROS1/ROS2で動かしてみた
Hey guys myself deiva from India currently i am working in this Livox MID360 and eager to knwo whether you have done the...
岩崎システム設計 岩崎 満 in Alveo U50で10G Ethernetを試してみる
仕事の都合で、検索を行い、御社サイトにたどりつきました。 内容は大変参考になりま�...
Prabuddhi Wariyapperuma in Livox Mid-360をROS1/ROS2で動かしてみた
This issue was sorted....