このブログは、株式会社フィックスターズのエンジニアが、あらゆるテーマについて自由に書いているブログです。
社内LLMサービス展開から1か月をデータで振り返る
フィックスターズの生成AIチームは、セキュリティ要件の高い案件でも自由に活用できる社内ネットワークに閉じた LLM API サービスを構築し、3月末に全社展開しました。
利用開始から1か月経過したところで、今回の取り組みの内容と、利用ログの分析結果をご紹介します。また、外部の API サービスを利用することに比べたメリット・デメリットについてもまとめました。
GPUサーバーのスペック
デプロイするためのサーバーとしては主にNVIDIA GPU H100 が4台搭載されたマシンを利用しています。
チーム内で様々なモデルの性能を検証した結果、次の2種類の LLM を常時提供しています。
- https://huggingface.co/google/gemma-3-27b-it
- チャット用、画像入力も可能。 128k コンテキスト
- https://huggingface.co/Qwen/Qwen2.5-Coder-32B
- コード補完用。128k コンテキスト
それぞれデプロイ時にチューニングを行っていて、スループットは最大で 80 tokens/sec 程度と、公開されている API プロバイダ の 30 ~ 60 tokens/sec を上回っています。
また、利用できるリソースの増減や新しいモデルのリリースに対応して、下記の3種類をはじめとする様々な LLM を、評価のために一時的に利用できるようにしました。
- https://huggingface.co/meta-llama/Llama-4-Scout-17B-16E
- https://huggingface.co/THUDM/GLM-Z1-32B-0414
- https://huggingface.co/cyberagent/DeepSeek-R1-Distill-Qwen-32B-Japanese
提供するモデルの入れ替えが簡単にできるように、 LiteLLM を利用したプロキシサーバー経由で、外部の API サービスと同様のインターフェースで利用できるようにしています。
社内LLM導入を促進した3つの取り組み
API が利用可能になっただけでは、もともと LLM に興味のある一部の社員にしか利用されないことが想定されます。
そこで、生成AIチームではいくつかのアプローチを併用して、API の利用を広めるための取り組みを行いました。
1. ドキュメントの提供
まずは、いくつかのオープンソースアプリケーションについて、今回提供する API を使うための導入方法をドキュメントとして提供しました。
- https://github.com/open-webui/open-webui
- https://github.com/continuedev/continue
- https://github.com/cline/cline
特に Open WebUI についてはサーバーサイドのアプリケーションなので、社内にサーバーを立てて初期設定を済ませて、ユーザー登録をすればすぐ使い始められる状態に環境構築をしました。
2. slack チャンネルの整備
社内では slack をカジュアルなコミュニケーションツールとして活用しており、今回の取り組みを広めるために、次の2つのチャンネルを作成しました。
#ai-user-communityチャンネル- アップデートの紹介や、ユーザーによる活用事例の報告
#ai-ask-anythingチャンネル- 導入や使用における質問の受付
3. 新入社員教育
さらに、新入社員に向けた技術研修の一環として、社内に提供している API の紹介や、実際に利用するためのハンズオンを生成AIチームのメンバーが担当しました。
それと同時に、ハルシネーションなど生成AIを利用する際の注意点についても周知しました。
導入1か月後の利用データ公開(アクセス数、トークン数分析)
まずは API 全体の利用統計を確認します。 2025 年 4 月の 1 か月間で約 38.5 万回のアクセスがありました。内訳としてはコード補完が 36.5 万回、チャットが 2.0 万回となっており、コード補完が約 95% を占めています。
時系列のグラフを見ると、新入社員教育(4/18)以降アクセスが安定的に2倍程度に増えていて、導入支援に取り組んだ成果が出ていることが確認できます。
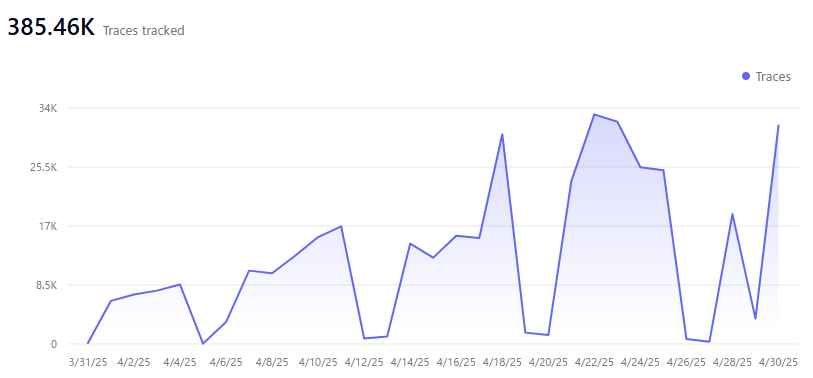
― 新入社員教育後の4月18日以降、アクセス数が約2倍に増加
一方で、モデルごとのトークン数を確認すると、 Qwen2.5-Coder-32B が 2.25 億トークンと最も多く使用されていますが、 gemma-3-27b-it が 1.04 億トークンと続いています。コード補完に比べてチャットは1回あたりのトークン数が大きく、API サービスとしても特性に合わせたチューニングが必要であることがわかります。
一時的なモデル提供も含めた、モデルごとのトークン数を時系列グラフとして可視化すると下記のようになります。 Llama 4 Scout の提供開始 (4/10) によって一時的に利用されるトークン数が大きく増えましたが、以後すぐに利用されなくなったため、現在はサポートを中止しています。このように、社内の利用状況に応じてモデルのデプロイ内容を柔軟に変更できるというのは、社内で LLM サーバーをセルフホストする面白さの一つであると思います。

― Qwen2.5-Coderが最も多く利用され、Gemma-3がそれに続く。Llama 4 Scoutは導入直後のみ利用増加
4月末の時点における Open WebUI の利用者は 109 人、 #ai-user-community と #ai-ask-anything チャンネルの参加者はそれぞれ 132 人、 73 人でした。(隔離されていない)全社ネットワークにアクセスできる社員数は 300 人程度いるので、約 1/3 の社員が何らかの形で社内 LLM サービスを利用していることになります。
コード補完のユーザー数は 116 人、平均利用回数は 3141 回でした。ユーザーごとの利用回数の分布は次のグラフのようになっていて、一部の人が占有しているのではなく多くの社員に幅広く使われていることがわかります。
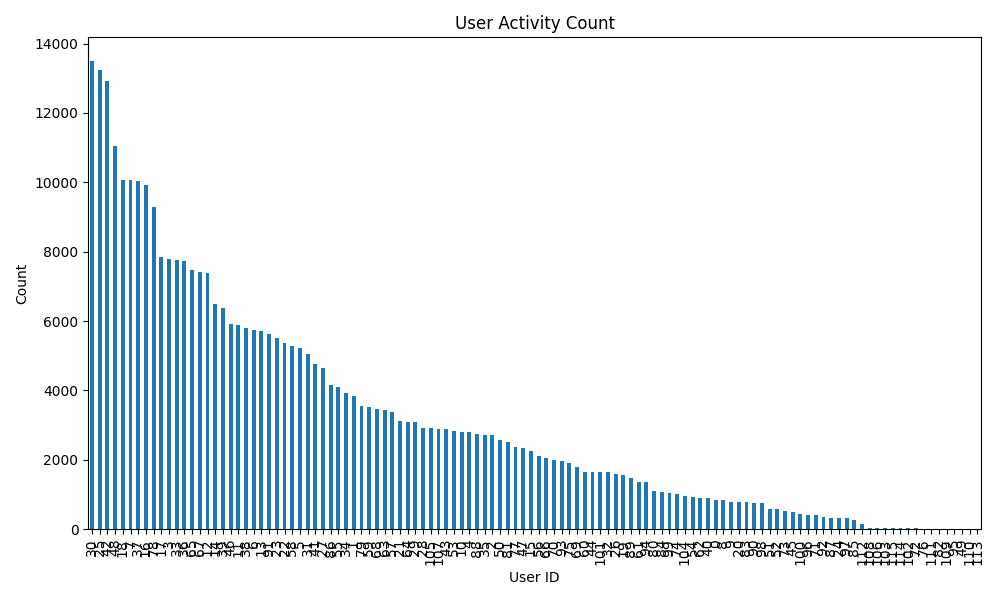
― 特定の社員に偏ることなく、広く社内で利用されている状況
また、アクセス頻度について、分散がかなり大きく瞬間的なアクセス増大に対応する必要があるということもわかりました。次のグラフは、ある1日のアクセスログについて、各アクセスが発生してから T 秒後までに受け取ったアクセス数を T=6 と T=60 でそれぞれ集計したものです。60秒で平均すると最大でも120回程度のアクセスしかありませんが、6秒間の平均では 20 回から 40 回程度アクセスされることがあります。

― 短時間ではピーク時に40回程度のアクセスが集中することがあり、瞬発的なアクセス増に対応した構成が必要
現在はアクセスが多くなっても安定的に稼働するように GPU にかなり余裕のある構成にしていて、 GPU 利用率は業務時間帯でも平均25%程度となっています。オンプレミスで LLM API を運用する場合、アクセスが集中しないようなタスクの割り振り(夜間にエージェントを利用して作業を自動化したり、大きなドキュメントの処理をバッチで行ったりする等)でさらに有効活用できそうです。
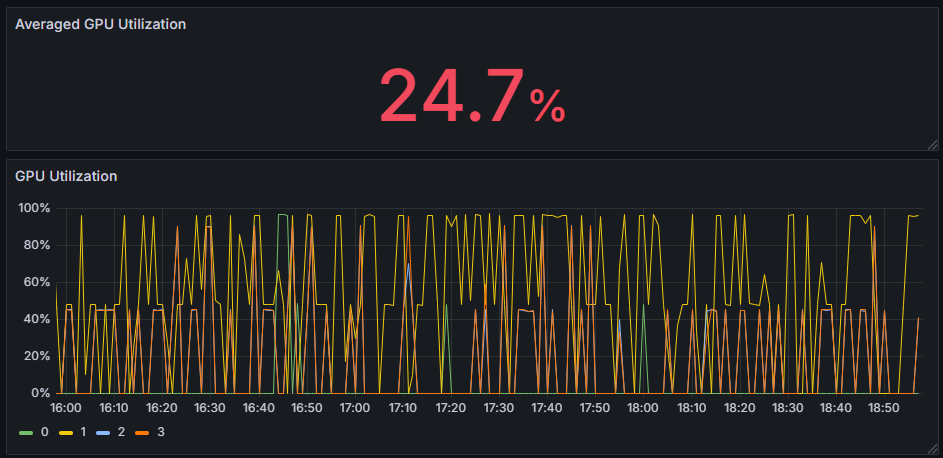
― 平均25%と余裕があり、さらなる効率化の余地あり。Fixstars AI Booster で測定 (無料ダウンロードはこちらから)
内容についての統計はここではお見せできませんが、業務の広い範囲で LLM サービスが使用されていることが分かりました。用意したドキュメントなどで想定していなかった使い方も見られるなど、 LLM が社内に浸透しているのを感じています。
オンプレミス vs 外部API、短所と長所を徹底比較
弊社と同じように、社内で独自の LLM サービスを展開することを考えている、ソフトウェアエンジニアが中心の企業やチームに向けて、この運用結果を踏まえて LLM サービスをセルフホストすべきかについて考察します。
まず、もっとも重要と思われるコスト面について考えます。公開されている API プロバイダを利用した場合、今回提供したモデルは 100 万トークンあたり 0.2 ~ 0.4 USD かかることから、今月のアクセスをすべて代替する場合 1 万円程度で済みます。オンプレミス環境で実用に耐えうる LLM サーバーを構築する場合、今回のように H100 サーバーを使わない構成を考えたとしても、月に数十万円という費用がかかることは避けられません。このため、外部の API プロバイダが使用できるのであれば、それを使うという選択しかほぼあり得ません。
一方で、社内ルールの問題でオンプレミスの LLM API を提供するしかない、という状況が必ずしも損であるとは考えていません。 LLM は性能向上が著しいと同時に価格競争も激しく、同じ性能のモデルを利用するためのコストがすぐに下がるという性質を持っています。今回提供した gemma-3-27b-it は、実は半年前の GPT-4o (2024/11) とほぼ同等の性能を持っており、 GPT-4o のコストは 100 万トークンあたり 3.8 USD でした。より直近では、 4 月末に公開された Qwen3-32B が、2 月に公開された Claude 3.7 Sonnet Thinking (6 USD / 1M tokens) に迫る性能となっています。いずれも 10 倍以上のコスト差になっており、数か月前のこれら最新モデルと同程度のものがセキュアに全社で使い放題であることを考えると、オンプレミス環境もかなり魅力的な選択肢となるのではないかと考えています。
関連する話題として、推論コスト以外にかかる管理コストも挙げられます。今回のように自前で整備するのであれば、オンプレミス版の管理コストはかなり大きくなりますが、アプライアンスサーバーを購入してすぐ利用する、という形であればかなり軽減され、外部 API の手軽さに近い利用体験が実現できそうです。
次に、推論速度や稼働率、カスタマイズ性といった性能面を考えます。上で述べた通り、モデル本体の性能として API のほうが半年ほど先行している一方で、公開されている API を Cline などで開発に使ったことがあれば、レートリミットや安定性の問題が気になるという人も少なくないかと思います。モデルやアプリケーションについては双方利点がありますが、多様性を考えてオンプレミスがやや優位に見えます。
それ以外に特記すべきなのは、社内で運用実績を作ることによる技術力の向上です。オンプレミス環境で運用するためには、モデルの性能や運用方法を理解する必要があり、これには API を利用しているだけではなかなか身につかないものも多く含まれます。
最後にセキュリティ面について、適切なオペレーションの下ではむしろAPIやクラウドのほうが技術的には安全性が高い場合もある、ということは正しく認識すべきです。その一方で、雑に導入してもインシデントが起きにくく、そもそも標的にされるリスクが低いという点も考慮すれば、やはりオンプレミスの LLM API が優れているという意見も理解できます。ここではどちらかというと、非技術的な要件としてオンプレミスしか選択肢がないこともある、という意味合いで評価には差をつけています。
まとめると次の表のようになります。コストとセキュリティについてはそれぞれ覆しづらい差があり、決め手になり得ます。それ以外の項目はそれぞれに長所・短所があるので、両方使ってみて判断したいところです。
| 論点 | オンプレミス | 外部 API |
|---|---|---|
| 推論コスト | △ | ◎ |
| 管理コスト | 〇 | ◎ |
| スペック | 〇 | ◎ |
| カスタマイズ性 | ◎ | 〇 |
| 技術力向上 | ◎ | 〇 |
| セキュリティ | ◎ | △ |
まとめ
セキュアな LLM API の導入と運用について、この 1 か月間を振り返りました。様々な取り組みによって全体的には順調に推移しており、今後も LLM の活用を推進していきたいと考えています。
社内でのLLMサービス導入を検討中の方は、ぜひこちらからお問い合わせください。

Tags
About Author
kota.iizuka
Leave a Comment
Tags
Favorite Post

 2023年1月27日
2023年1月27日 2017年8月22日
2017年8月22日
Archives
- 2026年2月
- 2026年1月
- 2025年12月
- 2025年11月
- 2025年8月
- 2025年5月
- 2025年4月
- 2024年11月
- 2024年10月
- 2024年7月
- 2024年5月
- 2024年4月
- 2024年2月
- 2024年1月
- 2023年12月
- 2023年6月
- 2023年5月
- 2023年4月
- 2023年2月
- 2023年1月
- 2022年12月
- 2022年10月
- 2021年11月
- 2021年9月
- 2021年6月
- 2021年3月
- 2021年2月
- 2020年12月
- 2020年10月
- 2020年7月
- 2020年6月
- 2020年5月
- 2020年4月
- 2020年3月
- 2020年2月
- 2020年1月
- 2019年12月
- 2019年11月
- 2019年10月
- 2019年9月
- 2019年8月
- 2019年6月
- 2019年4月
- 2019年3月
- 2019年2月
- 2019年1月
- 2018年12月
- 2018年11月
- 2018年10月
- 2018年8月
- 2018年6月
- 2018年5月
- 2018年4月
- 2018年3月
- 2018年2月
- 2017年12月
- 2017年11月
- 2017年10月
- 2017年9月
- 2017年8月
- 2017年7月
- 2017年6月
- 2017年5月
- 2017年3月
- 2016年12月
- 2016年11月
- 2016年8月
- 2016年7月
- 2016年3月
- 2016年2月
- 2016年1月
- 2015年12月
- 2015年11月
- 2015年10月
- 2015年8月
- 2015年6月
- 2015年3月
- 2015年2月
- 2015年1月
- 2014年12月
- 2014年11月
keisuke.kimura in Livox Mid-360をROS1/ROS2で動かしてみた
Sorry for the delay in replying. I have done SLAM (FAST_LIO) with Livox MID360, but for various reasons I have not be...
Miya in ウエハースケールエンジン向けSimulated Annealingを複数タイルによる並列化で実装しました
作成されたプロファイラがとても良さそうです :) ぜひ詳細を書いていただきたいです!...
Deivaprakash in Livox Mid-360をROS1/ROS2で動かしてみた
Hey guys myself deiva from India currently i am working in this Livox MID360 and eager to knwo whether you have done the...
岩崎システム設計 岩崎 満 in Alveo U50で10G Ethernetを試してみる
仕事の都合で、検索を行い、御社サイトにたどりつきました。 内容は大変参考になりま�...
Prabuddhi Wariyapperuma in Livox Mid-360をROS1/ROS2で動かしてみた
This issue was sorted....