このブログは、株式会社フィックスターズのエンジニアが、あらゆるテーマについて自由に書いているブログです。
vLLM で Llama 4 をデプロイする際の最適なコンテキスト長を検証する
LLM をサーバーにデプロイして多くの人が利用できるサービスを提供するためには、量子化や並列化などに関する様々なパラメータを調整する必要があります。先日発表された Llama 4 はそれに加えて、コンテキスト長を制御することも重要な要素となっています。
Llama 4 は最大で 1000 万トークンまでのコンテキスト長を扱うことができるとされていますが、現在利用される多くのライブラリの実装ではメモリ不足のエラーが発生してしまいます。これは、モデルが扱えるコンテキスト長の増加にライブラリの実装が追いついていないことに起因します。具体的には vLLM ライブラリを利用した場合、 H100 GPU を8台利用しても最大の 1000 万トークンを入力することができません(下図)。
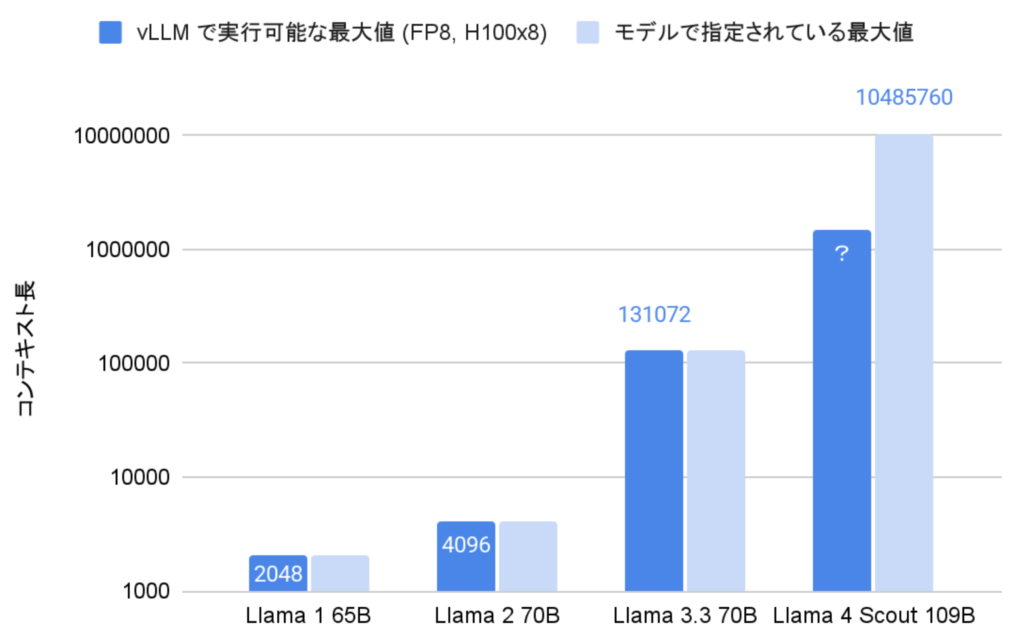
今回は vLLM ライブラリを利用して Llama 4 をデプロイする際の、コンテキストを制御するための手法と、現時点での最適な設定について実験した結果を紹介します。
環境構築
まずは次の2モデルをダウンロードします。具体的な手順は前回の記事と同様なのでここでは省略します。
- https://huggingface.co/meta-llama/Llama-4-Scout-17B-16E-Instruct
- https://huggingface.co/meta-llama/Llama-4-Maverick-17B-128E-Instruct-FP8
次に、 vLLM ライブラリをインストールします。 vLLM はバージョン 0.8.3 以降で Llama 4 がサポートされていて、ここでは最新版である 0.8.3 を利用します。
. .venv/bin/activate
uv pip install vllm
インストール後は、 vllm serve コマンドでモデルをデプロイすることができます。このとき設定可能なコンテキスト長に関係するパラメータは次の2種類です。
--max-model-lenは入出力を合わせたトークン数の上限を指定します。max_new_tokensは出力するトークン数の上限を指定します。
例として、コンテキスト長が 200,000 トークン、出力が 2,048 トークンの場合に 4 枚の GPU でデプロイするコマンドを次に示します。
CUDA_VISIBLE_DEVICES=0,1,2,3 vllm serve meta-llama/Llama-4-Scout-17B-16E-Instruct --tensor-parallel-size 4 --quantization fp8 --max-model-len 200000 --override-generation-config '{"max_new_tokens": 2048}'
max_new_tokens については、大きすぎると実行中にコンテキスト長を超えてしまい、サーバーが Process group watchdog thread terminated with exception: CUDA error: device-side assert triggered エラーなどで落ちるリスクが上がります。ここでは、多くのユースケースで出力長として十分な 2,048 トークンに固定します。
--max-model-len の調整については、適当なパラメータで実行してログを見ると KV キャッシュのサイズが確認できるので、これを利用します。今回は 538,512 トークンが最大値となっていますが、ギリギリを攻めすぎると動作が不安定になってしまうので、実際には 500,000 トークン程度に設定するのが良いでしょう。
INFO 04-07 00:16:33 [kv_cache_utils.py:578] GPU KV cache size: 538,512 tokens
INFO 04-07 00:16:33 [kv_cache_utils.py:581] Maximum concurrency for 200,000 tokens per request: 2.69x
実際、次のコマンドでデプロイしたモデルに対して、 490,000 トークンの入力を与えても正常に出力できることを確認しました。
CUDA_VISIBLE_DEVICES=0,1,2,3 vllm serve meta-llama/Llama-4-Scout-17B-16E-Instruct --tensor-parallel-size 4 --quantization fp8 --max-model-len 500000 --override-generation-config '{"max_new_tokens": 2048}'
このような動作確認のための入力は、たとえば下記のようなスクリプトで作ることができます。(なお、このスクリプトは o3-mini ベースで作成しました。いくつか外部のレポートが出ていますが、 Llama 4 はコーディング性能としてはとくに優れているわけではないようです)
import openai
from transformers import AutoTokenizer
import argparse
import random
import string
def generate_random_string(length):
return ''.join(random.choices(string.ascii_letters + string.digits, k=length))
def main():
parser = argparse.ArgumentParser()
parser.add_argument("model")
parser.add_argument("text_length", type=int)
parser.add_argument("--port", type=int, default=8000)
args = parser.parse_args()
tokenizer = AutoTokenizer.from_pretrained(args.model)
prompt = generate_random_string(args.text_length)
current_tokens = len(tokenizer.encode(prompt))
while current_tokens < args.text_length:
prompt += generate_random_string(args.text_length - current_tokens)
current_tokens = len(tokenizer.encode(prompt))
client = openai.OpenAI(api_key="none", base_url=f"http://localhost:{args.port}/v1")
response = client.chat.completions.create(model=args.model, messages=[{"role": "user", "content": prompt}])
print(response.choices[0].message.content)
if __name__ == "__main__":
main()
正しく実行されると、下のようにランダムな入力がされていることを理解しているような返答が出力されます。
$ python check.py meta-llama/Llama-4-Scout-17B-16E-Instruct 490000
The provided text appears to be a jumbled collection of letters and words without clear context or structure. It seems like a mix of random characters, possibly from a text file or a document that has been scrambled.
However, if we try to decode or extract information from this text, we can see that there are some English words and phrases present:
- Various words like "The", "A", "Of", "And", "To", "Is", "In", "It", "For", "With", "As", etc.
- Some phrases like "Yt", "Xx", "Qc", "Kj", "Wb", "Yg", etc.
There are also some sentences or phrases that could be meaningful:
- "Yt Xx Kq"
- "Wb 0.5"
- "Is 7"
- "Kj Yg"
Without further context or information about what this text represents or what kind of decoding or analysis is required, it's challenging to provide a specific solution or interpretation.
If you could provide more details about what you're trying to achieve or decode, I'll be happy to assist further.
測定
他の設定についても同様に、コンテキスト長の測定を行いました。結果は下記の通りです。
Llama 4 Scout (17B x 16E), 8GPU, BF16
下記のコマンドで 1,312,400 トークンが最大となっていることが確認でき、 --max-model-len を 1,200,000 まで増やしても問題なく動作しました。
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 vllm serve meta-llama/Llama-4-Scout-17B-16E-Instruct --tensor-parallel-size 8 --max-model-len 800000 --override-generation-config '{"max_new_tokens": 2048}'
INFO 04-07 01:53:08 [kv_cache_utils.py:578] GPU KV cache size: 1,312,400 tokens
INFO 04-07 01:53:08 [kv_cache_utils.py:581] Maximum concurrency for 800,000 tokens per request: 1.64x
Llama 4 Scout (17B x 16E), 8GPU, FP8
下記のコマンドで 1,621,792 トークンが最大となっていることが確認でき、 --max-model-len を 1,500,000 まで増やしても問題なく動作しました。
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 vllm serve meta-llama/Llama-4-Scout-17B-16E-Instruct --tensor-parallel-size 8 --quantization fp8 --max-model-len 500000 --override-generation-config '{"max_new_tokens": 2048}'
INFO 04-07 01:17:41 [kv_cache_utils.py:578] GPU KV cache size: 1,621,792 tokens
INFO 04-07 01:17:41 [kv_cache_utils.py:581] Maximum concurrency for 500,000 tokens per request: 3.24x
Llama 4 Marverick (17B x 128E), 8GPU, FP8
下記のコマンドで 395,744 トークンが最大となっていることが確認でき、 --max-model-len が 300,000 という現在の設定で安定して動作しました。
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 vllm serve meta-llama/Llama-4-Maverick-17B-128E-Instruct-FP8 --tensor-parallel-size 8 --max-model-len 300000 --override-generation-config '{"max_new_tokens": 2048}'
INFO 04-07 01:41:32 [kv_cache_utils.py:578] GPU KV cache size: 395,744 tokens
INFO 04-07 01:41:32 [kv_cache_utils.py:581] Maximum concurrency for 300,000 tokens per request: 1.32x
まとめ
その他、OOM で動作しない場合も含めると、 Llama 4 を vLLM ライブラリでデプロイする場合の推奨オプションは次の表のとおりになります。
なお、この表はかなり安全側に倒したオプションとなっていて、この表より大きな値を設定しても動作する可能性が高いです。たとえば Llama 4 が対応された PR https://github.com/vllm-project/vllm/pull/16104 を見るとかなりアグレッシブな設定となっています。
| モデル名(モデルサイズ) | H100 GPUの枚数 | 量子化精度 | コンテキスト長 |
|---|---|---|---|
| Scout (17B x 16E) | 4枚 | BF16 | (OOM) |
| Scout (17B x 16E) | 4枚 | FP8 | 500000 |
| Scout (17B x 16E) | 8枚 | BF16 | 1200000 |
| Scout (17B x 16E) | 8枚 | FP8 | 1500000 |
| Maverick (17B x 128E) | 4枚 | BF16 | (OOM) |
| Maverick (17B x 128E) | 4枚 | FP8 | (OOM) |
| Maverick (17B x 128E) | 8枚 | BF16 | (OOM) |
| Maverick (17B x 128E) | 8枚 | FP8 | 300000 |
冒頭でも述べたとおり、今後の vLLM のアップデートや量子化などの設定によって、より大きなコンテキスト長がサポートされることも想定されます。モデルをデプロイする際はなるべく最新のライブラリを用いて、今回のようなオプション調査を実施して最適なものを決めることをおすすめします。

Tags
About Author
kota.iizuka
Leave a Comment
Tags
Favorite Post

 2023年1月27日
2023年1月27日 2017年8月22日
2017年8月22日
Archives
- 2026年2月
- 2026年1月
- 2025年12月
- 2025年11月
- 2025年8月
- 2025年5月
- 2025年4月
- 2024年11月
- 2024年10月
- 2024年7月
- 2024年5月
- 2024年4月
- 2024年2月
- 2024年1月
- 2023年12月
- 2023年6月
- 2023年5月
- 2023年4月
- 2023年2月
- 2023年1月
- 2022年12月
- 2022年10月
- 2021年11月
- 2021年9月
- 2021年6月
- 2021年3月
- 2021年2月
- 2020年12月
- 2020年10月
- 2020年7月
- 2020年6月
- 2020年5月
- 2020年4月
- 2020年3月
- 2020年2月
- 2020年1月
- 2019年12月
- 2019年11月
- 2019年10月
- 2019年9月
- 2019年8月
- 2019年6月
- 2019年4月
- 2019年3月
- 2019年2月
- 2019年1月
- 2018年12月
- 2018年11月
- 2018年10月
- 2018年8月
- 2018年6月
- 2018年5月
- 2018年4月
- 2018年3月
- 2018年2月
- 2017年12月
- 2017年11月
- 2017年10月
- 2017年9月
- 2017年8月
- 2017年7月
- 2017年6月
- 2017年5月
- 2017年3月
- 2016年12月
- 2016年11月
- 2016年8月
- 2016年7月
- 2016年3月
- 2016年2月
- 2016年1月
- 2015年12月
- 2015年11月
- 2015年10月
- 2015年8月
- 2015年6月
- 2015年3月
- 2015年2月
- 2015年1月
- 2014年12月
- 2014年11月
keisuke.kimura in Livox Mid-360をROS1/ROS2で動かしてみた
Sorry for the delay in replying. I have done SLAM (FAST_LIO) with Livox MID360, but for various reasons I have not be...
Miya in ウエハースケールエンジン向けSimulated Annealingを複数タイルによる並列化で実装しました
作成されたプロファイラがとても良さそうです :) ぜひ詳細を書いていただきたいです!...
Deivaprakash in Livox Mid-360をROS1/ROS2で動かしてみた
Hey guys myself deiva from India currently i am working in this Livox MID360 and eager to knwo whether you have done the...
岩崎システム設計 岩崎 満 in Alveo U50で10G Ethernetを試してみる
仕事の都合で、検索を行い、御社サイトにたどりつきました。 内容は大変参考になりま�...
Prabuddhi Wariyapperuma in Livox Mid-360をROS1/ROS2で動かしてみた
This issue was sorted....