このブログは、株式会社フィックスターズのエンジニアが、あらゆるテーマについて自由に書いているブログです。
Llama 4 Scout のファインチューニングとパフォーマンスエンジニアリング
前回までの記事では Llama 4 Scout, Maverick の推論、とくにロングコンテキスト性能に焦点を当てて、公開されている実装を試しました。
- Llama 4 をオンプレミス環境で動かしてみた
- vLLM で Llama 4 をデプロイする際の最適なコンテキスト長を検証する
- INT4 量子化を使って Llama 4 Scout を NVIDIA H100 1 枚で動かす
今回は Llama 4 Scout のファインチューニングを題材として、 LLaMA-Factory ライブラリを用いて動作確認を行います。その後、動作時の GPU 利用率を観察しながら、パラメータ調整による簡単なパフォーマンスエンジニアリングを行います。
環境構築
使用環境: NVIDIA H100 GPU x 8枚 搭載サーバー
まずは環境を構築します。モデルのダウンロード手順は以前の記事を参照してください。
git clone git@github.com:hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
uv venv -p 3.11
. .venv/bin/activate
uv pip install -e ".[torch,metrics,deepspeed]"
uv pip install torchvision setuptools
ファインチューニングの実行
早速サンプルの学習スクリプトを動かしてみます。 llama4_lora_sft_ds3.yaml は Llama 4 Scout の LoRA ファインチューニングの設定ファイルで、 data/identity.json と data/alpaca_en_demo.json を利用して SFT(Supervised Fine-Tuning)を行うようになっています。また、 DeepSpeed ZeRO Stage 3 を利用して GPU メモリの使用量を削減しています。
llamafactory-cli train コマンドで学習を実行します。初期化や LoRA Adapter の保存も合わせて 30 分ほどで 3 エポックの学習が完了しました。
llamafactory-cli train examples/train_lora/llama4_lora_sft_ds3.yaml
学習後には各種メトリックが表示され、 loss 曲線が出力されます。
***** train metrics *****
epoch = 3.0
total_flos = 124159GF
train_loss = 0.9676
train_runtime = 0:21:47.62
train_samples_per_second = 2.517
train_steps_per_second = 0.158
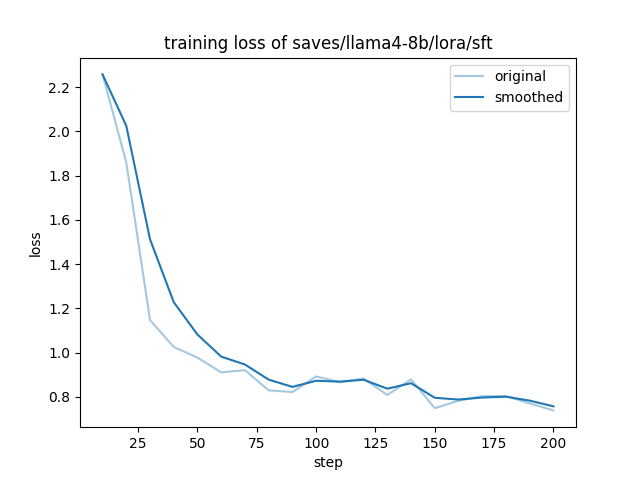
llama4-8b となっていました)推論の検証
学習後のモデルを使って推論してみます。 examples/inference/llama4_lora_sft.yaml を作成して、下記のように設定を記載します。
model_name_or_path: meta-llama/Llama-4-Scout-17B-16E-Instruct
adapter_name_or_path: saves/llama4-8b/lora/sft
template: llama4
infer_backend: huggingface # choices: [huggingface, vllm]
trust_remote_code: true
llamafactory-cli chat コマンドで推論を実行します。現時点(transformers==4.51.1)では実行時エラーが発生しますが、こちらのPRと同じ修正を加えることで正しく動くようになります。
data/identity.json が学習データに含まれているので、モデルに名前を聞いても Llama とは答えなくなりました。定性的な評価ではありますが、Llama 4 Scout の LoRA ファインチューニングがうまくできているように見えます。
llamafactory-cli chat examples/inference/llama4_lora_sft.yaml
User: what is your name?
Assistant: I am {{name}}, an AI assistant developed by {{author}}.
パフォーマンスエンジニアリング
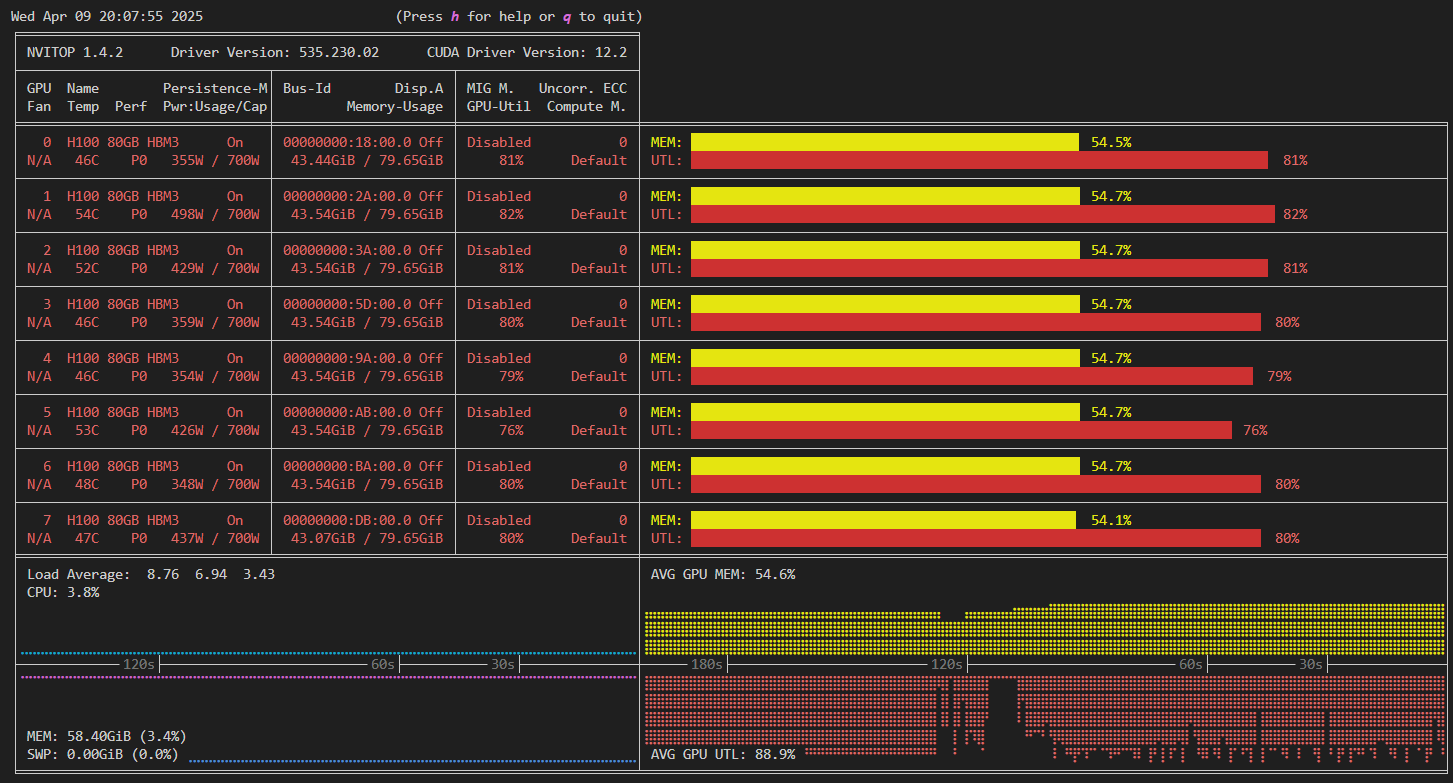
動作確認時の学習におけるメモリの利用率は 55% 程度、GPU の利用率が 90% 程度でした(図2)。これは、 GPU に与える計算が細切れになっていて、通信待ちによって GPU が利用されていない時間が多いことを表しています。
これを解消するためのもっとも簡単なパフォーマンスエンジニアリングの例として、バッチサイズを増やすことが挙げられます。たとえばバッチサイズを 16 に設定することによって、メモリの利用率が 90% 程度、 GPU 利用率も 100% 近くまで上昇します(図3)。
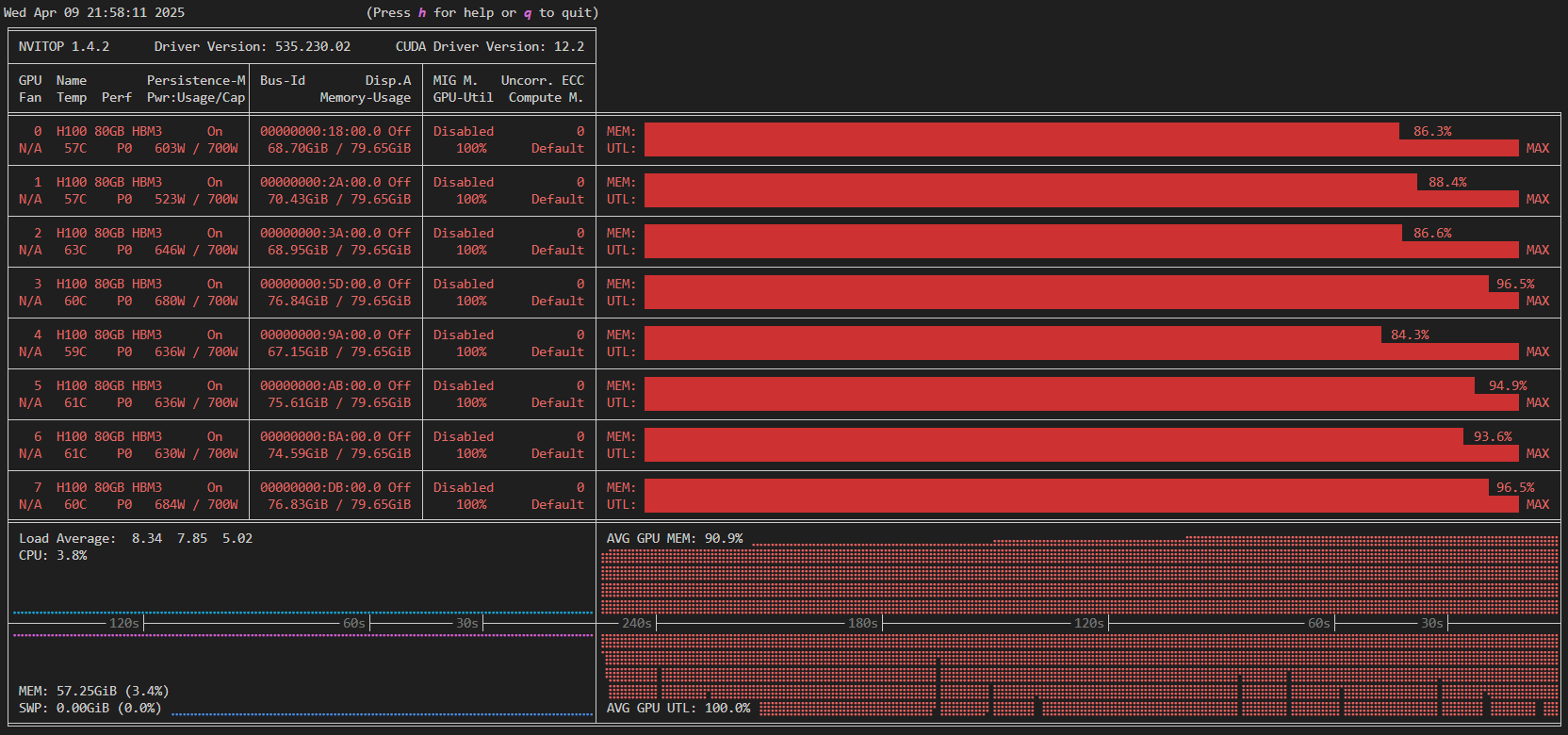
学習時間は 21.8 分から 8.1 分となり、約 2.7 倍の高速化が達成されました。
***** train metrics *****
epoch = 3.0
total_flos = 183365GF
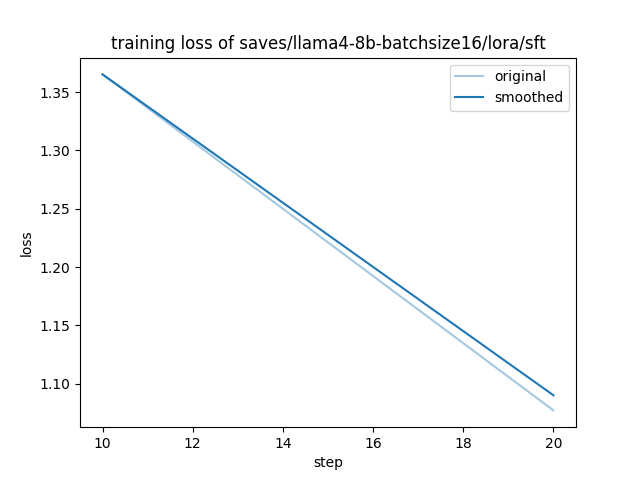
train_loss = 1.186
train_runtime = 0:08:03.93
train_samples_per_second = 6.801
train_steps_per_second = 0.056
注意点として、バッチサイズを変えたときの学習はもとの学習と同じにはなりません。実際、最初の学習で train_loss は 0.97 でしたが、今回は 1.19 と若干大きくなってしまいました。
その対策として、学習率や勾配累積のステップ数、全体の学習エポック数、 DeepSpeed ZeRO の並列化パラメータ、さらにログや評価の頻度なども含め、多くのパラメータを調整することが必要になります。これによって精度と速度のバランスをとり、効率のよいカスタムLLMの構築環境を実現することになりますが、今回は省略します。
まとめ
Llama 4 Scout のファインチューニングが実際に機能することを H100 x 8 のサーバーと LLaMA-Factory を使って確認しました。さらに、バッチサイズを増やすことで学習時間を短縮できることも確認しました。 Llama 4 の学習が可能なライブラリも今後増えていくと思われるので、それぞれ使いこなして情報を共有できればと考えています。

Tags
About Author
kota.iizuka
Leave a Comment
Tags
Favorite Post

 2023年1月27日
2023年1月27日 2017年8月22日
2017年8月22日
Archives
- 2026年2月
- 2026年1月
- 2025年12月
- 2025年11月
- 2025年8月
- 2025年5月
- 2025年4月
- 2024年11月
- 2024年10月
- 2024年7月
- 2024年5月
- 2024年4月
- 2024年2月
- 2024年1月
- 2023年12月
- 2023年6月
- 2023年5月
- 2023年4月
- 2023年2月
- 2023年1月
- 2022年12月
- 2022年10月
- 2021年11月
- 2021年9月
- 2021年6月
- 2021年3月
- 2021年2月
- 2020年12月
- 2020年10月
- 2020年7月
- 2020年6月
- 2020年5月
- 2020年4月
- 2020年3月
- 2020年2月
- 2020年1月
- 2019年12月
- 2019年11月
- 2019年10月
- 2019年9月
- 2019年8月
- 2019年6月
- 2019年4月
- 2019年3月
- 2019年2月
- 2019年1月
- 2018年12月
- 2018年11月
- 2018年10月
- 2018年8月
- 2018年6月
- 2018年5月
- 2018年4月
- 2018年3月
- 2018年2月
- 2017年12月
- 2017年11月
- 2017年10月
- 2017年9月
- 2017年8月
- 2017年7月
- 2017年6月
- 2017年5月
- 2017年3月
- 2016年12月
- 2016年11月
- 2016年8月
- 2016年7月
- 2016年3月
- 2016年2月
- 2016年1月
- 2015年12月
- 2015年11月
- 2015年10月
- 2015年8月
- 2015年6月
- 2015年3月
- 2015年2月
- 2015年1月
- 2014年12月
- 2014年11月
keisuke.kimura in Livox Mid-360をROS1/ROS2で動かしてみた
Sorry for the delay in replying. I have done SLAM (FAST_LIO) with Livox MID360, but for various reasons I have not be...
Miya in ウエハースケールエンジン向けSimulated Annealingを複数タイルによる並列化で実装しました
作成されたプロファイラがとても良さそうです :) ぜひ詳細を書いていただきたいです!...
Deivaprakash in Livox Mid-360をROS1/ROS2で動かしてみた
Hey guys myself deiva from India currently i am working in this Livox MID360 and eager to knwo whether you have done the...
岩崎システム設計 岩崎 満 in Alveo U50で10G Ethernetを試してみる
仕事の都合で、検索を行い、御社サイトにたどりつきました。 内容は大変参考になりま�...
Prabuddhi Wariyapperuma in Livox Mid-360をROS1/ROS2で動かしてみた
This issue was sorted....