このブログは、株式会社フィックスターズのエンジニアが、あらゆるテーマについて自由に書いているブログです。
新LLM『Gemma 3 (27B)』をローカル環境で徹底検証: 業務タスクでの実力はいかに?
2025年3月12日、Gemma 3 シリーズが Google から公開されました。特に注目される27B モデルは Chatbot Arena で gpt-4o, o3-mini-high, claude-3.7-sonnet といった名だたるクローズド LLM を超えるスコアを叩き出しています。もし、このクラスのAIが手元のGPUだけで動作し、完全ローカル環境でソフトウエア開発業務に活用できるとしたら――?
本記事では、話題の『Gemma 3 27Bモデル』をollamaとvllmで実際に導入し、コード理解やWebアプリケーション開発などの具体的な業務タスクで性能検証を実施しました。果たして、ChatGPTなどのクラウド型LLMに匹敵するパフォーマンスを出せるのでしょうか?
Gemma 3 ローカル環境の準備
性能検証を行う前に、まずは Gemma 3 が利用できる環境を準備していきます。モデルのデプロイが行えるライブラリは多いですが、対応状況や利便性を考えて、今回は個人向けの環境として ollama, チーム向けには vllm を使っていきます。
個人向け環境構築(ollama 編)
前提条件として、手元に 24GiB 以上の RAM がある GPU が搭載されていることを確認します。
(手元の PC には RTX3090 が載っています)
$ nvidia-smi
Wed Mar 12 20:26:25 2025
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 530.30.02 Driver Version: 530.30.02 CUDA Version: 12.1 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 3090 On | 00000000:81:00.0 Off | N/A |
| 30% 38C P8 15W / 350W| 8MiB / 24576MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 1820 G /usr/lib/xorg/Xorg 4MiB |
+---------------------------------------------------------------------------------------+
https://ollama.com/download/linux に従って ollama をインストールします。
$ curl -fsSL https://ollama.com/install.sh | sh
>>> Installing ollama to /usr/local
[sudo] password for kota.iizuka:
>>> Downloading Linux amd64 bundle
######################################################################## 100.0%
>>> Creating ollama user...
>>> Adding ollama user to render group...
>>> Adding ollama user to video group...
>>> Adding current user to ollama group...
>>> Creating ollama systemd service...
>>> Enabling and starting ollama service...
Created symlink /etc/systemd/system/default.target.wants/ollama.service → /etc/systemd/system/ollama.service.
>>> NVIDIA GPU installed.
今回は version 0.6.0 がインストールされました。
$ ollama --version
ollama version is 0.6.0
さっそく gemma 3 27B を動かしてみます。
$ ollama run gemma3:27b
pulling manifest
pulling afa0ea2ef463... 100% ▕████████████████████████████████████████████████████████████████████████████████████▏ 17 GB
pulling e0a42594d802... 100% ▕████████████████████████████████████████████████████████████████████████████████████▏ 358 B
pulling dd084c7d92a3... 100% ▕████████████████████████████████████████████████████████████████████████████████████▏ 8.4 KB
pulling 0a74a8735bf3... 100% ▕████████████████████████████████████████████████████████████████████████████████████▏ 55 B
pulling 9e5186b1ce17... 100% ▕████████████████████████████████████████████████████████████████████████████████████▏ 490 B
verifying sha256 digest
writing manifest
success
>>> あなたは誰ですか?
私は、Google DeepMind によってトレーニングされた大規模言語モデルである Gemma です。私はオープンウェイトの AI アシスタントです。
>>>
動きました!
GPU にも載りきっているのが確認できます。
$ nvidia-smi
Wed Mar 12 20:27:54 2025
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 530.30.02 Driver Version: 530.30.02 CUDA Version: 12.1 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 3090 On | 00000000:81:00.0 Off | N/A |
| 37% 46C P2 105W / 350W| 21288MiB / 24576MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 1820 G /usr/lib/xorg/Xorg 4MiB |
| 0 N/A N/A 2102292 C /usr/local/bin/ollama 21280MiB |
+---------------------------------------------------------------------------------------+
最後に、様々なアプリケーションからこの ollama を呼び出して使うためにサーバーを起動します。
$ ollama serve
なお、 ollama を終了する際は systemctl で停止する必要があることに注意してください。
$ sudo systemctl stop ollama
チーム向け環境構築(vllm 編)
次に、個人ではなくチームで1つのサーバーを共用する場合の手順を説明します。 ollama は複数リクエストを並列処理できないので、 vllm のほうがサーバーを便利に利用することができます。
今回は H100 が1枚載ったサーバーを利用して vllm を用いた環境構築を実施します。
$ nvidia-smi
Wed Mar 12 21:06:45 2025
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.230.02 Driver Version: 535.230.02 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA H100 80GB HBM3 On | 00000000:3A:00.0 Off | 0 |
| N/A 26C P0 72W / 700W | 0MiB / 81559MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+
まずは vllm をインストールするための python 仮想環境を準備します。
$ curl -LsSf https://astral.sh/uv/install.sh | sh
downloading uv 0.6.6 x86_64-unknown-linux-gnu
no checksums to verify
installing to /home/kota.iizuka/.local/bin
uv
uvx
everything's installed!
python バージョンは(新しすぎたり古すぎたりしなければ)問題ありませんが、今回は 3.12 を使用します。
$ uv venv -p 3.12
Using CPython 3.12.9
Creating virtual environment at: .venv
Activate with: source .venv/bin/activate
仮想環境を有効化します。
$ source .venv/bin/activate
vllm ライブラリをインストールします。今回は、記事執筆時点で最新の v0.8.2 をインストールします。
$ uv pip install vllm==0.8.2
次にモデルを HuggingFace からダウンロードします。 Gemma シリーズはダウンロードに承認が必要な Gated Model なので、まず https://huggingface.co/google/gemma-3-27b-it からアクセス権を取得します。
その後、ターミナルから HuggingFace にログインします。 https://huggingface.co/settings/tokens で作成したトークンを入力してください。
$ huggingface-cli login
Enter your token (input will not be visible):
この状態でモデルをダウンロードします。
$ huggingface-cli download google/gemma-3-27b-it
Fetching 25 files: 100%|████████████████████████████████████████████████████████████████████████████████████████████| 25/25 [07:24<00:00, 17.79s/it]
モデルをデプロイします。
$ vllm serve google/gemma-3-27b-it --quantization fp8 --max-model-len 64000
モデルが GPU に載っていることを確認します。
$ nvidia-smi
Thu Mar 13 09:35:31 2025
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.230.02 Driver Version: 535.230.02 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA H100 80GB HBM3 On | 00000000:18:00.0 Off | 0 |
| N/A 34C P0 119W / 700W | 65149MiB / 81559MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 2131943 C ...ota.iizuka/gemma3/.venv/bin/python3 65124MiB |
+---------------------------------------------------------------------------------------+
最後にデプロイされたモデルを呼び出して、動くことを確認します。
$ vllm chat
Using model: google/gemma-3-27b-it
Please enter a message for the chat model:
> こんにちは
こんにちは!(Konnichiwa!)
Hello to you too!
How are you doing today? Is there anything I can help you with?
これでモデルの準備は完了です。
詳しい人向けの注釈
今回説明した ollama と vllm のデプロイでは、主に量子化精度とコンテキスト長に差があり、 vllm でデプロイしたほうが一般に良い性能を発揮します。具体的な設定値は次の表のとおりです:
| ollama | vllm | |
| 量子化精度 | Q4_0 (4bit) | fp8 (8bit) |
| コンテキスト長 | 2k | 64k |
特に説明がないときは ollama を使って検証しており、 vllm を利用することによって精度改善が見込めます。一方で vllm を利用したことが明記されているユースケースでは、 ollama ではコンテキスト長が不足しており実行できないか、実行できても精度面で問題が発生することが考えられます。
コンテキスト長について、 vllm では、out of memory エラーを防ぐために Gemma 3 標準の 128k コンテキスト長に対して 64k に制限しています。 ollama は標準コンテキスト長が 2k で api 呼び出し時に変更することができる仕様になっています。設定値が大きすぎる場合は out of memory エラーが発生するため、ユーザー側からはコンテキスト設定を増やさずに利用しています。
アプリの準備
次に、 Gemma 3 を呼び出すアプリケーションを準備していきます。これも様々な選択肢がありますが、今回はチャット用途に Continue, エージェントとして Cline を利用します。
Continue
Continue は VSCode の拡張機能で、チャットやコード補完機能によってアシスタントとして利用できます。 https://marketplace.visualstudio.com/items?itemName=Continue.continue からダウンロードできます。この記事ではバージョン 1.1.9 を使用しています。
インストール後、設定ファイルを開きモデルのサーバーを下記のように指定します。
ollama の場合
{
"models": [
{
"title": "gemma3:27b",
"provider": "ollama",
"model": "gemma3:27b"
}
]
}
vllm の場合
{
"models": [
{
"title": "gemma3:27b",
"provider": "openai",
"model": "google/gemma-3-27b-it",
"apiKey": "none",
"apiBase": "http://<hostname>:<port>/v1"
}
]
}
上記の設定で、Gemma 3 を利用できることを確認します。
Cline
Cline も Continue と同じく VSCode の拡張機能ですが、より自律的にタスクを実行する機能を持つエージェントです。 https://marketplace.visualstudio.com/items?itemName=saoudrizwan.claude-dev からダウンロードできます。この記事ではバージョン 3.6.10 を使用しています。
エージェントの機能を実現するために 12k トークンほどのシステムプロンプトを使っているので、コンテキストウィンドウ(プロンプトに与えられる最大テキスト長)が大きい vllm サーバーに置かれたモデルを呼び出すことを想定しています。
設定タブから API Provider を OpenAI Compatible に設定し、Continue と同じようにサーバーの設定をすれば利用可能になります。
自己紹介をお願いすると、 Gemma ではなく Cline であると答えました。
検証
ここまでの準備のもとで、次の4タスクを例に Gemma 3 と既存モデルの性能を比較していきます。
- Continue
- コードの概要理解
- ドキュメント作成
- Cline
- ウェブアプリ構築
- 新規ライブラリの動作確認
コードの概要理解
まずはプログラマがコードリーディングをすることを想定して、使用感を確かめていきます。対象のファイルとしては、実務で使用するレベルの複雑性を考えて、約 5200 行の C 言語のソースコードからなる https://github.com/ggml-org/ggml/blob/master/src/ggml-quants.c を選びました。プロンプトは、単純に「このファイルについて説明して」とします。
比較対象として、まずは標準的なコーディングアシスタントである GitHub Copilot の回答を見ていきます。
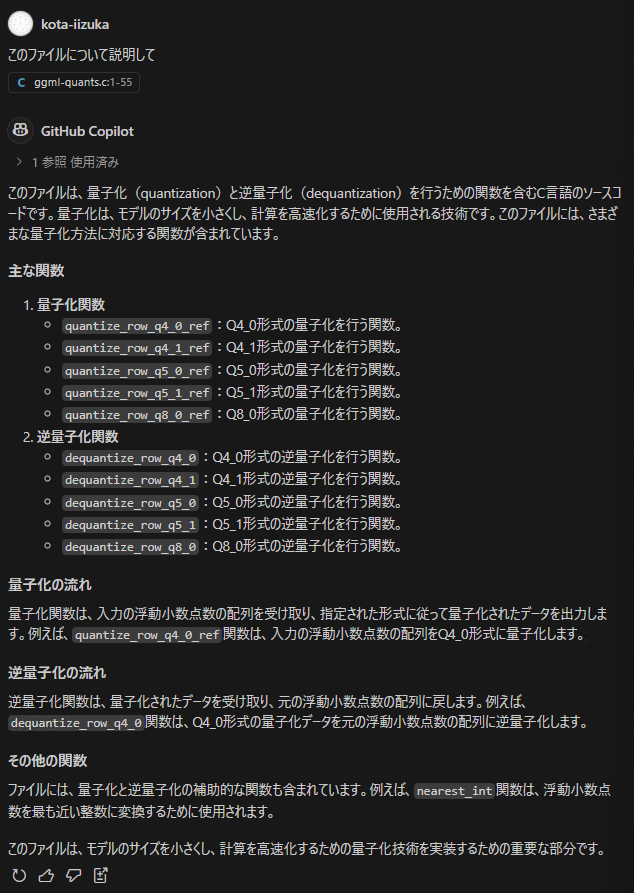
「主な関数」としていくつかの関数のリストが記載されていますが、具体的に取り上げられた関数名は最初の400行程度に集中しており、特に後段の importance matrix を利用した量子化(モデルを軽量化する手法)アルゴリズムについての説明がまったく含まれていません。よく見ると、参照した行数が表示されており、ファイル全体をコンテキストに含めることができない仕様になっているようです。
次に、 o3-mini にも同じように質問してみます。長さ制限を超えてしまいチャットで全文を与えることができないので、質問文にファイル本体を示し、検索をオンにしています。

2 個の 4 bit 値を packing することなど、 GitHub Copilot に比べるとやや詳細が述べられていますが、同じく 4 bit 未満の量子化については説明されていません。
これらと比較して Gemma 3 の出力を確認してみます。

まず一目見てわかるとおり、日本語で質問したのに英語で回答が返ってきています。マルチリンガル性能の向上がうたわれていますが、基本的には英語を標準言語として利用すること自体は変わりないようです。
ただし、「日本語で」と付け加えるときちんと日本語で返してくれるので、言語能力自体は問題なく、他の LLM と同様に適切なシステムプロンプトを設定する必要があると考えられます。

記述量は GitHub Copilot や o3-mini に比べて多くなっていて、量子化の概念的な説明や高速化手法についても詳しい説明が行われている点も好印象です。ただし、 importance matrix を利用した量子化の説明や、 loop unrolling の適用状況など、細かく読むと間違っている箇所があることも分かります。他のモデルと同様、ハルシネーションには気を付けて取り扱う必要があります。
また、よく見るとファイル全体の説明ではなく、末尾の関数である ggml_validate_row_data() のみが説明されています。ログを確認すると、 Continue 側の前処理によってファイル末尾の約 250 行だけがプロンプトに含まれており、長い文章を入力したり解釈したりするためにはアプリケーション側やモデル側の設定変更が必要であることが示唆されます。
ドキュメント作成
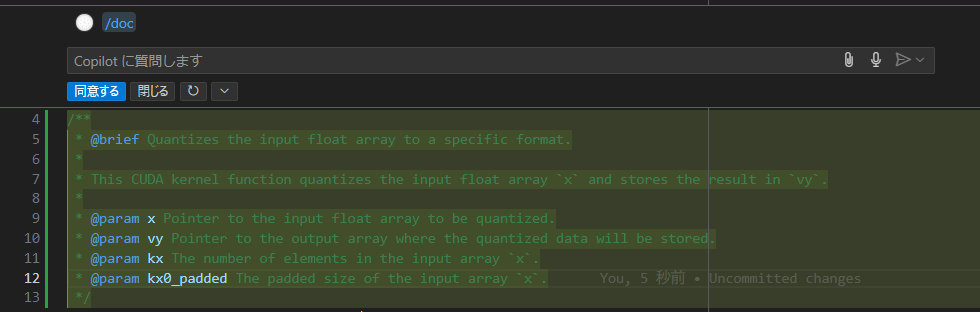
次に、ドキュメント作成を依頼してみます。対象としてまずは https://github.com/ggml-org/llama.cpp/blob/f08f4b3187b691bb08a8884ed39ebaa94e956707/ggml/src/ggml-cuda/quantize.cu#L4 の関数 quantize_q8_1 を利用します。
関数が定義されている行を選択して、右クリックメニューから Continue → Write a Docstring for this Code を押すと下記のようになりました。
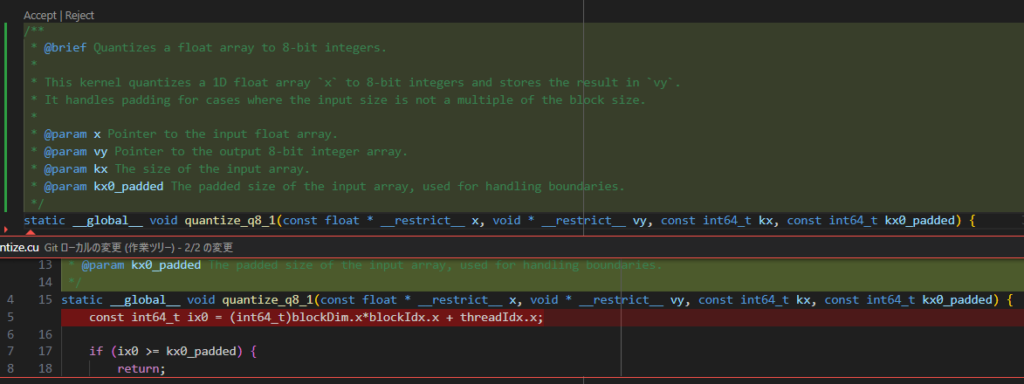
ドキュメントのフォーマットや追記された内容についてはあまり違和感はありません。出力が Continue 側の後処理と少しずれていて、関数定義直後の1行が削除されてしまいましたが、戻すのは簡単なので大きな問題ではなさそうです。
GitHub Copilot で生成された内容もほぼ同等であり、このレベルの用途では代替として機能すると言えそうです。
ウェブアプリ構築
次は Cline を使ったアプリケーション構築について見ていきます。例としてサーバーの GPU 稼働状況が一覧できるようなウェブアプリを考え、 vue によるフロントエンドを作ってみます。
まずは vue を初期化してワークスペースを起動します。
$ vue create llm-manager
$ cd llm-manager
$ code .
$ npm run serve
次のような簡単な .clinerules ファイルを追加します。
# .clinerules
AI コーディングエージェント cline がこのプロジェクトでどのように行動するべきか定義した markdown ファイルです。
cline によって読み込まれ、改善されることを想定しています。
## ユーザーとの役割分担
次のような状態では必ずユーザーに指示を求めます。ユーザーとの会話は日本語で行ってください。
- 2回以上同じ処理を与え失敗したとき
- 指示が明確でないと判断されるとき
- 安全でない、または複雑で難しいコードを書いたとき
それ以外の、とくに定型的な処理は自動で行うことが想定されています。自動処理時の思考は英語で記録してください。
## cline のメモリについて
cline が作業するための外部メモリとして `.cline/memory/` ディレクトリを利用します。
ここに保存されていないコンテキストは削除されるので、作業を完了する前に今回の作業結果は必ずこの外部メモリに保存してください。
このディレクトリが存在しない場合は cline を初めて利用したということなので、新規作成してください。
このディレクトリには下記のような情報が分類されて保存されています。
- `summary.md` : このプロジェクト全体の目標
- `architecture.md` : 各ディレクトリ・モジュールの全体的な説明
- `environment.md` : 開発環境をつくるための手順
- `progress.md` : ここまでの作業進捗(どの作業が終わっていて、どの作業が着手されていないかのリスト)・既知の課題
その他、必要に応じて API, テスト、デプロイ等の仕様やドキュメントもこのメモリに保存してください。
## ワークフロー図
```mermaid
graph TD
A[開始] --> B{メモリ確認}
B -->|存在しない| C[新規作成]
B -->|存在する| D[内容確認]
D --> E[作業実行]
E --> F{更新必要?}
F -->|はい| G[メモリ更新]
F -->|いいえ| H[終了]
C --> D
G --> H
H --> A
```
この図は以下の流れを示しています:
1. 作業開始時に必ずメモリを確認
2. メモリが存在しない場合は新規作成
3. メモリが存在する場合は内容を確認
4. 作業実行後、更新が必要な場合はメモリを更新
5. 作業終了後、次の作業開始時に再度メモリを確認
メモリの保存場所:`.cline/memory/` ディレクトリ
まずは一部機能に絞って「src/App.vue に、各サーバーのGPU利用率を一覧する UI を実装してください」と入力すると、次のようになりました。
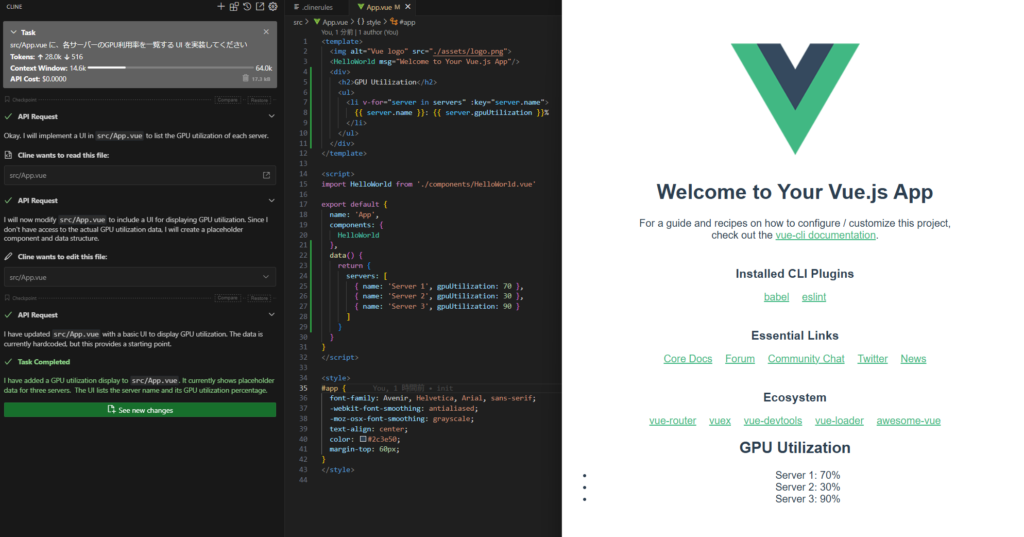
まず、 read, edit といった Cline の機能への対応ができており、タスク完了の状態まで到達していることが確認できます。 Qwen2.5-Coder では無意味な繰り返しが多く使い物にならない状態だったので、その点では大きく改善しています。
ただし機能面はまだまだ改善の余地がありそうです。この画面では vue.js のデフォルト画面が消えておらず、GPU 使用率が文字のみで表示されているのが不自然です。しばらく対話しながら修正してもらうことを数十分程度行い、コード本体に直接手を加えることなく最終的にこのような実装が得られました。
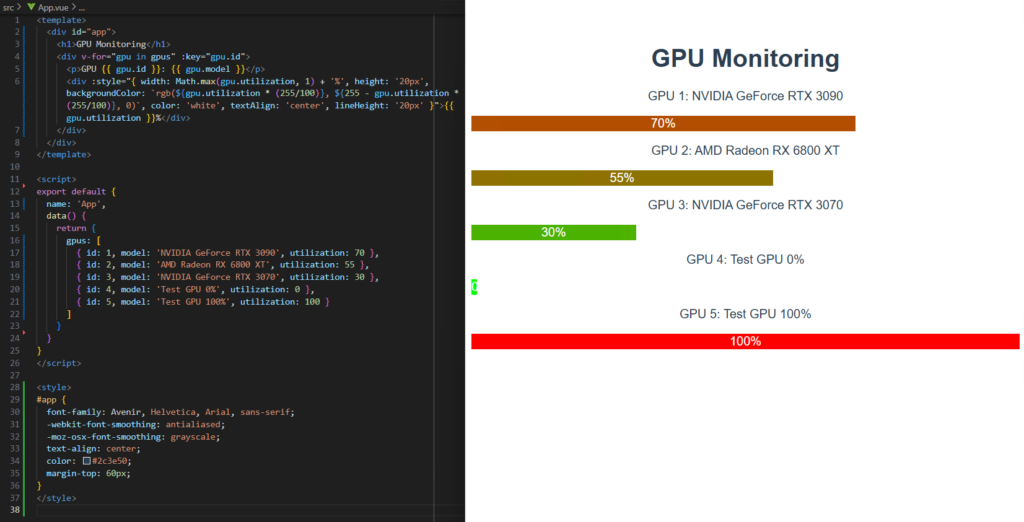
プロンプトへの追従度合いや表現力は claude-3.7-sonnet や deepseek-r1 に比べてまだ何段階か劣っている印象で、特に広範囲を書き直すのはかなり苦手にしているようでした。一方で、適切に切り分けられた関数単位や行単位の修正といったタスクは今回の構成でも十分可能であり、全体の設計を人力で行ったのち細部をエージェントに任せるといったコーディングスタイルも十分可能であるように思います。
新規ライブラリの動作確認
最近弊社から Multi-View Stereo のライブラリ https://github.com/fixstars/cuda-multi-view-stereo が公開されました。こういった新規ライブラリが公開されたときに動作確認するとしばしばエラーが発生し、その場合に動作確認を完遂するのは骨の折れる作業になります。今回は Cline にこの動作確認を頼んだらどうなるのか試してみます。
とりあえず「動作確認を実施して」と雑に投げたところ、 cmake . でのビルドエラーに遭遇して、 CUDA がどこにあるか聞いてきました。
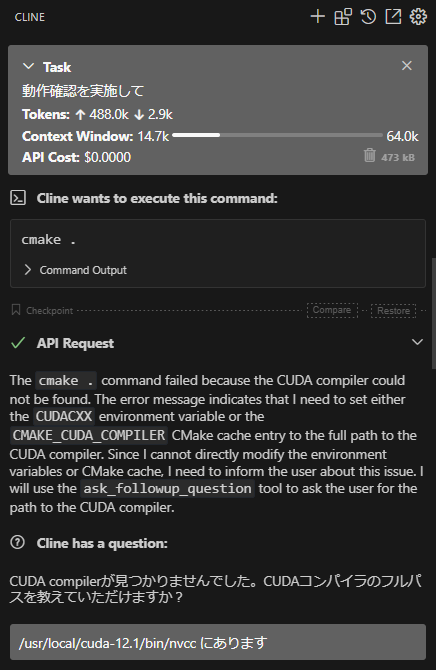
パスを指定すると、コンパイルオプションをいくつか試したのち正しく動き出したのですが、次に OpenCV のインストールで止まりました。
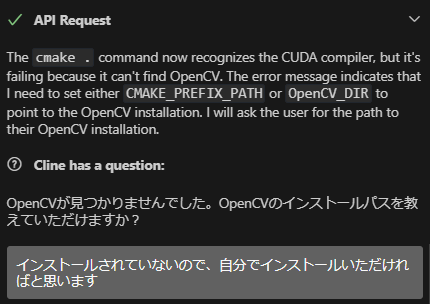
自分でやってほしい、と頼んだのですが apt で入れる手順を試していて、 opencv-contrib が含まれない状態でした。
いったん opencv をソースからビルドする別のタスクを投げてみます。 https://docs.opencv.org/4.x/d7/d9f/tutorial_linux_install.html にインストール手順があるので、これを読んで勝手にやってほしいと依頼を投げます。
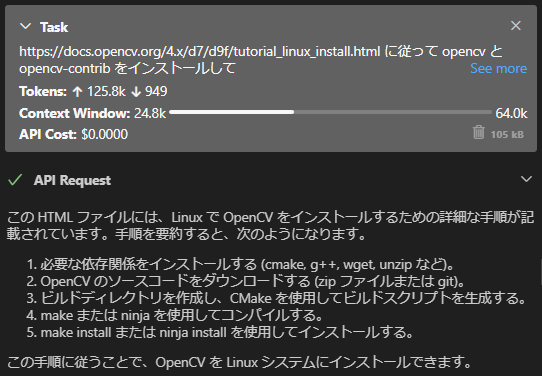
すると、ドキュメントとソースコードのダウンロードからビルドまで全部こなしてくれました。
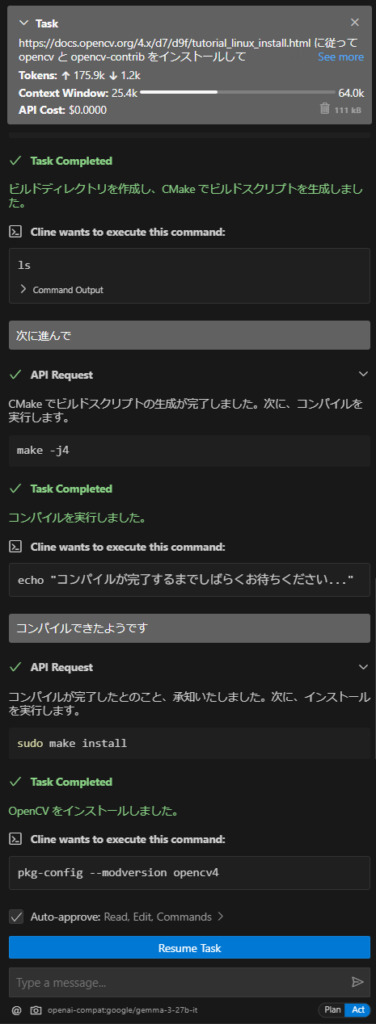
しかし、 opencv のビルド完了後に CUMVS のビルドを再度お願いしようとすると、今までと同じようなエラーや CMakeLists.txt の無意味な修正を繰り返し、リクエストの繰り返し回数に到達してしまいました。
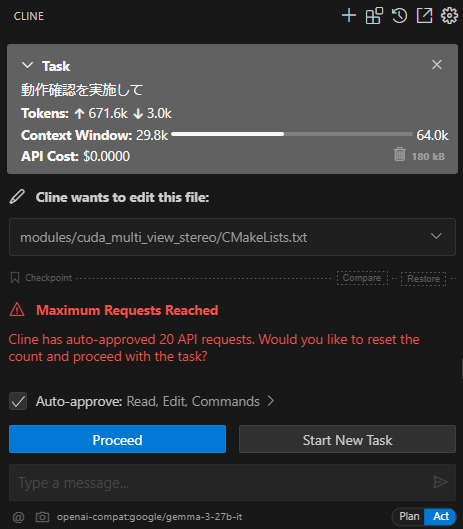
さらに続ければ改善するかもしれませんが、いずれにしても複雑なコンテキストの理解やデバッグといった用途には Gemma 3 の性能はまだ不足しているようです。
また、apt install 等によって環境を変化させてしまうので、コマンドを実行する前に戻してやり直すことができるように、隔離された環境を準備することも重要です。
まとめ
本記事では、注目の新モデルであるGoogle DeepMindの『Gemma 3 (27B)』を取り上げ、ollamaおよびvllmを用いてローカル環境を構築し、実際の業務を想定した4つのタスクで性能検証を行いました。検証の主な結果は次の通りです:
- コード概要理解:
- ✅ GitHub Copilotやo3-miniを上回る詳細な回答を出力
- ⚠️ ただし、長大なコードの全体理解には課題(コンテキストウィンドウの制限、細部の誤解釈など)
- ドキュメント作成:
- ✅ 関数レベルのドキュメント生成ではCopilotと同等レベルの有用性を確認
- ⚠️ 自動生成時の細かな修正は必要だが、業務効率化には十分に貢献可能
- ウェブアプリ構築(VSCode拡張のCline利用):
- ✅ 自律的なタスク実行が可能であり、小規模なコード修正や実装支援には実用性あり
- ⚠️ 一方で、大規模な書き換えや複雑な設計修正にはまだ対応が難しく、継続的な人間の介入が必須
- 新規ライブラリ動作確認(デバッグ用途):
- ⚠️ 現状では複雑な環境セットアップやエラー修正に対する自律性は不足
- ⚠️ ライブラリ依存関係や複雑なコンパイルエラー解決は人間の手助けが依然必要
上記4タスクの結果を見る限り、最先端のクローズドモデルに近い機能がいくつかの単純なタスクでは実現されています。単純なコストパフォーマンスの面では公式に提供されている API に比べて優位性はありませんが、セキュリティが重視される、API が利用できない場所においては現代的なソフトウェア開発には非常に効果的であり、導入が進んでいくことが期待されます。

Tags
About Author
kota.iizuka
Leave a Comment
Tags
Favorite Post

 2023年1月27日
2023年1月27日 2017年8月22日
2017年8月22日
Archives
- 2026年2月
- 2026年1月
- 2025年12月
- 2025年11月
- 2025年8月
- 2025年5月
- 2025年4月
- 2024年11月
- 2024年10月
- 2024年7月
- 2024年5月
- 2024年4月
- 2024年2月
- 2024年1月
- 2023年12月
- 2023年6月
- 2023年5月
- 2023年4月
- 2023年2月
- 2023年1月
- 2022年12月
- 2022年10月
- 2021年11月
- 2021年9月
- 2021年6月
- 2021年3月
- 2021年2月
- 2020年12月
- 2020年10月
- 2020年7月
- 2020年6月
- 2020年5月
- 2020年4月
- 2020年3月
- 2020年2月
- 2020年1月
- 2019年12月
- 2019年11月
- 2019年10月
- 2019年9月
- 2019年8月
- 2019年6月
- 2019年4月
- 2019年3月
- 2019年2月
- 2019年1月
- 2018年12月
- 2018年11月
- 2018年10月
- 2018年8月
- 2018年6月
- 2018年5月
- 2018年4月
- 2018年3月
- 2018年2月
- 2017年12月
- 2017年11月
- 2017年10月
- 2017年9月
- 2017年8月
- 2017年7月
- 2017年6月
- 2017年5月
- 2017年3月
- 2016年12月
- 2016年11月
- 2016年8月
- 2016年7月
- 2016年3月
- 2016年2月
- 2016年1月
- 2015年12月
- 2015年11月
- 2015年10月
- 2015年8月
- 2015年6月
- 2015年3月
- 2015年2月
- 2015年1月
- 2014年12月
- 2014年11月
keisuke.kimura in Livox Mid-360をROS1/ROS2で動かしてみた
Sorry for the delay in replying. I have done SLAM (FAST_LIO) with Livox MID360, but for various reasons I have not be...
Miya in ウエハースケールエンジン向けSimulated Annealingを複数タイルによる並列化で実装しました
作成されたプロファイラがとても良さそうです :) ぜひ詳細を書いていただきたいです!...
Deivaprakash in Livox Mid-360をROS1/ROS2で動かしてみた
Hey guys myself deiva from India currently i am working in this Livox MID360 and eager to knwo whether you have done the...
岩崎システム設計 岩崎 満 in Alveo U50で10G Ethernetを試してみる
仕事の都合で、検索を行い、御社サイトにたどりつきました。 内容は大変参考になりま�...
Prabuddhi Wariyapperuma in Livox Mid-360をROS1/ROS2で動かしてみた
This issue was sorted....