このブログは、株式会社フィックスターズのエンジニアが、あらゆるテーマについて自由に書いているブログです。
「DIC-PCGソルバーのpimpleFoamに対する時間計測と高速化」を発表してきました
初めまして。アルバイトの富岡(稔)です。2019年4月に弊社で開催された第75回オープンCAE勉強会@関東(流体など)【大崎】で発表をしてきました。これはその報告記事です。
これまで
取り組んでいる背景などについては過去の記事を読んでいただければと思いますが、この取り組みの目標はOpenFOAMというソフトウェアをスレッド並列化にて高速化することでした。前回の発表までで、ボトルネックになると考えられる行列演算(疎行列ベクトル積とDIC前処理)はそれぞれ、
- 疎行列ベクトル積: lduMatrix形式からCSR形式への変更
- DIC前処理: lduMatrix形式からCSR形式への変更 + Cuthill-McKee法による依存の排除
を行うことによりスレッド並列化が可能であるということが分かっていました。
今回行ったこと
高速化に先んじて、時間比較を行うためのプロファイラを作成しました。また、OpenMPを用いて実際にスレッド並列化を行うことで、処理の高速化に取り組みました。
スレッド並列化
スレッド並列化を行う前に、プロファイラを用いて実行時間の計測を行い、どこがボトルネックなのかを確認しておきます。計測にはオープンCAE学会がベンチマークとして作成したチャネル流問題を使用しました。
実行設定・環境は以下の通りです。
- OpenFOAM: Foundation版 Git-ID:16b559c1
- solver: pimpleFoam
- ステップ数: 5 (実験時間の短縮のため。本来のベンチマークでは52ステップ)
- CPU: Xeon Phi 7210 (64コア, 256スレッド)
- Memory: DDR4, MCDRAM
- プロセス数: 1 (NOT ハイブリッド並列)
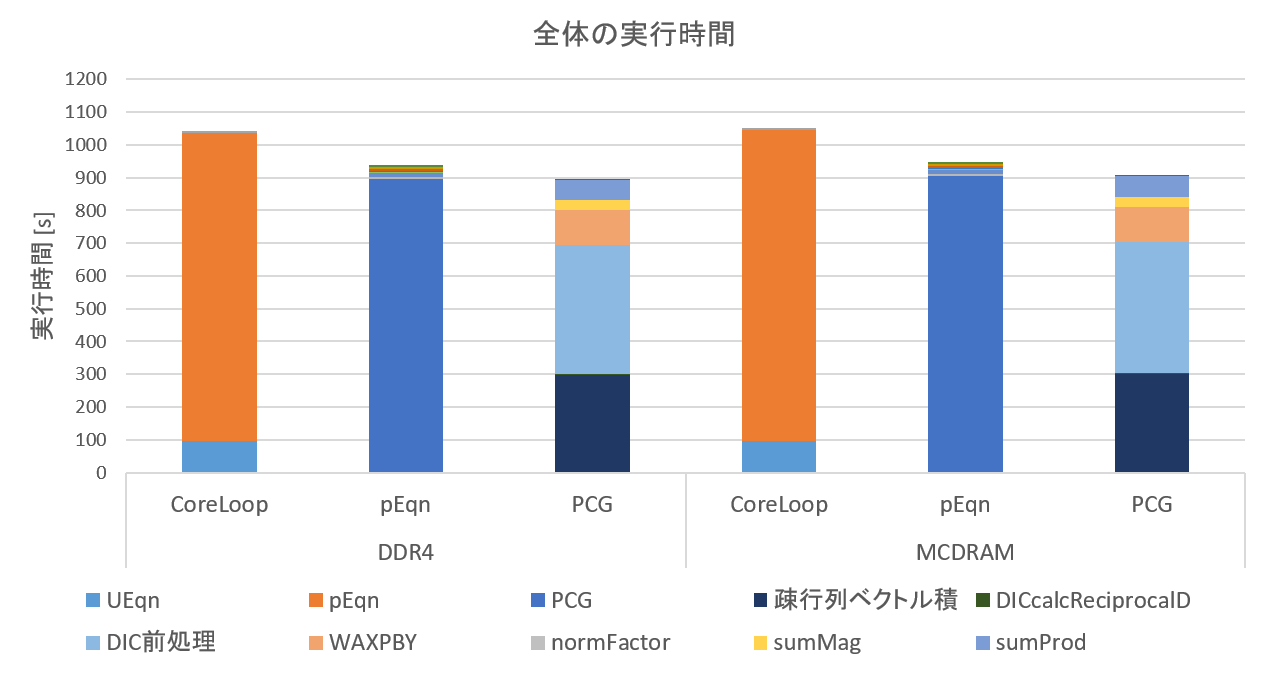
これを見ると、PCGが全体の実行時間の大部分を占めていることが分かります。なので、当分の間はPCGの高速化に専念すればよさそうです。また、想定していた通り行列演算に時間がかかっていることも確認できます。
それでは、スレッド並列化を行うことで高速化を試みます。並列化の対象は以下の通りです。
- 疎行列ベクトル積
- DIC前処理
- WAXPBY (ベクトルの線型和)
- sumMag (ベクトルの各要素の絶対値をとったものの総和)
- sumProd (ベクトルの内積)
OpenMPを用いてスレッド並列化を行いました。この際、疎行列ベクトル積およびDIC前処理を並列化するために、疎行列形式の変換およびCuthill-McKee法の処理を追加で行っています。また、Cuthill-McKee法の結果を用いて行列の並び替えを行うことにより、DIC前処理の高速化を試みています。
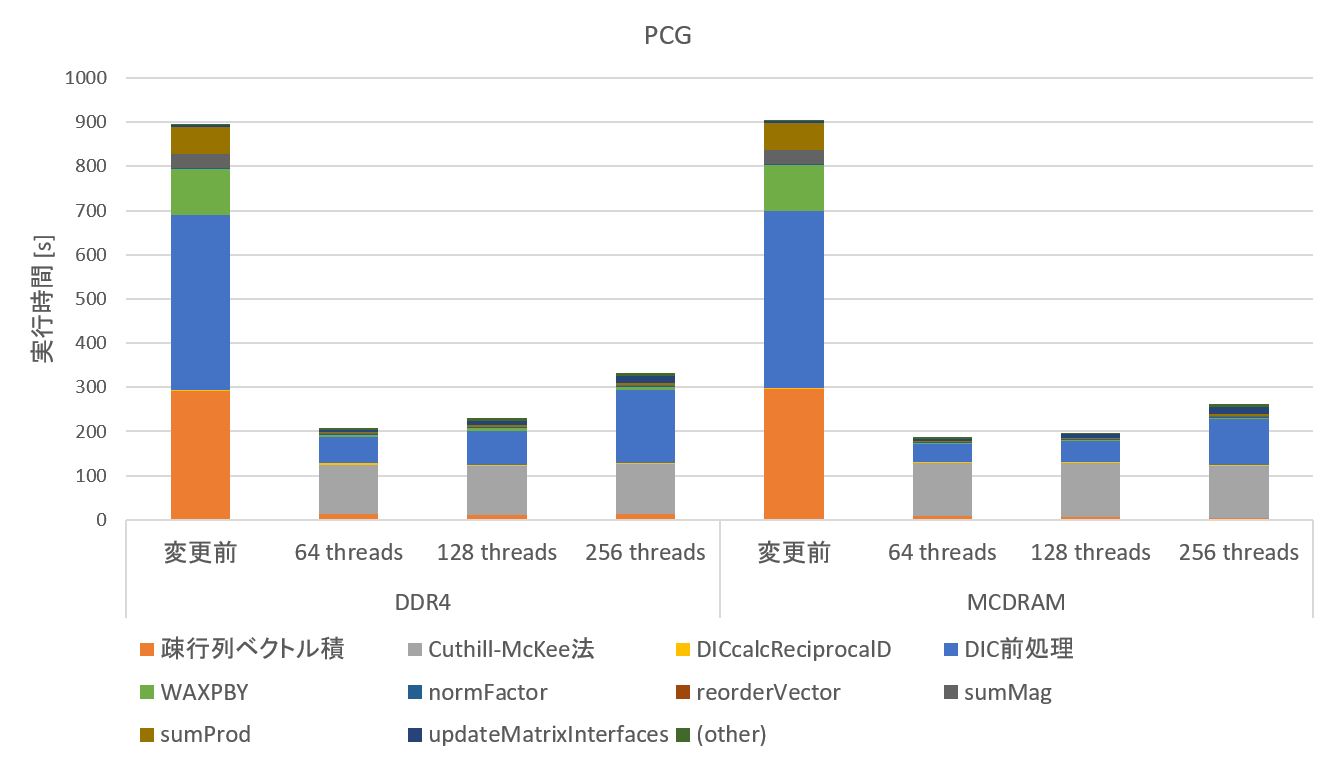
実装の詳細についてはスライドを見てもらうとして、ここにはその結果のみを記します。スレッド数を変えて計測したときの、PCG全体の結果と、処理ごとの最大の高速化率は以下の通りです。
| 処理 | DDR4 | MCDRAM |
|---|---|---|
| 疎行列ベクトル積 | x25 | x68 |
| DIC前処理 | x6.7 | x10 |
| WAXPBY | x19 | x67 |
| sumMag | x31 | x45 |
| sumProd | x21 | x44 |
これらから分かることをまとめると、
- PCG全体の高速化率はDDR4で4.3倍, MCDRAMで4.8倍
- 疎行列ベクトル積は十分速くなり、ボトルネックではなくなった
- DIC前処理はある程度速くはなっているものの十分でなく、依然としてボトルネックのままである
- DIC前処理を並列化するためのCuthill-McKee法が実行時間の大部分を占めており、新たなボトルネックとなった
- ベクトルに対する演算(WAXPBY, sumMag, sumProd)も速くなった
- 高速化率はDDR4よりもMCDRAMを用いた場合の方が高い。メモリバンド幅ネックな計算なので妥当な結果と考えられる
となります。
ちなみに、フラットMPI並列だとどのくらいの高速化率なのか気になる人もいると思うので記しておくと、DDR4で32倍、MCDRAMで84倍でした。スレッド並列化でもこれくらい速くすることが目標となるわけですが、現状だと全然足りてないですね。
今後の予定
個々の処理を見ると十分に高速化できているものもありますが、一部の処理(DIC前処理・Cuthill-McKee法)がボトルネックとなり、全体でみるとまだまだ高速化が必要なのが現状です。そのため、今後も引き続き高速化に取り組んでいきます。

Tags
About Author
TomiokaMinoru
Leave a Comment
Tags
Favorite Post

 2017年8月22日
2017年8月22日 2017年10月31日
2017年10月31日
Archives
- 2024年2月
- 2024年1月
- 2023年12月
- 2023年6月
- 2023年5月
- 2023年4月
- 2023年2月
- 2023年1月
- 2022年12月
- 2022年10月
- 2021年11月
- 2021年9月
- 2021年6月
- 2021年3月
- 2021年2月
- 2020年12月
- 2020年10月
- 2020年7月
- 2020年6月
- 2020年5月
- 2020年4月
- 2020年3月
- 2020年2月
- 2020年1月
- 2019年12月
- 2019年11月
- 2019年10月
- 2019年9月
- 2019年8月
- 2019年6月
- 2019年4月
- 2019年3月
- 2019年2月
- 2019年1月
- 2018年12月
- 2018年11月
- 2018年10月
- 2018年8月
- 2018年6月
- 2018年5月
- 2018年4月
- 2018年3月
- 2018年2月
- 2017年12月
- 2017年11月
- 2017年10月
- 2017年9月
- 2017年8月
- 2017年7月
- 2017年6月
- 2017年5月
- 2017年3月
- 2016年12月
- 2016年11月
- 2016年8月
- 2016年7月
- 2016年3月
- 2016年2月
- 2016年1月
- 2015年12月
- 2015年11月
- 2015年10月
- 2015年8月
- 2015年6月
- 2015年3月
- 2015年2月
- 2015年1月
- 2014年12月
- 2014年11月
コンピュータビジョンセミナーvol.2 開催のお知らせ - ニュース一覧 - 株式会社フィックスターズ in Realizing Self-Driving Cars with General-Purpose Processors 日本語版
[…] バージョンアップに伴い、オンラインセミナーを開催します。 本セミナーでは、�...
【Docker】NVIDIA SDK Managerでエラー無く環境構築する【Jetson】 | マサキノート in NVIDIA SDK Manager on Dockerで快適なJetsonライフ
[…] 参考:https://proc-cpuinfo.fixstars.com/2019/06/nvidia-sdk-manager-on-docker/ […]...
Windowsカーネルドライバを自作してWinDbgで解析してみる① - かえるのほんだな in Windowsデバイスドライバの基本動作を確認する (1)
[…] 参考:Windowsデバイスドライバの基本動作を確認する (1) - Fixstars Tech Blog /proc/cpuinfo ...
2021年版G検定チートシート | エビワークス in ニューラルネットの共通フォーマット対決! NNEF vs ONNX
[…] ONNX(オニキス):Open Neural Network Exchange formatフレームワーク間のモデル変換ツー�...
YOSHIFUJI Naoki in CUDAデバイスメモリもスマートポインタで管理したい
ありがとうございます。別に型にこだわる必要がないので、ユニバーサル参照を受けるよ...