このブログは、株式会社フィックスターズのエンジニアが、あらゆるテーマについて自由に書いているブログです。
【TensorRT やってみた】(4): GoogLeNet で性能を検証する
遠藤です。
TensorRT やってみたシリーズの締めくくりとして、実際に推論を実行した結果を報告します。
使用したネットワークについて
今回使用したネットワークは 2014 年の ILSVRC で優勝した GoogLeNet です。22層からなるネットワークで、 Inception module というモジュールで複数のカーネルサイズのコンボリューションをパラレルに適用している点が特徴です。
GoogLeNet にはたくさんのレイヤがありますが、それらの理論計算量を求めると、バッチサイズ 1 の 224×224 の入力データに対しておよそ 2GFLOPs となります。
理論計算量については、各ネットワークの理論計算量を検討した下記リポジトリも参考になります。
albanie/convnet-burden
convnet-burden – Memory consumption and FLOP count estimates for convnets
使用した計測コードについて
今回は、Caffe の example にある cpp_classification をベースに、
- NVCaffe を用いた推論 (単精度浮動小数点、FP32)
- TensorRT を用いた推論 (FP32)
- TensorRT を用いた推論 (半精度浮動小数点、FP16)
の3パターンで計測する計測コードを書きました。計測コードは以下のリポジトリにて公開しております。
fixstars / blog / source / tensorrt_sample – Bitbucket
各推論プログラムは、以下のパラメータをとります。 1. 学習済み Caffe モデルの prototxt 2. 学習済み Caffe モデルの caffemodel 3. 平均画素の binaryproto 4. ラベル一覧 5. 推論対象画像ファイル 6. バッチサイズ (TensorRT 版のみ)
計測結果
Jetson TX1 と Jetson TX2 を用いて測定した結果を以下に示します。Jetson TX2 は新しいバージョンの JetPack が使えるので、JetPack のバージョン(3.1 / 3.2 DP) を両方試し、違いがないか確認しました。以下の表の計測時間の単位は、すべてマイクロ秒 (us) です。
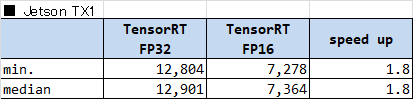
■ Jetson TX1 w/ JetPack 3.1
Jetson TX1 における計測結果を以下の表に示します。

ポイントは
- Caffe と TensorRT を比べると、TensorRT は処理が約3.5倍速い
- ピーク性能は 1.0 (GHz) * 256 (CUDA cores) * 2 (FLOP/cycle) = 512GFLOP/s
→ 理論計算時間は 2GFLOP / 512GFLOP/s ~= 4ms
→ 理論ピーク性能と比べると3倍ほどかかっている
でした。
■ Jetson TX2 w/ JetPack 3.1
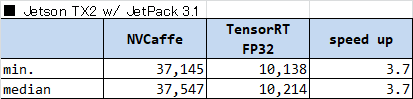
Jetson TX2 (JetPack 3.1) における計測結果を以下の表に示します。
ポイントは
- Caffe と TensorRT を比べると、TensorRT は処理が約3.7倍速い
- ピーク性能は 1.3 (GHz) * 256 (CUDA cores) * 2 (FLOP/cycle) = 665.6GFLOP/s
→ 理論計算時間は 2GFLOP / 665.6GFLOP/s ~= 3ms
→ 理論ピーク性能と比べると3倍ほどかかっている
でした。
■ Jetson TX2 w/ JetPack 3.2DP
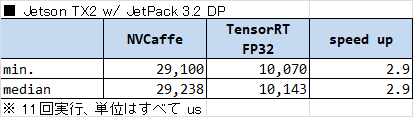
Jetson TX2 (JetPack 3.2) における計測結果を以下の表に示します。
ポイントは
- Caffe の処理時間が JetPack のバージョン間で約1.3倍高速になった
→ cuDNN のバージョンアップが寄与していると考えられる - TensorRT の処理時間は変わらなかった
でした。
考察
上記の計測結果や、計測時にとったプロファイル結果等から分かったことをまとめたいと思います。
Jetson TX1 と TX2 の処理性能の違いについて
Jetson TX1 と TX2 の処理時間を比較すると、およそ1.3倍の違いがありました。Jetson TX1 は GPU のクロック周波数が 1GHz であるのに対し、Jetson TX2 はクロック周波数が 1.3GHz ですので、クロック周波数の違いがそのまま見えた形となりました。
Jetson TX1 と TX2 では GPU の世代が Maxwell から Pascal にアップグレードされていますが、搭載されている個々の CUDA コア自体に大きな変更はなく、処理性能の観点で世代間の違いは見られませんでした。おそらく電力性能には影響があると思いますが、機材の関係上測定できませんでした。
Caffe と比べ TensorRT はどこが速くなったのか
Caffe と TensorRT の処理時間について、プロファイラで内訳をとりました。プロファイル結果を以下に示します。実行環境は Jetson TX1 です。

分かったことをまとめると、次のようになります。
- Caffe では各レイヤのカーネルが同期実行されているため、カーネルの起動と同期待ちコストが非常に重くなっている (半分以上がカーネル起動・同期待ちに費やされている!)
- TensorRT では 各カーネルが非同期で実行されているため、カーネル起動・同期待ちがほとんど発生していない
- コンボリューションと活性化関数の処理が、1.7倍高速化された
- プーリング処理が1.9倍高速化された
- デバイス内のメモリコピーなど、その他の処理時間が3倍以上高速化された
一番処理の重い conv2/3×3 レイヤの処理時間を比較すると、Caffe ではコンボリューションの時間に 1.9ms 、バイアス加算と活性化関数の計算にそれぞれ 260us かかっている一方で、 TensorRT ではトータルで 1.8ms となっていました。TensorRT では Layer Fusing によりコンボリューションから活性化関数までが一つのレイヤで計算されているため、処理時間の内訳は分かりませんが、コンボリューション単体の高速化と Layer Fusing 双方が効いているものと思われます。
Caffe でも TensorRT でも、ネットワークの各レイヤごとにカーネルが実行されます。特に Caffe では各レイヤでもコンボリューション・バイアス加算・活性化関数が別カーネルとなっているので、実行されるカーネルの総数は非常に多いです。小さいカーネルが何度も起動されるため、同期実行は非常にコストがかかることが分かりました。
FP32 と FP16 で性能と推論結果がどう変わるか
TensorRT で FP32 と FP16 の推論を実行した際の計測結果を以下に示します。
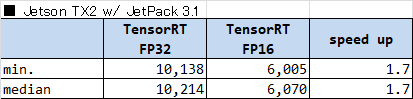
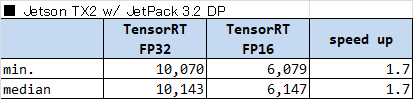 どの環境においても完全に2倍にはならなかったものの、ほぼ2倍といえる性能向上が見られました。
どの環境においても完全に2倍にはならなかったものの、ほぼ2倍といえる性能向上が見られました。
いくら性能が向上したからと言って、推論結果がでたらめになってしまっては何の意味もありません。そこで、次にFP32 と FP16 でそれぞれ実行した際の推論結果を以下に示します。
■ FP32
0.5009 - "n02123159 tiger cat"
0.2283 - "n02123045 tabby, tabby cat"
0.1612 - "n02124075 Egyptian cat"
0.0283 - "n02127052 lynx, catamount"
0.0134 - "n02123394 Persian cat"
■ FP16
0.4988 - "n02123159 tiger cat"
0.2284 - "n02123045 tabby, tabby cat"
0.1620 - "n02124075 Egyptian cat"
0.0286 - "n02127052 lynx, catamount"
0.0135 - "n02123394 Persian cat"
当然完全一致はしないものの、ほぼ同様の推論結果を得ることができました。使用するネットワークや解きたいタスクによって変わるものの、少なくとも GoogLeNet を用いた分類問題では、FP16 でも十分な精度を得ることができました。
まとめ
ここまで得られた知見をまとめます。
- TensorRT は NVCaffe より 3~4 倍速い
- TensorRT でも、理論性能と比べると3倍ほどはかかる (が、十分速い)
- FP16にすることで、さらに2倍近い性能が簡単に得られる
精度上の影響は問題によるが、今回の検証では大きな問題は見られなかった - Jetson TX1 と TX2 では、クロック向上分の性能向上が見られる
- cuDNN を利用するアプリケーションは、JetPack 3.2 でライブラリを更新することで、性能向上が見られる
- カーネルの同期実行はコストが高い、可能な限り非同期実行をすることが望ましい
TensorRT は NVCaffe に比べ処理速度が 3~4 倍速く、FP16 にするとさらにその2倍近く早くなることが分かりました。TensorRT の適用は比較的簡単ですので、推論コードを少し書き換えるだけでこの速さが実現されるのはとてもすごいと思いました。NVIDIA 環境でディープラーニングの推論を試す際には、ぜひともご利用ください!

Tags
About Author
yasunori.endo
Leave a Comment
Tags
Favorite Post

 2017年8月22日
2017年8月22日 2017年10月31日
2017年10月31日
Archives
- 2024年2月
- 2024年1月
- 2023年12月
- 2023年6月
- 2023年5月
- 2023年4月
- 2023年2月
- 2023年1月
- 2022年12月
- 2022年10月
- 2021年11月
- 2021年9月
- 2021年6月
- 2021年3月
- 2021年2月
- 2020年12月
- 2020年10月
- 2020年7月
- 2020年6月
- 2020年5月
- 2020年4月
- 2020年3月
- 2020年2月
- 2020年1月
- 2019年12月
- 2019年11月
- 2019年10月
- 2019年9月
- 2019年8月
- 2019年6月
- 2019年4月
- 2019年3月
- 2019年2月
- 2019年1月
- 2018年12月
- 2018年11月
- 2018年10月
- 2018年8月
- 2018年6月
- 2018年5月
- 2018年4月
- 2018年3月
- 2018年2月
- 2017年12月
- 2017年11月
- 2017年10月
- 2017年9月
- 2017年8月
- 2017年7月
- 2017年6月
- 2017年5月
- 2017年3月
- 2016年12月
- 2016年11月
- 2016年8月
- 2016年7月
- 2016年3月
- 2016年2月
- 2016年1月
- 2015年12月
- 2015年11月
- 2015年10月
- 2015年8月
- 2015年6月
- 2015年3月
- 2015年2月
- 2015年1月
- 2014年12月
- 2014年11月
コンピュータビジョンセミナーvol.2 開催のお知らせ - ニュース一覧 - 株式会社フィックスターズ in Realizing Self-Driving Cars with General-Purpose Processors 日本語版
[…] バージョンアップに伴い、オンラインセミナーを開催します。 本セミナーでは、�...
【Docker】NVIDIA SDK Managerでエラー無く環境構築する【Jetson】 | マサキノート in NVIDIA SDK Manager on Dockerで快適なJetsonライフ
[…] 参考:https://proc-cpuinfo.fixstars.com/2019/06/nvidia-sdk-manager-on-docker/ […]...
Windowsカーネルドライバを自作してWinDbgで解析してみる① - かえるのほんだな in Windowsデバイスドライバの基本動作を確認する (1)
[…] 参考:Windowsデバイスドライバの基本動作を確認する (1) - Fixstars Tech Blog /proc/cpuinfo ...
2021年版G検定チートシート | エビワークス in ニューラルネットの共通フォーマット対決! NNEF vs ONNX
[…] ONNX(オニキス):Open Neural Network Exchange formatフレームワーク間のモデル変換ツー�...
YOSHIFUJI Naoki in CUDAデバイスメモリもスマートポインタで管理したい
ありがとうございます。別に型にこだわる必要がないので、ユニバーサル参照を受けるよ...