このブログは、株式会社フィックスターズのエンジニアが、あらゆるテーマについて自由に書いているブログです。
収束加速法の紹介
メモリ事業部の 眞鍋 です。
本日は 「収束加速法」という話題を取り上げたいと思います。
同じ結果を得るにしても、その目的に特化することで高速にする技法、というのは世の中にたくさんあります。
例えば代表的なものは各種ソートアルゴリズムたちであり、
本ブログでも紹介されている「Segment Tree」につきましても、
ある目的に対して計算量を抑えることのできる技法です。
詳しくは記事をご覧ください!
こうしたアルゴリズムは、例えば 蟻本 などのプログラミング本で紹介されており、勉強することができます。
今回紹介する「収束加速法」は、
こうした本には載っていない話であり、
どちらかといえばコンピューター界隈の方からするとメジャーではない話だと思いますが、
目的はこうしたアルゴリズムと同じ内容になります。
説明の前に、
例えばどういったことに使えるのでしょうか?
応用:Google Page Rank の計算高速化
Google の創始者である Brin と Page は、
例えば The Anatomy of a Large-Scale Hypertextual Web Search Engine という論文の中で
ある行列の固有値を引き離すための (収束の速さを改善するための)
ハイパーパラメータを用意し、その値を 0.85 として計算することで、
「超々大規模な」疎行列の乗算回数を劇的に減らし高速化を行いました。
あまりにも大規模な行列のため、一回の行列演算を省くだけでとてつもない高速化になります。
この Brin と Page の方法をさらに高速化するために、
今回紹介する「収束加速法」を使ってさらに高速化する研究が知られています。
例えば Google’s PageRank and Beyond: The Science of Search Engine Rankings という
PageRank アルゴリズムに関する歴史・背景などを詳しく書いている本には、
この収束加速法を適用する話に 1章使っています (Chapter 9. Accelerating the Computation of PageRank)
つまり 収束を加速することで、計算回数を劇的に減らす技法、というのが「収束加速法」であります。
PageRankアルゴリズムを題材にするにはいささか導入に時間がかかりますので、
おもちゃで遊んでみたいと思います。
おもちゃで収束加速法を体験しよう
有名な式にライプニッツ級数というものがあります。
この式で円周率の計算をするのはいい方法とは言えませんが、
この式を題材として扱ってみたいと思います。
ライプニッツ級数:
$$\pi = \displaystyle 4\sum_{n=0}^\infty \frac{(-1)^n}{2n+1}$$
この級数は $\pi $ に収束する級数なのですが非常に非常に収束測度が遅いことで有名です。
その収束の遅さをみるために次をご覧ください:

例えば 10000 項の結果を使った
$$\frac{4}{1} – \frac{4}{3} + \frac{4}{5} – \frac{4}{7} + \frac{4}{9} + \dotsb + \frac{4}{20001}$$
を計算しても $3.141$ までの結果しか得られません。
収束を改善してみる!
n = 9 までで得られた結果のみを使って、収束精度を上げてみます。
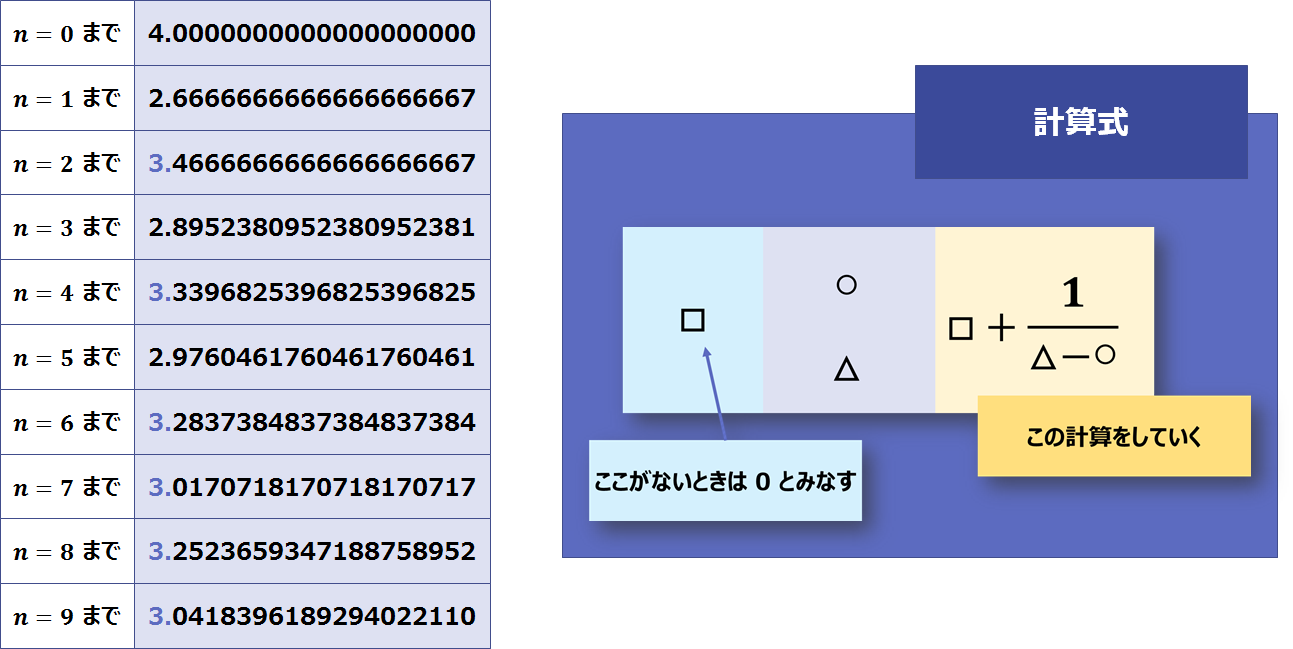
使う計算式は上図の ○・△・□の式で、適用してみます:

もう一度適用してみます:
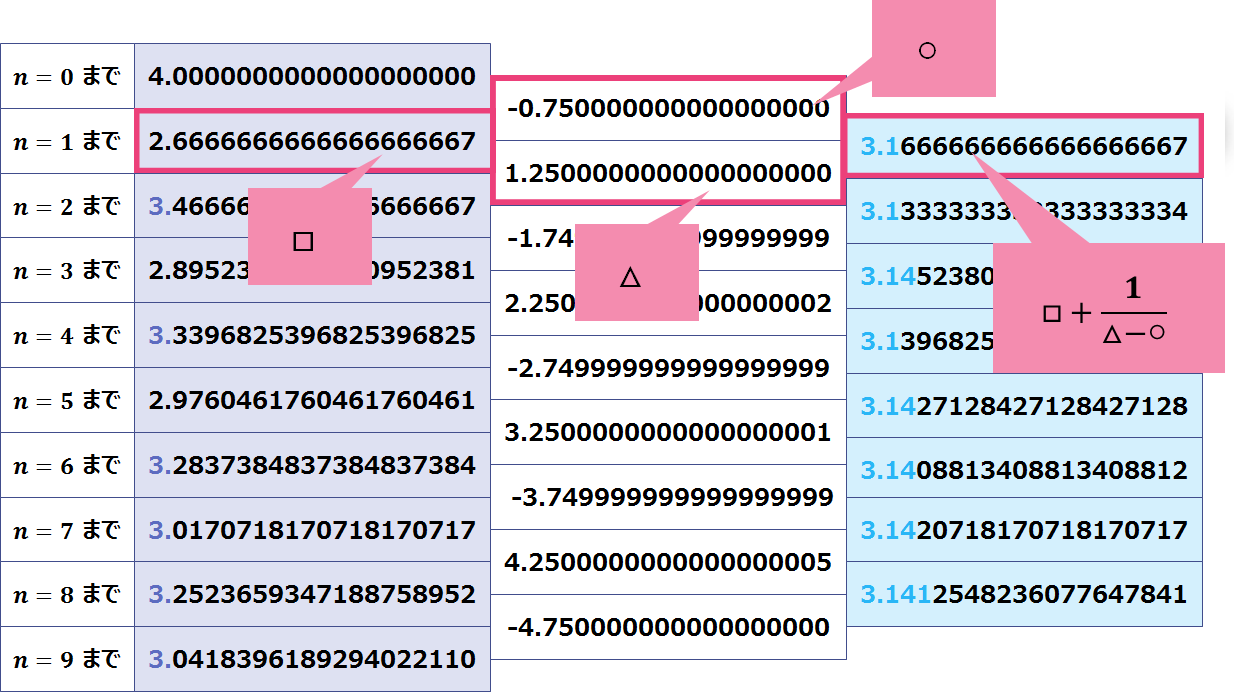
この操作で、何故か改善された結果を得られました。
さらにこれを繰り返しますと次のような結果になります:

つまり、9項の情報だけで 「3.141592」と 7桁精度が得られました。
先ほどは愚直に 10000項の計算で 4桁精度しか得られていないことを考えると黒魔術的です!
さらに遊んでみる!
上のアルゴリズム、ライプニッツ級数にしか使えないような特殊な計算なのでは?
という心の声が聞こえてきそうです。
そうではないことを、別の話で遊んでみましょう。
$$\sum_{n=0}^\infty (-1)^n (n+1) = 1-2+3-4+5-\dotsb$$
という式は何を表しているかご存知でしょうか?
高校数学までは、収束しない、つまり「発散級数」と習います。
しかしながら、wikipedia の「1-2+3-4+・・・」をみてみますと次のように書かれています:
しかし計算方法によってはこの級数が収束すると考えることもでき、その場合の収束値は 1/4 である。
すなわち、 1/4 に収束する数とみなす考え方もあるんだ!ということがわかります。
詳細を知りたい方はゼータ関数などを勉強いただければと思います。
この数をこの方法で計算するとどうなるのでしょうか。
まずは先ほどと同様に部分的に計算した数を用意します。

これに先ほどの計算を行うと?
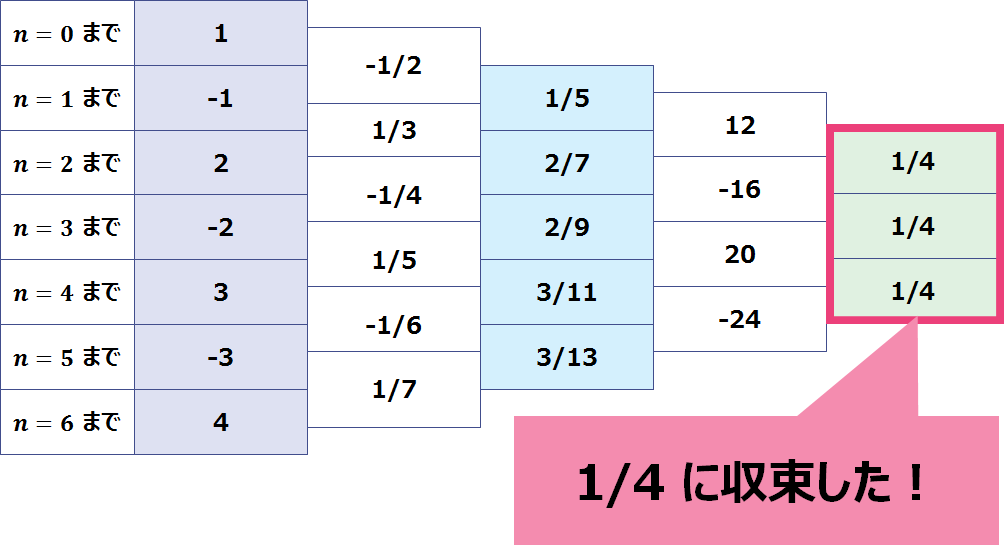
そうなのです。 1/4 になるのです!
面白いですね!
まとめ
- Google Page Rank アルゴリズムをとりあげ収束加速法の応用事例を紹介した
- 収束加速法の感覚を理解するために「ライプニッツ級数」で遊んでみた
- 発散級数にも適用できた
Fixstars ではこうした技も駆使して高速化しております!
興味のある方は是非一緒に仕事しましょう。
よろしくお願いします。

Tags
About Author
shugo
Leave a Comment
Tags
Favorite Post

 2017年8月22日
2017年8月22日 2017年10月31日
2017年10月31日
Archives
- 2024年2月
- 2024年1月
- 2023年12月
- 2023年6月
- 2023年5月
- 2023年4月
- 2023年2月
- 2023年1月
- 2022年12月
- 2022年10月
- 2021年11月
- 2021年9月
- 2021年6月
- 2021年3月
- 2021年2月
- 2020年12月
- 2020年10月
- 2020年7月
- 2020年6月
- 2020年5月
- 2020年4月
- 2020年3月
- 2020年2月
- 2020年1月
- 2019年12月
- 2019年11月
- 2019年10月
- 2019年9月
- 2019年8月
- 2019年6月
- 2019年4月
- 2019年3月
- 2019年2月
- 2019年1月
- 2018年12月
- 2018年11月
- 2018年10月
- 2018年8月
- 2018年6月
- 2018年5月
- 2018年4月
- 2018年3月
- 2018年2月
- 2017年12月
- 2017年11月
- 2017年10月
- 2017年9月
- 2017年8月
- 2017年7月
- 2017年6月
- 2017年5月
- 2017年3月
- 2016年12月
- 2016年11月
- 2016年8月
- 2016年7月
- 2016年3月
- 2016年2月
- 2016年1月
- 2015年12月
- 2015年11月
- 2015年10月
- 2015年8月
- 2015年6月
- 2015年3月
- 2015年2月
- 2015年1月
- 2014年12月
- 2014年11月
コンピュータビジョンセミナーvol.2 開催のお知らせ - ニュース一覧 - 株式会社フィックスターズ in Realizing Self-Driving Cars with General-Purpose Processors 日本語版
[…] バージョンアップに伴い、オンラインセミナーを開催します。 本セミナーでは、�...
【Docker】NVIDIA SDK Managerでエラー無く環境構築する【Jetson】 | マサキノート in NVIDIA SDK Manager on Dockerで快適なJetsonライフ
[…] 参考:https://proc-cpuinfo.fixstars.com/2019/06/nvidia-sdk-manager-on-docker/ […]...
Windowsカーネルドライバを自作してWinDbgで解析してみる① - かえるのほんだな in Windowsデバイスドライバの基本動作を確認する (1)
[…] 参考:Windowsデバイスドライバの基本動作を確認する (1) - Fixstars Tech Blog /proc/cpuinfo ...
2021年版G検定チートシート | エビワークス in ニューラルネットの共通フォーマット対決! NNEF vs ONNX
[…] ONNX(オニキス):Open Neural Network Exchange formatフレームワーク間のモデル変換ツー�...
YOSHIFUJI Naoki in CUDAデバイスメモリもスマートポインタで管理したい
ありがとうございます。別に型にこだわる必要がないので、ユニバーサル参照を受けるよ...