このブログは、株式会社フィックスターズのエンジニアが、あらゆるテーマについて自由に書いているブログです。
第1回AIチャレンジコンテスト参加記 (分類部門)
はじめに
こんにちは、takagiです。
このたび、内閣府などが主催する第1回AIチャレンジコンテストに社内チームで参加してきました。
これはクックパッドの提供する画像データを使用して、料理の領域検出・料理の分類モデルを作成し、その精度を競うものです。
ここでは私が担当した料理分類部門についてもう少し詳しく書きたいと思います。
料理分類部門のルール
料理分類部門では、10,000枚の料理画像を25個のカテゴリに分類して、その正解率を競います。
そもそも料理の画像認識は同じ料理でも形状や使われている素材にばらつきが多く、比較的難しい領域なんだそうです。
学習データ
正解ラベルが付与された画像(教師データ)が10,000枚と、ラベルのないものが50,000枚与えられます。
教師データは10,000枚ありますが、通常はこれを学習用と検証用に分割し、学習用データを使ってモデルを学習、検証用データでモデルの性能を評価します。ラベルなしのデータは料理画像の特徴検出などに使用します。
テストデータ
テスト画像は10,000枚です。
モデルを作成したらテスト画像を分類して、その結果をコンテストサイトに投稿します。
しばらくすると運営からスコアが通知され、ランキングに反映されます。
懸賞/賞金
最高精度賞とアイデア賞があり、最高精度賞では単純に分類の精度で順位が決まります。
アイデア賞ではモデルのレポートを提出し、審査によって順位が決まります。
最高精度賞
- 1位:NVIDIA TITAN X
- 2,3位:nintendo New3DS-LL
- 4,5位:nintendo 2DS
- 6-10位:ノベルティ詰合せ
アイデア賞
- 1位:賞金10万円+ノベルティ
- 2,3位:GeForce GTX 1060 6GB
- 4,5位:GeForce GTX 1060 3GB
料理分類部門でやったこと
ここからは料理分類部門で社内チームが作成したモデルについて解説します。
前提として、我々のアプローチはディープラーニングが基本になってます。ディープラーニングそのものについては、ここでは説明しきれませんのでご了承下さい。ルール上手法の選択は自由ですが、昨今の画像認識の実績からするとほとんどのチームはディープラーニングを使用していたのではないかと思います。
フレームワーク選び
今やディープラーニングのフレームワークは溢れかえっていて、素人の私はまずフレームワーク選びから始めました。
調べた結果、初心者でも使いやすそうなのはChainerかKerasのようです。社内ではChainerを使ってるという人は結構いると聞いてたので、私はなんとなくみんなが使ったことのなさそうなKerasを使ってみることにしました(結果的にKerasを選んだのは当たりでした)。
モデル
Kerasの作者であり、GoogleのエンジニアであるFrançois Chollet氏が発明したXceptionというモデルを使用しました。
論文によると、XceptionはImageNetという有名な画像分類のデータセットに対し、これまた有名なモデルであるVGG、Inception V3、ResNetよりも高い認識精度を達成しているとのことです。
【参考】ImageNetのTop5エラー率の推移
出典:https://www.slideshare.net/mlprague/xuedong-huang-deep-learning-and-intelligent-applications p.7
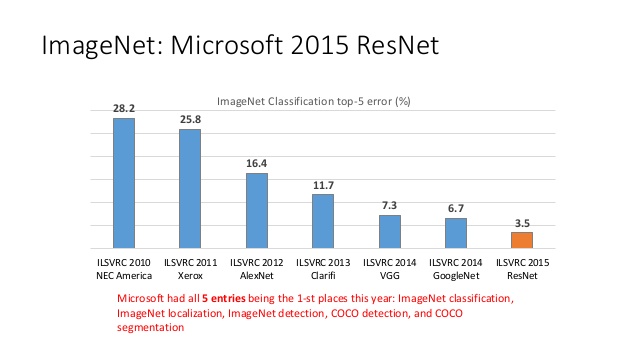
KerasではXceptionの他、有力なモデルが学習済みの重みと共に提供されており、それが他のフレームワークにない魅力の一つではないかと思います。
ファインチューニング
学習の際、別のデータセットで事前学習した重みを初期値として利用することをファインチューニングといい、少ないデータでも効率よく学習できるメリットがあります。実際、ファインチューニングあり/なしでは、ありの方がずっとスコアが良かったと思います。我々はKerasで提供されているImageNetの重みを初期値として使用しました。
Data Augmentation
学習データを変形(回転、鏡像反転、拡縮など)させてデータを水増しすることをData Augmentationといい、少ないデータで汎化性能を上げるための有名な手法です。
解像度別のモデル作成
Xceptionのデフォルトの入力解像度は299×299ですが、料理領域検出部門において入力解像度を大きくしたらススコアが伸びて5位以内に入ったという出来事があったので分類の方でも解像度を大きくして試してみることにしました。
実際、解像度を399×399に広げたところ結構スコアが上がりました。こうなると色々な入力解像度で試してベストなものを見つけたくなります。学習には時間が半日ほどかかるので、コンテスト終了間際には社内のGPUを4台動かし続けて色々な入力解像度のモデルを作成していました。
モデル平均
ニューラルネットは入力画像がそれぞれのカテゴリ(今回は25個)に属する確率を出力するため、このうち最も確率の高かったカテゴリを推論(ここでは画像を分類すること)の結果とします。モデル平均は複数の異なるモデルが出力した確率を平均することで、推論精度を向上させるテクニックです。一人の意見よりも多人数の意見を反映した方が信頼できる、というイメージです。
我々は先述の色々な入力解像度で学習したモデルの出力を、重みつき平均することにしました。重みは検証用データに対して精度が良くなるよう、粒子群最適化という手法で最適化しました。
Test Time Augmentation (TTA)
モデル平均同様、推論精度を向上させるテクニックです。
これはモデルを複数用意する代わりに、入力画像をData Augmentationで変形させて複数用意しそれぞれの画像に対する確率を平均します。TTAはKaggleのプランクトン画像分類で優勝したチームの記事で知りました。
ソース
参考までに、学習に用いたpythonスクリプトを載せておきます。
フレームワークが提供する機能のおかげで、初心者でもほとんど苦労なく書くことができました。
from __future__ import print_function
import csv
import sys
import os
import numpy as np
from PIL import Image
from argparse import ArgumentParser
from keras.applications.xception import Xception
from keras.models import Model
from keras.layers import Dense, GlobalAveragePooling2D
from keras.optimizers import SGD
from keras.preprocessing.image import ImageDataGenerator
from keras.utils import np_utils
from keras.callbacks import CSVLogger, ModelCheckpoint
def Parser():
parser = ArgumentParser()
parser.add_argument('--image_size', default=299)
parser.add_argument('--validation_set', default=1)
parser.add_argument('--dataset_path', default='/dataset/AI_Challenge_Contest_2017/02_classification/')
parser.add_argument('--batch_size_pre', default=32)
parser.add_argument('--batch_size_fine', default=16)
parser.add_argument('--nb_epoch_pre', default=5)
parser.add_argument('--nb_epoch_fine', default=100)
parser.add_argument('--output_path', default='output')
parser.add_argument('--device_id', default=0)
return parser
class DataLoader():
def __init__(self, image_size, validation_range, dataset_path):
self.image_size = image_size
self.dataset_path = dataset_path
self.validation_range = validation_range
def load_data(self):
reader = csv.reader(open(self.dataset_path + '/clf_train_master.tsv', 'r'), delimiter='\t')
header = next(reader)
train_images = []
train_labels = []
validation_images = []
validation_labels = []
for i, row in enumerate(reader):
# load image
image_name = str(row[0])
image_path = '/clf_train_images_labeled_1/' if i < 5000 else '/clf_train_images_labeled_2/'
image = Image.open(self.dataset_path + image_path + image_name)
image = image.resize((self.image_size, self.image_size))
# load label
label = int(row[1])
# assign data (training or validation)
if i in self.validation_range:
validation_images.append(np.array(image))
validation_labels.append(label)
else:
train_images.append(np.array(image))
train_labels.append(label)
if i % 100 == 0:
print('loaded ' + str(i) + ' images')
train_images = np.array(train_images)
train_labels = np.array(train_labels)
validation_images = np.array(validation_images)
validation_labels = np.array(validation_labels)
return (train_images, train_labels), (validation_images, validation_labels)
def createImageDataGenerator():
return ImageDataGenerator(
rescale=1./255,
featurewise_center=False, # set input mean to 0 over the dataset
samplewise_center=False, # set each sample mean to 0
featurewise_std_normalization=False, # divide inputs by std of the dataset
samplewise_std_normalization=False, # divide each input by its std
zca_whitening=False, # apply ZCA whitening
rotation_range=45, # randomly rotate images in the range (degrees, 0 to 180)
width_shift_range=0.125, # randomly shift images horizontally (fraction of total width)
height_shift_range=0.125, # randomly shift images vertically (fraction of total height)
horizontal_flip=True, # randomly flip images
zoom_range=0.5,
vertical_flip=False) # randomly flip images
if __name__ == "__main__":
# contants
nb_classes = 25
validation_ranges = [range(8000, 10000), range(6000, 8000), range(4000, 6000), range(2000, 4000), range(0, 2000)]
# parse args
options = Parser().parse_args()
image_size = int(options.image_size)
validation_set = int(options.validation_set)
dataset_path = options.dataset_path
batch_size_pre = int(options.batch_size_pre)
batch_size_fine = int(options.batch_size_fine)
nb_epoch_pre = int(options.nb_epoch_pre)
nb_epoch_fine = int(options.nb_epoch_fine)
output_path = options.output_path
device_id = int(options.device_id)
validation_range = validation_ranges[validation_set - 1]
train_name = 'set' + str(validation_set) + '_' + str(image_size)
print('image size :', image_size)
print('validation set : {} ({} to {})'.format(validation_set, validation_range[0], validation_range[-1]))
print('dataset path :', dataset_path)
print('batch size (pre-training) :', batch_size_pre)
print('batch size (fine-tuning) :', batch_size_fine)
print('number of epochs (pre-training) :', nb_epoch_pre)
print('number of epochs (fine-tuning) :', nb_epoch_fine)
print('output path :', output_path)
print('gpu device id :', device_id)
print('train name :', train_name)
# set gpu device
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = str(device_id)
# The data, shuffled and split between train and test sets:
loader = DataLoader(image_size, validation_range, dataset_path)
(X_train, y_train), (X_test, y_test) = loader.load_data()
print('X_train shape:', X_train.shape)
print(X_train.shape[0], 'train samples')
print(X_test.shape[0], 'test samples')
# Convert class vectors to binary class matrices.
Y_train = np_utils.to_categorical(y_train, nb_classes)
Y_test = np_utils.to_categorical(y_test, nb_classes)
X_test = X_test.astype('float32')
X_test /= 255
# create the base pre-trained model
base_model = Xception(weights='imagenet', include_top=False)
# add a global spatial average pooling layer
x = base_model.output
x = GlobalAveragePooling2D()(x)
# let's add a fully-connected layer and a logistic layer -- let's say we have 25 classes
predictions = Dense(nb_classes, activation='softmax')(x)
# this is the model we will train
model = Model(input=base_model.input, output=predictions)
# first: train only the top layers (which were randomly initialized)
# i.e. freeze all convolutional Xception layers
for layer in base_model.layers:
layer.trainable = False
# compile the model (should be done *after* setting layers to non-trainable)
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
# callbacks
if not os.path.exists(output_path):
os.mkdir(output_path)
logger_pre = CSVLogger(output_path + '/' + train_name + '_training_pre.csv')
logger_fine = CSVLogger(output_path + '/' + train_name + '_training_fine.csv')
checkpointer = ModelCheckpoint(filepath=output_path + '/' + train_name + '.hdf5', verbose=1, save_best_only=True)
##################################################################################################
# pre-training
##################################################################################################
print('Using real-time data augmentation.')
# This will do preprocessing and realtime data augmentation:
datagen = createImageDataGenerator()
# Compute quantities required for featurewise normalization
# (std, mean, and principal components if ZCA whitening is applied).
datagen.fit(X_train)
# Fit the model on the batches generated by datagen.flow().
model.fit_generator(datagen.flow(X_train, Y_train, batch_size=batch_size_pre),
samples_per_epoch=X_train.shape[0],
nb_epoch=nb_epoch_pre,
callbacks=[logger_pre],
validation_data=(X_test, Y_test))
##################################################################################################
# fine-tuning
##################################################################################################
# we chose to train all layers
for layer in model.layers:
layer.trainable = True
# we need to recompile the model for these modifications to take effect
# we use SGD with a low learning rate
model.compile(optimizer=SGD(lr=0.0001, momentum=0.9), loss='categorical_crossentropy', metrics=['accuracy'])
# we train our model again (this time fine-tuning all layers)
print('Using real-time data augmentation.')
# This will do preprocessing and realtime data augmentation:
datagen = createImageDataGenerator()
# Compute quantities required for featurewise normalization
# (std, mean, and principal components if ZCA whitening is applied).
datagen.fit(X_train)
# Fit the model on the batches generated by datagen.flow().
model.fit_generator(datagen.flow(X_train, Y_train, batch_size=batch_size_fine),
samples_per_epoch=X_train.shape[0],
nb_epoch=nb_epoch_fine,
callbacks=[logger_fine, checkpointer],
validation_data=(X_test, Y_test))結果
テストデータに対する正解率は最終的に78%くらいで、9位に入賞しました。
振り返ると、Xeptionとファインチューニングで20位以内に入り、その他の工夫で着々とスコアと順位を伸ばしていったかなと思います。
やりのこしたこと
学習データのうち、ラベルなしの画像50,000枚を有効活用できなかったのが残念でした。
教師なし学習で料理の特徴を抽出したり、半教師あり学習で擬似的な訓練データとして利用するといったアイデアは試していたのですが、成果が出る前にコンテスト終了を迎えてしまいました。
おわりに
料理分類部門で取り組んだことについて解説しました。
コンテストに参加する前はディープラーニングについて本で読んだ知識しかなかったので、実際にやってみることはとても良い勉強になりました。
これからディープラーニングを勉強したい方は、こういったコンテストに参加してみてはいかがでしょうか。

Tags
About Author
takagi
Leave a Comment
Tags
Favorite Post

 2017年8月22日
2017年8月22日 2017年10月31日
2017年10月31日
Archives
- 2024年2月
- 2024年1月
- 2023年12月
- 2023年6月
- 2023年5月
- 2023年4月
- 2023年2月
- 2023年1月
- 2022年12月
- 2022年10月
- 2021年11月
- 2021年9月
- 2021年6月
- 2021年3月
- 2021年2月
- 2020年12月
- 2020年10月
- 2020年7月
- 2020年6月
- 2020年5月
- 2020年4月
- 2020年3月
- 2020年2月
- 2020年1月
- 2019年12月
- 2019年11月
- 2019年10月
- 2019年9月
- 2019年8月
- 2019年6月
- 2019年4月
- 2019年3月
- 2019年2月
- 2019年1月
- 2018年12月
- 2018年11月
- 2018年10月
- 2018年8月
- 2018年6月
- 2018年5月
- 2018年4月
- 2018年3月
- 2018年2月
- 2017年12月
- 2017年11月
- 2017年10月
- 2017年9月
- 2017年8月
- 2017年7月
- 2017年6月
- 2017年5月
- 2017年3月
- 2016年12月
- 2016年11月
- 2016年8月
- 2016年7月
- 2016年3月
- 2016年2月
- 2016年1月
- 2015年12月
- 2015年11月
- 2015年10月
- 2015年8月
- 2015年6月
- 2015年3月
- 2015年2月
- 2015年1月
- 2014年12月
- 2014年11月
コンピュータビジョンセミナーvol.2 開催のお知らせ - ニュース一覧 - 株式会社フィックスターズ in Realizing Self-Driving Cars with General-Purpose Processors 日本語版
[…] バージョンアップに伴い、オンラインセミナーを開催します。 本セミナーでは、�...
【Docker】NVIDIA SDK Managerでエラー無く環境構築する【Jetson】 | マサキノート in NVIDIA SDK Manager on Dockerで快適なJetsonライフ
[…] 参考:https://proc-cpuinfo.fixstars.com/2019/06/nvidia-sdk-manager-on-docker/ […]...
Windowsカーネルドライバを自作してWinDbgで解析してみる① - かえるのほんだな in Windowsデバイスドライバの基本動作を確認する (1)
[…] 参考:Windowsデバイスドライバの基本動作を確認する (1) - Fixstars Tech Blog /proc/cpuinfo ...
2021年版G検定チートシート | エビワークス in ニューラルネットの共通フォーマット対決! NNEF vs ONNX
[…] ONNX(オニキス):Open Neural Network Exchange formatフレームワーク間のモデル変換ツー�...
YOSHIFUJI Naoki in CUDAデバイスメモリもスマートポインタで管理したい
ありがとうございます。別に型にこだわる必要がないので、ユニバーサル参照を受けるよ...