このブログは、株式会社フィックスターズのエンジニアが、あらゆるテーマについて自由に書いているブログです。
Tensorコアを使ってみた
アルバイトの大友です。
TensorコアのWMMA APIを使っている人があまりいなかったため、6月中はインターンとして、7月からはアルバイトとしてその使い方や性能を調べていました。
この記事はその成果をまとめたものです。
Tensorコアを使うことでFP16のSIMD計算(f16x2)に比べ密行列積を5倍程度高速化できました。
Tensorコアとは
NVIDIA Voltaアーキテクチャから採用されたTensorコアは2つの$4 \times 4$のFP16行列の積を1サイクルで計算し、その累積和をFP16/FP32で取ることができる計算ユニットです。
cuBLAS, cuDNNなどのライブラリではCUDA 9からTensorコアを利用できます。
WMMA APIを用いた行列積計算
CUDA 9ではWMMA (Warp Matrix Multiply Accumulate) と呼ばれるTensorコアを使用してGEMM計算を行うためのC++ APIが用意されています。
このAPIでは$16 \times 16$など決められた大きさの行列をfragmentと呼ばれる構造体にスレッドごとに分割し、1ワープ(32スレッド)が協調してその行列積を計算します。
行列計算の流れ
行列$A,B,C \in R^{16 \times 16}$に対し$C \Leftarrow A \times B$を計算する流れは次のようになります。

- 各スレッドがメモリから$A$,$B$それぞれの一部をfragmentとして読み込む
- 各スレッドのfragmentを用いて行列積を計算 (計算結果$C$は同じくfragmentとして各スレッドが一部ずつ保持)
- 各スレッドがCのfragmentをメモリに書き込む
WMMA APIを使用したプログラム
$16 \times 16$の2行列$A,B$の積$C$を計算するCUDAのカーネル関数は次のように書けます。(CUDA 9.2.148)
__global__ void matmal_16x16(const half* const a_ptr,const half* const b_ptr,half* const c_ptr){
// A,B,Cのfragment
nvcuda::wmma::fragment<nvcuda::wmma::matrix_a, 16, 16, 16, half, nvcuda::wmma::col_major> a_frag;
nvcuda::wmma::fragment<nvcuda::wmma::matrix_b, 16, 16, 16, half, nvcuda::wmma::col_major> b_frag;
nvcuda::wmma::fragment<nvcuda::wmma::accumulator, 16, 16, 16, half> c_frag;
// Cのfragmentを0で初期化
nvcuda::wmma::fill_fragment(c_frag, __float2half(.0f));
// A,Bをメモリからfragmentに読み込み
nvcuda::wmma::load_matrix_sync(a_frag, a_ptr, 16);
nvcuda::wmma::load_matrix_sync(b_frag, b_ptr, 16);
// C ← A x B + C
nvcuda::wmma::mma_sync(c_frag, a_frag, b_frag, c_frag);
// Cのfragmentの中身をメモリに書き出し
nvcuda::wmma::store_matrix_sync(c_ptr, c_frag, 16, nvcuda::wmma::mem_col_major);
}このAPIでは1ワープで$16 \times 16$の行列の積を計算するため、カーネル関数は次のように呼び出します。
constexpr unsigned int warpSize = 32;
matmal_16x16<<<1,warpSize>>>(dA, dB, dC);nvcuda::wmma::fragment構造体
各スレッドが保持するfragmentは
template<typename Use, int m, int n, int k, typename T, typename Layout=void> class fragment;と定義されており、それぞれのテンプレート引数は次のような役割を担っています。
Use: GEMM計算 $D \Leftarrow A \times B + C$ の$A, B, C, D$どの行列のfragmentか- $A$の場合
nvcuda::wmma::matrix_a - $B$の場合
nvcuda::wmma::matrix_b - $C, D$の場合
nvcuda::wmma::accumulator
- $A$の場合
m,n,k: Tensorコアで計算する行列積の行列の大きさ
ただし、(m,n,k)は (16, 16, 16), (32, 8, 16), (8, 32, 16)のいずれか- $A$ : $m \times k$
- $B$ : $k \times n$
- $C, D$ : $m \times n$
T: fragmentの型- $A, B$ : half
- $C, D$ : half / float
Layout: 列優先か行優先か- 列優先 :
nvcuda::wmma::col_major - 行優先 :
nvcuda::wmma::row_major
- 列優先 :
メンバ変数
x: fragmentの要素配列num_elements: fragmentの要素数
nvcuda::wmma::fill_fragment関数
void fill_fragment(fragment<...> &a, const T& v);nvcuda::wmma::fragment aの全要素にvを代入
nvcuda::wmma::load_matrix_sync関数
void load_matrix_sync(fragment<...> &a, const T* mptr, unsigned ldm);
void load_matrix_sync(fragment<...> &a, const T* mptr, unsigned ldm, layout_t layout);
fragmentをメモリから読み込む
引数
a: 読み込み先fragmentmptr: 読み込み元ポインタldm: 行列全体のLeading dimensionlayout: 列優先の場合はnvcuda::wmma::mem_col_major, 行優先の場合はnvcuda::wmma::mem_row_major
制約
mptrが128-bit境界である必要あり (Alignment制約)ldmが16 bytesの倍数である必要あり (halfでは8, floatでは4) (Leading dimension制約)
nvcuda::wmma::store_matrix_sync関数
void store_matrix_sync(T* mptr, const fragment<...> &a, unsigned ldm, layout_t layout);fragmentをメモリに書き出す
引数
mptr: 書き出し先ポインタa: 書き出し元fragment (nvcuda::wmma::accumulatorのみ)ldm: 書き出し先行列のLeading dimensionlayout: 列優先の場合はnvcuda::wmma::mem_col_major, 行優先の場合はnvcuda::wmma::mem_row_major
制約
nvcuda::wmma::load_matrix_sync と同様の制約と未定義動作あり
nvcuda::wmma::mma_sync関数
void mma_sync(fragment<...> &d, const fragment<...> &a, const fragment<...> &b, const fragment<...> &c, bool satf=false);Tensorコアを用いたGEMM計算
引数
d, a, b, c: GEMM計算 $d \Leftarrow a \times b + c$ の各fragmentsatf: fragmentの要素が+-Infinity, NaNとなった場合に有限値に修正するか否か
任意の大きさの行列積計算
WMMA APIでは決められた大きさの行列積しか計算できませんが、行列積を分解して考えることで任意の大きさの行列積を計算することができます。
行列$A,B$の積$C$を計算する流れは次のようになります。

- 行列$A,B,C$を$16 \times 16$行列のブロック$A_{i,j},B_{i,j},C_{i,j}$に分割する。(端数部分は0埋め)
- 上図では$C_{1,1} = A_{1,0} \times B_{0,1} + A_{1,1} \times B_{1,1}$と計算できる。
このように$C_{i,j} = \sum_k A_{i,k} \times B_{k,j}$と計算することができる。
$A_{i,k} \times B_{k,j}$は$16 \times 16$の2行列の積のため、Tensorコアを用いて計算する。 - 2を$C$のすべてのブロックに対して行う。
WMMA APIを使用するにあたって
上述したとおり、nvcuda::wmma::load_matrix_sync関数とnvcuda::wmma::store_matrix_sync関数にはメモリのAlignment制約とLeading dimension制約があり、
Globalメモリにある任意の大きさの行列のGEMM計算を行うにはこの制約に対応しなければなりません。
そこでSharedメモリを用いることで対応します。

- fragmentとして読み込むGlobalメモリの領域をSharedメモリにコピー
- コピーしたSharedメモリから
nvcuda::wmma::load_matrix_sync関数でfragmentに読み込み nvcuda::wmma::mma_sync関数でGEMM計算- 計算結果のfragmentを
nvcuda::wmma::store_matrix_sync関数でSharedメモリに書き出し - 書き出したSharedメモリからGlobalメモリに書き出し
注意点
SharedメモリであればAlignment制約が満たされるわけではないので、必要ならば__align__([n byte])で境界を指定しなければならない。
性能調査
実験方法
- 行列$A,B,C \in \mathrm{half}^{N \times N}$に対し$C = A \times B$を計算
- Tensorコアを使用した場合としなかった場合(f16x2を用いた場合)で計算速度を比較
- それぞれ5回計算を行う
- 実験コードはtensorcore/matmul_evalにあります
実験環境
- CPU : Intel Core i9-7900X
- GPU : NVIDIA Titan V
- RAM : 64GB
- OS : Ubuntu 16.04
実験結果


Tensorコアを使用した場合、使用しなかった場合に比べて$N \geq 512$で5倍程度高速化されました。
nvcuda::wmma::fragment構造体の調査
行列がどのようにfragmentとしてワープ内で保持されているのかをprintfですべて標準出力して調査しました。
nvcuda::wmma::matrix_a, nvcuda::wmma::matrix_bの場合
行列$M \in \mathrm{half}^{16 \times 16}$を(m, n, k) = (16, 16, 16),nvcuda::wmma::col_majorなnvcuda::wmma::matrix_a,nvcuda::wmma::matrix_bそれぞれのfragmentにloadする場合を考えます。
$M$を$M_{i,j} \in \mathrm{half}^{4 \times 4}$のブロックに分割し
\[
\left(\begin{matrix}
M_{0,0} & M_{0,1} & M_{0,2} & M_{0,3} \\
M_{1,0} & M_{1,1} & M_{1,2} & M_{1,3} \\
M_{2,0} & M_{2,1} & M_{2,2} & M_{2,3} \\
M_{3,0} & M_{3,1} & M_{3,2} & M_{3,3}
\end{matrix}\right)
\]
と表すとthreadIdx.x$ = i$の
nvcuda::wmma::matrix_aのfragmentは\[
\left(\begin{matrix}
M^T_{0,0} & M^T_{1,0} & M^T_{2,0} & M^T_{3,0} \\
M^T_{0,0} & M^T_{1,0} & M^T_{2,0} & M^T_{3,0} \\
M^T_{0,2} & M^T_{1,2} & M^T_{2,2} & M^T_{3,2} \\
M^T_{0,2} & M^T_{1,2} & M^T_{2,2} & M^T_{3,2} \\
M^T_{0,1} & M^T_{1,1} & M^T_{2,1} & M^T_{3,1} \\
M^T_{0,1} & M^T_{1,1} & M^T_{2,1} & M^T_{3,1} \\
M^T_{0,3} & M^T_{1,3} & M^T_{2,3} & M^T_{3,3} \\
M^T_{0,3} & M^T_{1,3} & M^T_{2,3} & M^T_{3,3}
\end{matrix}\right)
\]nvcuda::wmma::matrix_bのfragmentは\[
\left(\begin{matrix}
M^T_{0,0} & M^T_{0,1} & M^T_{0,2} & M^T_{0,3} \\
M^T_{2,0} & M^T_{2,1} & M^T_{2,2} & M^T_{2,3} \\
M^T_{0,0} & M^T_{0,1} & M^T_{0,2} & M^T_{0,3} \\
M^T_{2,0} & M^T_{2,1} & M^T_{2,2} & M^T_{2,3} \\
M^T_{1,0} & M^T_{1,1} & M^T_{1,2} & M^T_{1,3} \\
M^T_{3,0} & M^T_{3,1} & M^T_{3,2} & M^T_{3,3} \\
M^T_{1,0} & M^T_{1,1} & M^T_{1,2} & M^T_{1,3} \\
M^T_{3,0} & M^T_{3,1} & M^T_{3,2} & M^T_{3,3}
\end{matrix}\right)
\]
で表される行列の$i+1$行目となります。
これを可視化すると
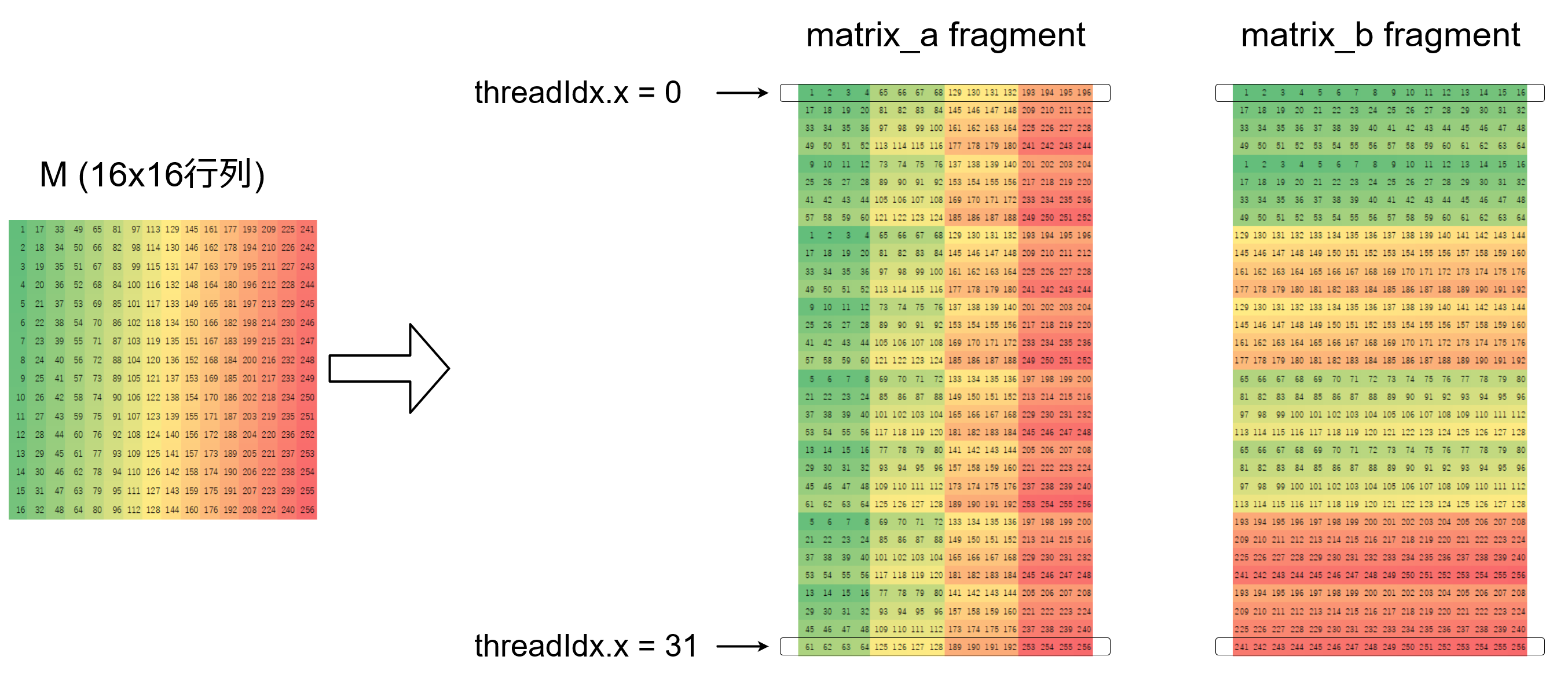
となります。
nvcuda::wmma::accumulatorの場合
行列$M \in \mathrm{half/float}^{16 \times 16}$は(m, n, k) = (16, 16, 16),nvcuda::wmma::col_majorなnvcuda::wmma::accumulatorのfragmentでは
$M$を$M_{i,j} \in \mathrm{half/float}^{4 \times 1}$のブロックに分割し
\left(\begin{matrix}
M_{0,0} & M_{0,1} & M_{0,2} & M_{0,3} & M_{0,4} & M_{0,5} & M_{0,6} & M_{0,7} & M_{0,8} & M_{0,9} & M_{0,10} & M_{0,11} & M_{0,12} & M_{0,13} & M_{0,14} & M_{0,15} \\
M_{1,0} & M_{1,1} & M_{1,2} & M_{1,3} & M_{1,4} & M_{1,5} & M_{1,6} & M_{1,7} & M_{1,8} & M_{1,9} & M_{1,10} & M_{1,11} & M_{1,12} & M_{1,13} & M_{1,14} & M_{1,15} \\
M_{2,0} & M_{2,1} & M_{2,2} & M_{2,3} & M_{2,4} & M_{2,5} & M_{2,6} & M_{2,7} & M_{2,8} & M_{2,9} & M_{2,10} & M_{2,11} & M_{2,12} & M_{2,13} & M_{2,14} & M_{2,15} \\
M_{3,0} & M_{3,1} & M_{3,2} & M_{3,3} & M_{3,4} & M_{3,5} & M_{3,6} & M_{3,7} & M_{3,8} & M_{3,9} & M_{3,10} & M_{3,11} & M_{3,12} & M_{3,13} & M_{3,14} & M_{3,15}
\end{matrix}\right)
\]
と表すとthreadIdx.x$ = i$では
\[
\left(\begin{matrix}
M_{0,0} & M_{0,1} & M_{0,2} & M_{0,3} & M_{0,4} & M_{0,5} & M_{0,6} & M_{0,7} \\
M_{2,0} & M_{2,1} & M_{2,2} & M_{2,3} & M_{2,4} & M_{2,5} & M_{2,6} & M_{2,7} \\
M_{0,8} & M_{0,9} & M_{0,10} & M_{0,11} & M_{0,12} & M_{0,13} & M_{0,14} & M_{0,15} \\
M_{2,8} & M_{2,9} & M_{2,10} & M_{2,11} & M_{2,12} & M_{2,13} & M_{2,14} & M_{2,15} \\
M_{1,0} & M_{1,1} & M_{1,2} & M_{1,3} & M_{1,4} & M_{1,5} & M_{1,6} & M_{1,7} \\
M_{3,0} & M_{3,1} & M_{3,2} & M_{3,3} & M_{3,4} & M_{3,5} & M_{3,6} & M_{3,7} \\
M_{1,8} & M_{1,9} & M_{1,10} & M_{1,11} & M_{1,12} & M_{1,13} & M_{1,14} & M_{1,15} \\
M_{3,8} & M_{3,9} & M_{3,10} & M_{3,11} & M_{3,12} & M_{3,13} & M_{3,14} & M_{3,15}
\end{matrix}\right)
\]
で表される行列の$i+1$行目となります。
これを可視化すると

となります。
行優先の場合
Globalメモリに行列$A,B$が行優先で置かれている場合、単純にfragmentに読み込む際に転置して読み込んでいるわけではありません。
行優先か列優先かでfragmentの中身が異なるため、nvcuda::wmma::mma_sync関数に対応するPTX命令であるwmma.load命令は
wmma.mma.sync.alayout.blayout.shape.dtype.ctype{.satfinite} d, a, b, c;
.alayout = {.row, .col};
.blayout = {.row, .col};
.shape = {.m16n16k16, .m8n32k16, .m32n8k16};
.ctype = {.f16, .f32};
.dtype = {.f16, .f32};という構造となっており(3)、fragment a,bが行優先か列優先かを指定する必要があります。
$C,D$に関しては行優先か列優先かを指定する必要はなく、実際列優先か行優先かでfragmentに差は見られませんでした。
nvcuda::wmma::load_matrix_syncの調査
Warp内の各スレッドでのnvcuda::wmma::fragment構造体の中身がわかったので、nvcuda::wmma::load_matrix_sync関数を使わずに自前でfragmentを読み込んだ場合と速度を比較しました。
- 行列$M \in \mathrm{half}^{16 \times 16}$を
nvcuda::wmma::matrix_aとして読み込むだけのカーネルを実行 - カーネル内で$2^{30}$回Globalメモリから読み込みを実行
- nvprofでカーネルの実行時間を測定
- 実験コードはtensorcore/load_evalにあります
結果
| 関数 | 実行時間 |
load_matrix_sync 関数 |
91 us |
| 自作load関数 | 77670 us |
高速化を余り考えずに書いたと言え、自作load関数に比べてnvcuda::wmma::load_matrix_sync 関数が850倍程度高速という結果になりました。考察NVIDIA Visual Profilerで実行されたSASSコードを見たところ、nvcuda::wmma::load_matrix_sync関数でも汎用的なメモリ読み込み命令であるLDG命令が使われているようでした。
読み込みアドレスの計算と実際の読み込み命令の実行順などが工夫されているのかもしれません。
まとめ
TensorコアはWMMA APIを用いることで簡潔に利用することができました。
WMMA APIのload_matrix_sync,store_matrix_sync,mma_sync関数はほとんど単純にPTXの命令に置き換えられるだけなためレイヤーは低く、使用の自由度は高いと考えられます。
性能面ではTensorコアを使用することでf16x2を使用した場合に比べFP16密行列積を高速に計算できることが確認できました。
謝辞
吉藤さんにはインターン及びアルバイトでCUDAやコードの書き方について指導していただきました。
ありがとうございました。
参考文献
- NVIDIA Developer Blog – Programming Tensor Cores in CUDA 9
- CUDA Toolkit Document – CUDA C Programming Guide (Warp matrix functions)
- CUDA Toolkit Document – Parallel Thread Execution ISA (Warp Level Matrix Multiply-Accumulate Instructions)
- GitHub – parallel-forall/code-samples
- VOLTA AND TURING: ARCHITECTURE AND PERFORMANCE OPTIMIZATION – Akira Naruse, Developer Technology, 2018//14
利用許諾・ライセンス

本記事に含まれるあらゆる文章および画像は、クリエイティブ・コモンズ 表示-継承 4.0 国際(CC-BY-SA 4.0 International)ライセンス(帰属表示/attribution: Fixstars Corporation)の下で利用可能です。

Tags
About Author
OtomoHiroyuki
Leave a Comment
Tags
Favorite Post

 2017年8月22日
2017年8月22日 2017年10月31日
2017年10月31日
Archives
- 2024年2月
- 2024年1月
- 2023年12月
- 2023年6月
- 2023年5月
- 2023年4月
- 2023年2月
- 2023年1月
- 2022年12月
- 2022年10月
- 2021年11月
- 2021年9月
- 2021年6月
- 2021年3月
- 2021年2月
- 2020年12月
- 2020年10月
- 2020年7月
- 2020年6月
- 2020年5月
- 2020年4月
- 2020年3月
- 2020年2月
- 2020年1月
- 2019年12月
- 2019年11月
- 2019年10月
- 2019年9月
- 2019年8月
- 2019年6月
- 2019年4月
- 2019年3月
- 2019年2月
- 2019年1月
- 2018年12月
- 2018年11月
- 2018年10月
- 2018年8月
- 2018年6月
- 2018年5月
- 2018年4月
- 2018年3月
- 2018年2月
- 2017年12月
- 2017年11月
- 2017年10月
- 2017年9月
- 2017年8月
- 2017年7月
- 2017年6月
- 2017年5月
- 2017年3月
- 2016年12月
- 2016年11月
- 2016年8月
- 2016年7月
- 2016年3月
- 2016年2月
- 2016年1月
- 2015年12月
- 2015年11月
- 2015年10月
- 2015年8月
- 2015年6月
- 2015年3月
- 2015年2月
- 2015年1月
- 2014年12月
- 2014年11月
コンピュータビジョンセミナーvol.2 開催のお知らせ - ニュース一覧 - 株式会社フィックスターズ in Realizing Self-Driving Cars with General-Purpose Processors 日本語版
[…] バージョンアップに伴い、オンラインセミナーを開催します。 本セミナーでは、�...
【Docker】NVIDIA SDK Managerでエラー無く環境構築する【Jetson】 | マサキノート in NVIDIA SDK Manager on Dockerで快適なJetsonライフ
[…] 参考:https://proc-cpuinfo.fixstars.com/2019/06/nvidia-sdk-manager-on-docker/ […]...
Windowsカーネルドライバを自作してWinDbgで解析してみる① - かえるのほんだな in Windowsデバイスドライバの基本動作を確認する (1)
[…] 参考:Windowsデバイスドライバの基本動作を確認する (1) - Fixstars Tech Blog /proc/cpuinfo ...
2021年版G検定チートシート | エビワークス in ニューラルネットの共通フォーマット対決! NNEF vs ONNX
[…] ONNX(オニキス):Open Neural Network Exchange formatフレームワーク間のモデル変換ツー�...
YOSHIFUJI Naoki in CUDAデバイスメモリもスマートポインタで管理したい
ありがとうございます。別に型にこだわる必要がないので、ユニバーサル参照を受けるよ...